本文最后由 Demo Marco 更新于 2025-02-22. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】
自然语言处理 (NLP)是语言学、计算机科学、人工智能和信息工程的一个子领域,涉及计算机与人类(自然)语言之间的交互,特别是如何编程计算机来处理和分析大量自然语言数据。
听起来很有趣?如果我们告诉你我们让一个名为 GPT-3 的算法编写了整个段落,并且它在第一次尝试时就做到了,你会怎么说?我们不是开玩笑!看看这个……
GPT-3 的实际应用
非常神奇,对吧?!那么,回到 NLP。它使计算机能够以文本或语音数据的形式处理人类语言并“理解”其全部含义,包括说话者或作者的意图和情感。NLP 作为一个领域,是过去十年中一些最令人兴奋的 AI 发现和实现的场所。在过去几年中,该领域最令人兴奋和最丰富的趋势是大型语言模型,GPT-3 模型属于此类。
GPT-3 被一些人视为探索通用人工智能的第一步。它比任何其他人工智能模型都更受关注。它能够以接近人类的效率和准确性执行一系列通用任务,其灵活性使它如此令人兴奋。它以 API 的形式发布,旨在让数据科学家、开发人员以及全球各行各业的人们前所未有地访问世界上最强大的语言模型之一。
该模型由人工智能研发前沿公司 OpenAI 创建。自 2020 年 7 月首次发布以来,世界各地的开发人员已经发现了数百种令人兴奋的 GPT-3 应用,这些应用有可能提升我们的交流、学习和娱乐方式。它能够轻松解决一般的基于语言的任务,并且可以在不同的文本样式和目的之间自由移动。
在 GPT-3 之前,语言模型被设计用于执行一项特定的 NLP 任务,例如文本生成、摘要或分类。GPT-3 是自然语言处理历史上第一个可以在一系列 NLP 任务上表现同样出色的通用语言模型。GPT-3 代表“生成式预训练 Transformer”,它是 OpenAI 对该模型的第三次迭代。让我们分解一下这三个术语:
- 生成式:生成模型是一种用于生成新数据点的统计模型。这些模型学习数据集中变量之间的潜在关系,以生成与数据集中变量类似的新数据点。
- 预训练:预训练模型是已经在大型数据集上训练过的模型。这使得它们可以用于难以从头开始训练模型的任务。预训练模型可能不是 100% 准确,但它可以让你免于重新设计轮子,节省时间并提高性能。
- Transformer: Transformer 模型是 2017 年发明的著名人工神经网络。它是一种深度学习模型,旨在处理序列数据(例如文本)。Transformer 模型通常用于机器翻译和文本分类等任务。
什么是大型语言模型?
近年来,人们对自然语言处理 (NLP) 领域的大型语言模型 (LLM) 的构建产生了浓厚的兴趣。LLM 经过大量文本训练,可用于各种基于语言的任务,包括文本生成、机器翻译和问答。
