
本文最后由 Demo Marco 更新于 2025-02-08. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】
一、密钥和地址
比特币是基于密码学的,密码学是在计算机安全领域广泛应用的数学分支。密码学在希腊语中是“保密写作”的意思,但是密码学这门科学包含的不仅仅是“保密写作”(或可称之为加密)。密码学也可以被用来证明保密的知识,且不泄露其秘密本身(数字签名),或者用来证明数据的真实性(数字指纹)。这些类型的密码学证明对比特币来说是至关重要的数学工具,在比特币中被广泛使用。
具有讽刺意味的是,“加密”并不是比特币的重要部分,因为比特币的通信和交易数据并没有加密,也不需要通过加密来保护资金,比特币中最重要的部分是所有权的转移授权以及所有权的证明等工作。
简介
比特币的所有权是通过数字密钥、比特币地址和数字签名建立起来的。
数字密钥实际上并不存储在网络中,而是由用户创建,并且存储在一个叫作钱包的文件或者简单的数据库中。用户钱包中的数字密钥完全独立于比特币协议,可以由用户的钱包软件生成和管理,而无须参考区块链或接入互联网。密钥使比特币的许多有趣特性得以实现,包括去中心化的信任和控制、所有权认证和基于密码学验证的安全模型。
大多数比特币交易都需要一个有效的数字签名才能被存储到区块链上。只有有效的密钥才能产生有效的数字签名,因此任何人只要拥有密钥副本就拥有了对该账户的比特币控制权。用于支出资金的数字签名也被称为见证(witness),它是一个密码学术语。比特币交易中的见证数据证明了所用资金的真实所有权。
密钥是成对出现的,由私钥(秘密)和公钥组成。公钥类似我们的银行账号,而私钥就像控制账户的密码或支票上的签名。比特币的用户很少会直接看到这些数字密钥。大多数情况下,它们存储在钱包文件中并由比特币钱包软件管理。
在比特币交易的支付部分中,接收者的公钥由其数字指纹表示,称为比特币地址,就像支票上的收款人名称一样(即“收款方”)。一般情况下,比特币地址由一个公钥生成并对应于这个公钥。
然而,并非所有比特币地址都代表公钥,它们也可以代表其他受益者,如脚本。通过这种方式,比特币地址把收款方抽象起来了,使得交易的目的地变得灵活,就像支票一样。这个支付工具可支付到个人账户、公司账户、支付账单或支付现金。比特币地址是用户经常看到的密钥的唯一表示,因为这个地址就是他们需要告诉其他人的部分。
(1)公钥密码学和加密货币
公钥密码学是在20世纪70年代发明的,是计算机和信息安全的数学基础。
自从公钥密码学被发明以来,人们已经发现了一些合适的数学函数,如素数指数和椭圆曲线乘法。这些数学函数实际上都是不可逆的,这意味着它们很容易在一个方向上计算,但却不可能在相反的方向上被倒推。基于这些数学函数,密码学使得创建数字秘密和不可