语言建模是利用概率来理解给定语言中句子是如何组合在一起的任务。简单的语言模型可以查看一个单词,并根据对现有文本序列的统计分析,预测最有可能跟在它后面的下一个单词(或多个单词)。例如,句子“我喜欢遛我的……”更有可能以单词“狗”而不是单词“冰箱”结尾。使用大量数据训练语言模型非常重要,这样才能使其准确预测单词序列。
LLM 可以被认为是统计预测机器,其中输入的是文本,输出的是预测。您可能对手机上的自动完成功能很熟悉。例如,如果您输入“好”,自动完成功能可能会给出“早上好”或“运气好”等建议。自动完成等自然语言处理应用程序严重依赖语言模型。
虽然语言模型已经存在了很长时间,但直到最近才取得如此大的成功。这归因于许多因素,包括大量训练数据的可用性、更好的训练算法的开发以及使用 GPU 来加速训练。有了更多的数据,模型可以更多地了解单词与使用它们的上下文之间的关系。这使模型能够更好地理解文本的含义并生成更准确的预测。
LLM 的成功在于它能够捕捉文本中单词之间的依赖关系。例如,在句子“The cat sat on the mat”中,“cat”一词依赖于“the”,而“mat”一词依赖于“on”。在大型语言模型中,这些依赖关系被捕获在模型的参数中。虽然大型语言模型已经变得更加先进,但它们使用的参数数量也呈爆炸式增长,正如您在 Microsoft Research 发布的下图中看到的那样。
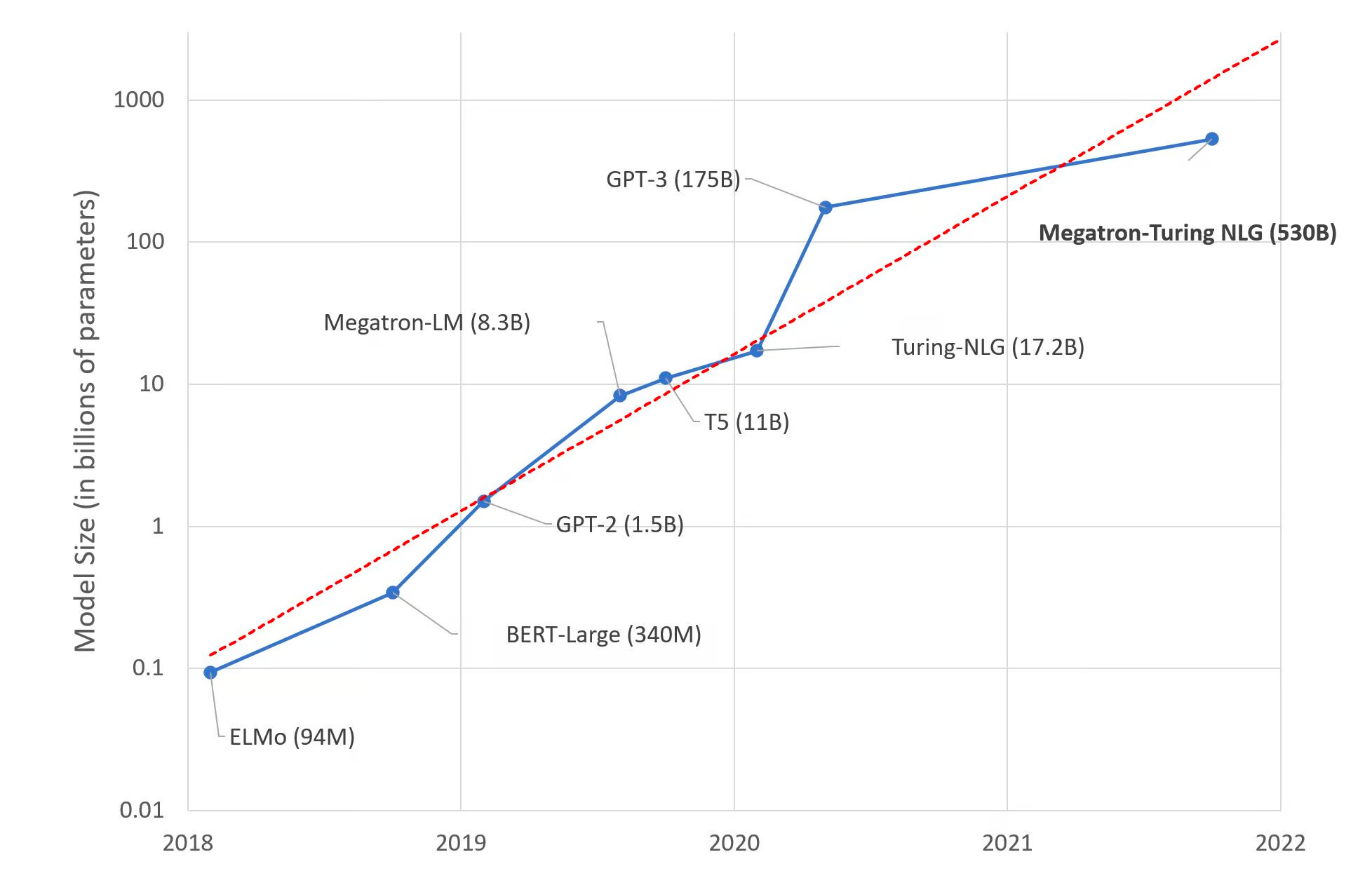
最先进的 NLP 模型的规模随时间变化的对数趋势来源: 2021 年 10 月 11 日
微软研究院博客文章
大型语言模型的预训练需要大量计算,这需要大量能源。这些模型的需求不断增长,需要越来越多的计算资源。这会带来巨大的环境成本,例如不可持续的能源使用和碳排放。
在 2019 年的一项研究中,马萨诸塞大学的研究人员估计,训练一个大型深度学习模型会产生 626,000 磅导致地球变暖的二氧化碳,相当于五辆汽车一生的排放量。随着模型变得越来越大,它们的计算需求超过了硬件效率的提高。2021 年的一项研究估计,GPT-3 的训练产生了大约 552 公吨的二氧化碳。这大约相当于 120 辆汽车一年的行驶产生的量。
然而,2019 年的《绿色人工智能》论文指出,“公开发布预训练模型的趋势是一种绿色成功”,作者鼓励组织“继续发布他们的模型,以节省其他人重新训练它们的成本”。OpenAI 等发布预训练大型语言模型的公司正在不断研究和开发减少训练模型的碳足迹的技术。
GPT-3 在执行各种 NLP 任务时非常准确,因为它所训练的数据集非常庞大,其庞大的架构由 1750 亿个参数组成,使其能够理解数据中的逻辑关系。GPT-3 在五个大型数据集的文本语料库上进行了预训练,这些数据集包括 Common Crawl、WebText2、Books1、Books2 和 Wikipedia。这个语料库总共包含近一万亿个单词,这使得 GPT-3 能够在零样本设置或不提供任何示例数据的情况下成功执行大量 NLP 任务。
在下一节中,我们将探索 transformers,这是一种著名的架构,它使模型席卷了语言建模领域,并改变了 NLP 领域的可能性的定义。
什么是变压器模型?
Transformer 是一种神经网络架构,特别适合语言建模任务。它最早是在 2017 年的论文《注意力就是你所需要的一切》中提出的。该论文将 Transformer 解释为一种神经网络架构,旨在高效执行序列到序列任务,同时轻松处理长距离依赖关系。Transformer 模型已迅速成为自然语言处理任务的首选架构,目前在 NLP 领域占据主导地位。
序列到序列是一种机制,是转换器模型的支柱。该架构也称为 Seq2Seq,可将给定的元素序列(例如句子中的单词)转换为另一个序列(例如不同语言的句子),这使得该架构特别适合翻译任务。Google Translate于 2016 年底开始在生产中使用类似的架构。

资料来源: Jay Alammar 的博客文章“图解变压器”
Seq2Seq 模型由两部分组成:编码器和解码器。编码器和解码器可以看作只能说两种语言的人工翻译。他们各自都有不同的母语;例如,我们假设编码器是母语为中文的人,而解码器是母语为英语的人。他们两人还有一种共同的第二语言;假设是日语。要将中文翻译成英文,编码器会将中文句子转换成日语。该日语句子(称为上下文)被传递给解码器。由于解码器理解日语并能够阅读该语言,因此它现在可以将日语翻译成英语。
Transformer 架构的另一个关键组件是一种称为“注意力”的机制。它是一种模仿认知注意力的技术。认知注意力是一种反映我们的大脑如何关注句子重要部分的技术,帮助我们理解其整体含义。例如,当你阅读这句话时,你总是专注于你正在阅读的单词,但同时,你的记忆会保留句子中最重要的关键词以提供上下文。
注意机制逐个查看输入序列,并在每一步中确定序列中的哪些其他部分是重要的。这有助于 Transformer 过滤掉噪音,并通过连接本身不带有任何明显指向彼此的标记的相关单词来关注相关内容。
Transformer 模型受益于更大的架构和更大量的数据。这使得它们比任何其他类型的神经网络更善于理解句子中单词的上下文,这也解释了它们对机器学习领域的巨大影响。随着它们的不断发展,它们在未来几年可能会产生更大的影响,您只需几个简单的步骤就可以开始使用 LLM 进行实验。
GPT-3 入门
浏览 OpenAI API
尽管 GPT-3 可以说是世界上最复杂、最精密的语言模型之一,但它的功能可以通过简单的“文本输入文本输出”用户界面访问。开始使用 GPT-3 需要做的第一件事就是访问 OpenAI API。您可以在此处申请,几分钟后,您的帐户就会设置完毕。
一旦您可以访问 OpenAI 开发者帐户,我们将查看 Playground,这是一个基于 Web 的私有沙盒环境,可让您试验 API 并了解其不同组件如何协同工作。
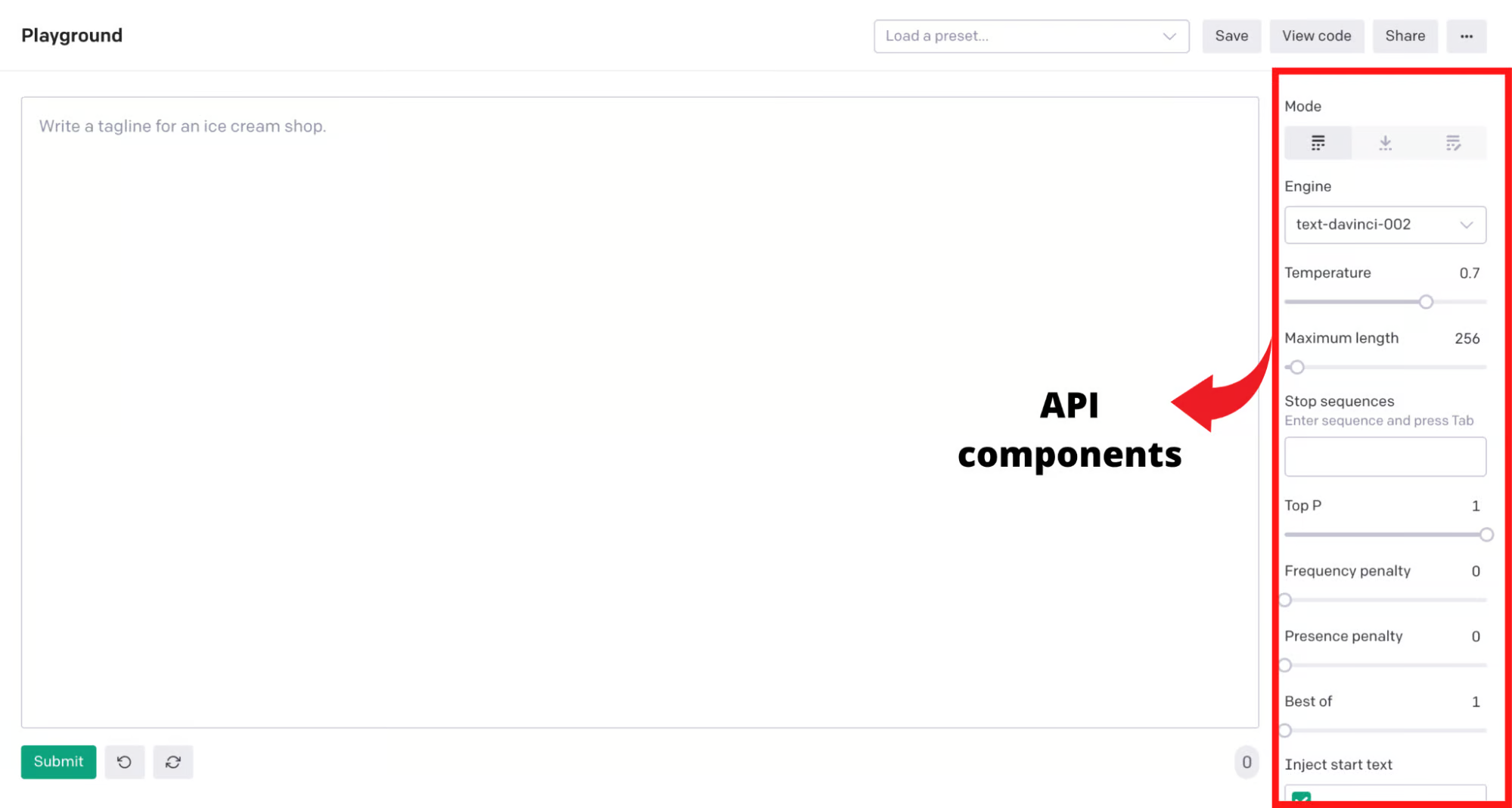
OpenAI API 的组件
以下是不同 API 组件及其功能的概述:
- 执行引擎:它决定了用于执行的语言模型。选择正确的引擎是确定模型功能并进而获得正确输出的关键。
- 响应长度:响应长度限制了 API 在其完成时包含的文本量。由于 OpenAI 按每次 API 调用生成的文本长度收费,因此响应长度对于任何预算有限的人来说都是一个关键参数。响应长度越高,费用越高。
- 温度: 温度控制响应的随机性,表示为从 0 到 1 的范围。较低的温度值意味着 API 将使用模型看到的第一件事做出响应;较高的温度值意味着模型在给出结果之前会评估可能适合上下文的可能响应。
- Top P: Top P 控制模型在完成时应考虑多少个随机结果,如温度表盘所示,从而确定随机性的范围。Top P 的范围从 0 到 1。较低的值限制了创造力,而较高的值则扩大了其视野。
- 频率和存在惩罚: 频率惩罚通过“惩罚”来降低模型逐字重复同一句话的可能性。存在惩罚增加了谈论新话题的可能性。
- 最佳:此参数允许您指定在服务器端生成的完成数(n),并返回“n”个完成中的最佳值。
- 停止序列: 停止序列是一组字符,用于向 API 发出信号以停止生成完成。
- 注入开始和重新启动文本: 注入开始文本和注入重新启动文本参数允许您分别在完成的开始或结束处插入文本。
- 显示概率: 此选项可让您通过显示模型针对给定输入能够生成的标记的概率来调试文本提示。
OpenAI API 提供四种不同的执行引擎,它们在使用的参数数量、性能和价格方面有所不同。主要引擎按其功能和大小依次为 Ada(以 Ada Lovelace 命名)、Babbage(以 Charles Babbage 命名)、Curie(以 Madame Marie Curie 命名)和 Davinci(以 Leonardo da Vinci 命名)。
基于以上四个主要模型,OpenAI 推出了一系列改进的模型,称为 InstructGPT,它们更善于理解指令并按照指令生成所需的特定输出。你所要做的就是告诉模型你想要它做什么,它会尽力完成你的指令。向 GPT-3 模型提供指令的过程称为提示工程。
及时工程
GPT-3 的设计与任务无关。这意味着,只要有特定的训练提示,它就可以执行任意数量的任务。创建 AI 解决方案从来都不是一件容易的事,但有了 GPT-3,你所需要的只是一个用简单英语编写的合理训练提示。

资料来源:Andrej Karpathy于 2020 年 6 月 18 日发布的推文
创建 GPT-3 应用程序时,首先要考虑的是训练提示的设计和内容。提示设计是引导 GPT-3 模型给出有利且符合情境的响应的最重要过程。
提示是您提供给模型的文本输入,以便它生成您想要的输出。设计一个好的提示就是在文本输入中为模型提供足够的任务背景信息。GPT-3 查看输入并尝试用它认为最能完成输入的文本来响应。
从某种程度上来说,提示设计就像玩猜字谜游戏!
编写优质提示的秘诀在于了解 GPT-3 对世界的了解,以及如何让模型使用这些信息来生成有用的结果。在猜字谜游戏中,我们的目标是为玩家提供足够的信息,让他们利用自己的智慧找出正确的单词。同样,我们必须以训练提示的形式为 GPT-3 提供足够的背景信息,以便模型找出模式并执行任务。我们不想通过向模型提供过多信息来打断模型的自然智能流,但提供的信息太少也会导致结果不准确。
根据经验,在设计训练提示时,您应该努力从模型中获得零样本响应。如果这不可能,请继续使用几个示例,而不是为其提供整个语料库。训练提示设计的标准流程应如下所示:
零样本 → 少量样本 → 基于语料库的启动
如果模型在你的文本输入中看到字母“Q”和一个问题,它会尝试写出一个答案,但不一定是你期望的答案。如果没有足够的背景信息,它可能会假设你正在写一个问题和错误答案的列表。如果你想得到最好的答案,你需要让 GPT-3 知道要提供什么样的答案。
不需要要求 GPT-3 完成此输入:
Q:
A:其中我们第一次完成的是:
Q:
A:
Q:
A:通过使用这样的提示(或某种变体,取决于你希望模型生成什么类型的问题),你将大大改善问题的输出:
Write a few trivia questions.
Q:
A:我们第一次尝试就获得了以下完成:
What is the name of the longest river in Africa?
The Nile
What are the top 5 most spoken languages in the world?
Mandarin, Spanish, English, Hindi, Arabic上述简单的指令足以让 GPT-3 理解它需要给出更符合您所寻找内容的答案;在本例中,是几个琐事问题。您还可以使用“事实答案:”之类的短语代替“A:”来改善结果。
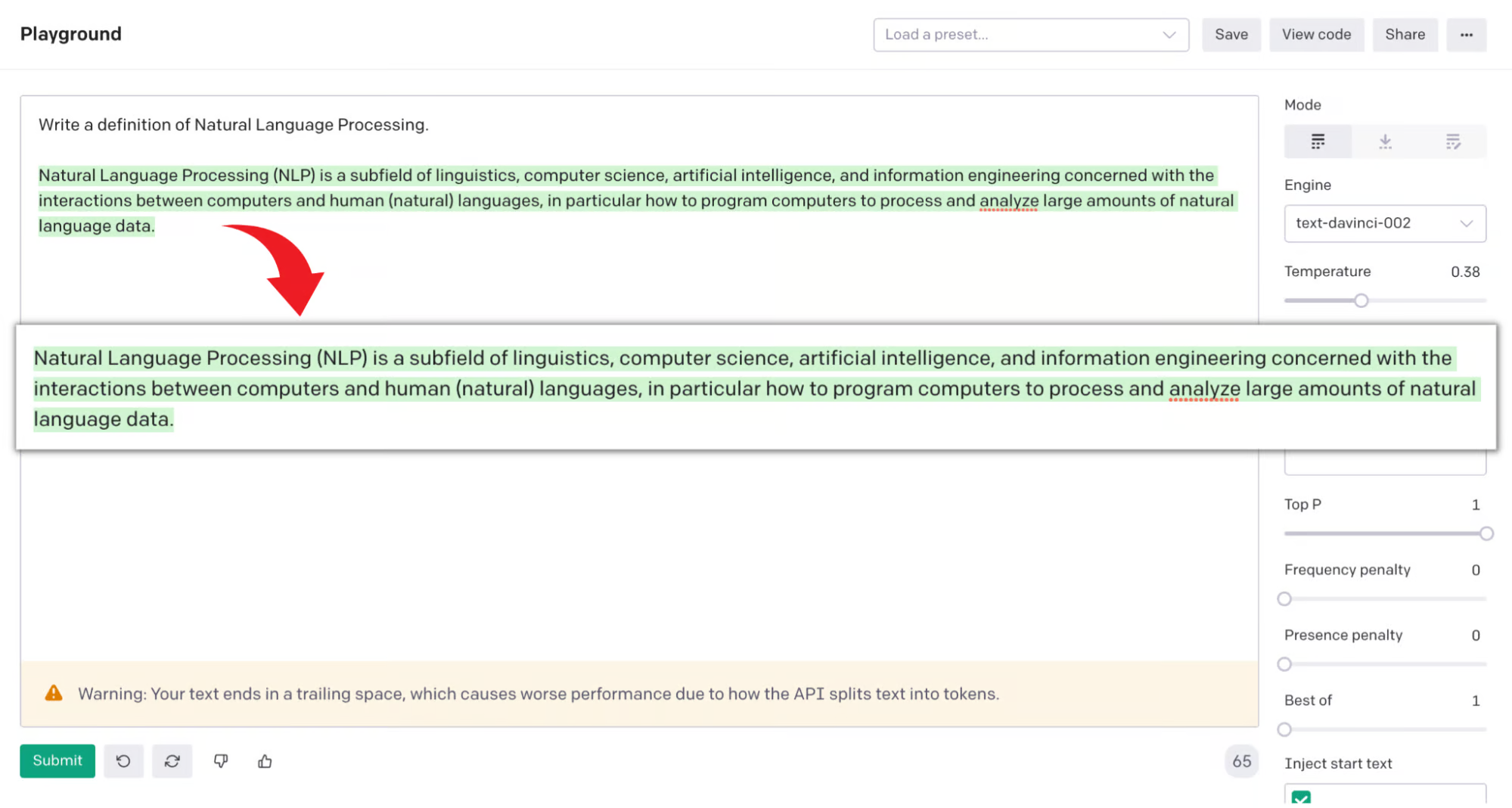
Write a few trivia questions.
Question:
Factual answer:对于这个输入我们得到了以下完成:
1. What is the world’s largest desert?
The Sahara desert.
2. What is the world’s deepest Ocean?
The Pacific Ocean.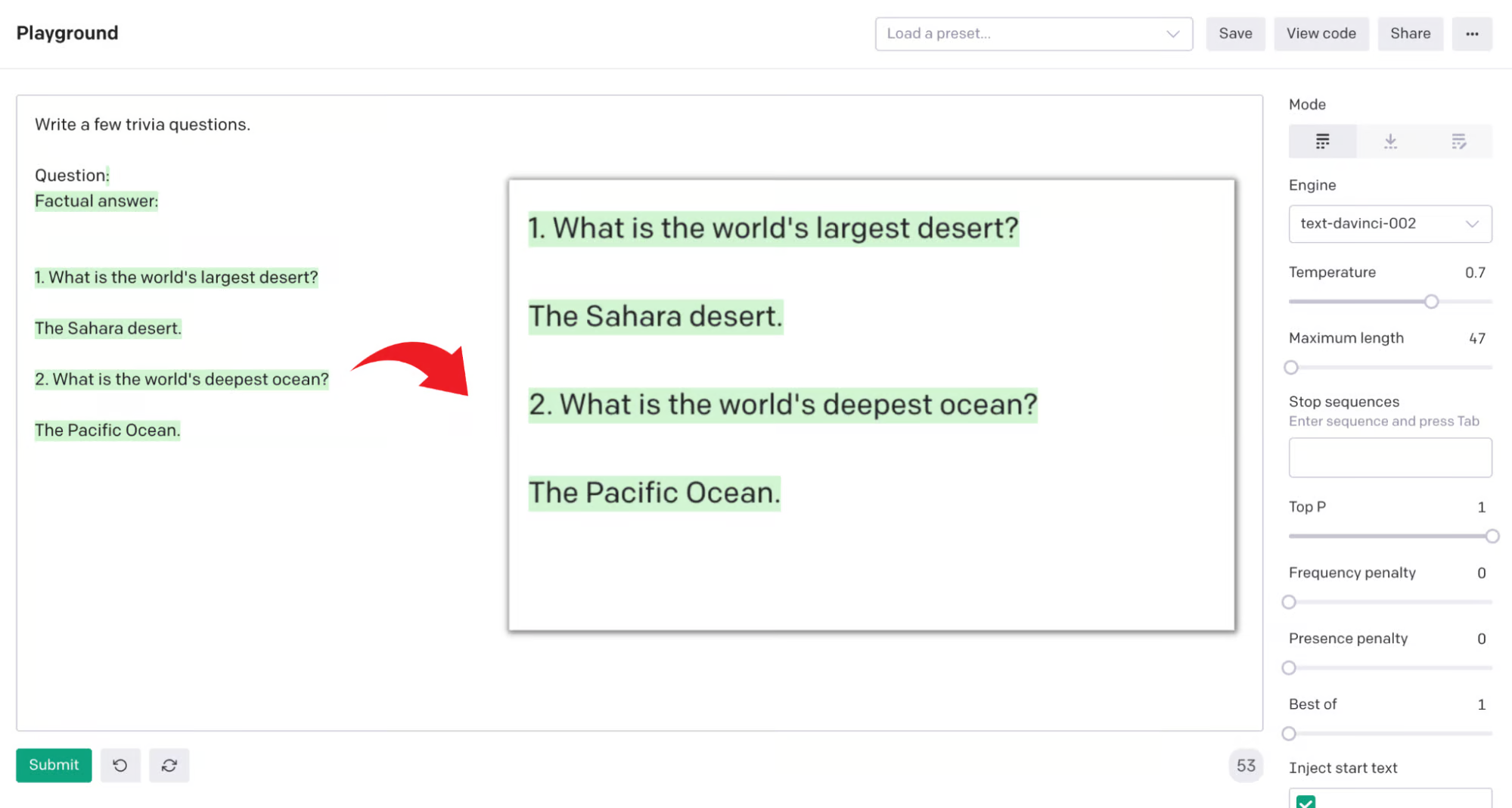
GPT-3 沙盒——使用 OpenAI API 和 Python
在本节中,我们将带您了解 GPT-3 沙盒,这是一个开源工具,只需几行 Python 代码即可将您的想法变成现实。我们将向您展示如何使用它以及如何针对您的特定应用程序对其进行自定义。此沙盒的目标是让您能够创建很酷的 Web 应用程序,无论您的技术背景如何。
按照此交互式视频系列,逐步了解如何创建和部署 GPT-3 应用程序。你将需要以下技术堆栈才能使用 GPT-3 沙盒:
- Python 3.7+
- IDE,例如 VS Code
通过在 IDE 中打开一个新终端并使用以下命令从此存储库克隆代码:
git clone https://github.com/Shubhamsaboo/kairos_gpt3创建和部署 Web 应用程序所需的一切都已包含在代码中。您只需调整几个文件即可针对特定用例自定义沙盒。现在,创建一个Python 虚拟环境即可开始使用。创建虚拟环境后,您可以使用以下命令安装所需的依赖项:
pip install -r requirements.txt现在,您可以开始自定义沙盒代码。您需要查看的第一个文件是training_data.py。打开该文件并将默认提示替换为要使用的训练提示。您可以使用 GPT-3 游乐场尝试不同的训练提示(有关自定义沙盒的更多信息,请参阅本书第2 章和以下视频)。
您现在可以调整 API 参数(Maximum tokens、Execution Engine、Temperature、、Top-p)。我们建议在 Playground 中针对给定的训练提示尝试不同的 API 参数值,以确定哪些值最适合您的用例。获得满意的结果后,您就可以更改文件中的值。Frequency PenaltyStop Sequencetraining_service.py
就这样!您的基于 GPT-3 的 Web 应用程序现已准备就绪。您可以使用以下命令在本地运行它:
streamlit run gpt_app.py您可以使用Streamlit 共享来部署应用程序并将其分享给更广泛的受众。请观看此视频,了解部署应用程序的完整步骤。
你能用 GPT-3 构建什么?
在 GPT-3 发布之前,大多数人与 AI 的互动仅限于某些特定任务,例如让 Alexa 播放您喜欢的歌曲或使用 Google 翻译以不同的语言进行交谈。随着 LLM 的发展,我们正在见证重大的范式转变。LLM 向我们展示了通过增加模型的大小,AI 应用程序可以执行类似于人类的创造性和复杂任务。
GPT-3 正在通过合适的技术激发创意企业家的想象力,为下一波创业公司提供动力。OpenAI 发布 API 后不久,创业界就充满了使用它来解决问题的公司。让我们通过查看一些在创意艺术、数据分析、聊天机器人、文案和开发者工具等领域以 GPT-3 为产品核心的表现最佳的初创公司来探索这个充满活力的生态系统。
1. GPT-3 的创意应用:Fable Studio
GPT-3 最令人兴奋的功能之一是讲故事。你可以给模型一个主题,并要求它在零样本设置下写一个故事。这些可能性让作家们拓展了想象力,创作出了非凡的作品。例如,由 Jennifer Tang 执导、Chinonyerem Odimba 和 Nina Segal 共同开发的戏剧《AI》描绘了在 GPT-3 的帮助下人类和计算机思维之间的独特合作。
Fable Studio 是一家利用该模型的创意讲故事能力的公司。他们将 Neil Gaiman 和 Dave McKean 的儿童读物《Wolves in the Walls》改编成一部获得艾美奖的 VR 电影体验。得益于 GPT-3 生成的对话,电影的主角露西可以与人进行自然对话。该公司相信,随着该模型的不断迭代,未来有可能开发出一个与最优秀的人类作家一样熟练和富有创造力的 AI 讲故事者。
2. GPT-3 的数据分析应用:可行
Viable是一款反馈汇总工具,可识别调查、服务台工单、实时聊天记录和客户评论中的主题、情绪和情感。然后,它会在几秒钟内提供结果摘要。例如,如果问“结账体验中哪些地方令我们的客户感到沮丧?” Viable 可能会回答:“客户对结账流程感到沮丧,因为加载时间太长。他们还希望有一种在结账时编辑地址并保存多种付款方式的方法。”
正如你可能对客户反馈专家所期望的那样,Viable 在软件生成的每个答案旁边都有赞成和反对按钮。他们在再训练中使用这些反馈。人类也是这个过程的一部分:Viable 有一个注释团队,其成员负责构建训练数据集,既用于内部模型,也用于 GPT-3 微调。他们使用该微调模型的当前迭代来生成输出,然后人类评估其质量。如果输出没有意义或不准确,他们会重写它。一旦他们有了满意的输出列表,他们就会将该列表反馈到训练数据集的下一次迭代中。
3. GPT-3 的聊天机器人应用:Quickchat
Emerson AI是 Quickchat 公司的聊天机器人角色,以其广泛的世界知识、对多种语言的支持以及进行对话的能力而闻名。Emerson AI 用于展示 GPT-3 驱动的聊天机器人的功能,并鼓励用户与 Quickchat 合作为他们的公司实现这样的角色。Quickchat 的产品是一种通用的对话式人工智能,可以谈论任何话题。客户可以通过添加特定于其产品的额外信息来定制聊天机器人。Quickchat 已经看到了各种应用,例如自动化客户支持和实现人工智能角色以帮助用户搜索公司内部知识库。
与典型的聊天机器人服务提供商不同,Quickchat 不会构建任何对话树或固定场景,也不需要教聊天机器人以给定的方式回答问题。相反,客户只需遵循一个简单的过程:复制粘贴包含您希望 AI 使用的所有信息的文本,然后单击重新训练按钮,这需要几秒钟来吸收知识,就是这样。现在,聊天机器人已经根据您的数据进行了训练,可以进行测试对话了。
4. GPT-3 的营销应用:Copysmith
GPT-3 最受欢迎的应用之一是即时生成创意内容。Copysmith就是这样一个内容生成平台。它使用GPT -3 生成提示,然后将其转化为电子商务企业的文案。GPT-3 似乎在营销领域大放异彩,它有助于以闪电般的速度生成、协作和发布优质内容。借助该模型,在线中小型企业可以编写更好的号召性用语和产品描述,并提升其营销水平,使其起步。
5. GPT-3 的编码应用:速记
OpenAI 社区大使 Bram Adams 创建了Stenography,这是一个使用 GPT-3 和 Codex 来自动化编写代码文档过程的程序。
Stenography 一经推出便大获成功,成为 ProductHunt 上排名第一的产品。Adams 认为文档是人们联系团队中的其他人、未来的自己,或者只是偶然发现 GitHub 上开发项目的感兴趣的人的一种方式。Stenography 的目标是让其他人能够理解项目。
要了解有关新兴 GPT-3 生态系统的更多信息,请查看我们即将出版的 O'Reilly 书籍的第 4 章(GPT-3 作为下一代初创企业的启动板)和第 5 章(适用于企业的 GPT-3)。
结论
- GPT-3 标志着人工智能历史上的一个重要里程碑。它也是未来将继续向前发展的更大的 LLM 趋势的一部分。提供 API 访问的革命性举措创造了新的模型即服务业务模式。
- GPT-3 的通用语言能力为打造创新产品打开了大门。它尤其擅长解决文本生成、文本摘要、分类和对话等任务。
- 有许多成功的公司主要或完全基于 GPT-3 建立。我们最喜欢的用例是创意故事讲述、数据分析、聊天机器人、营销文案和开发者工具。

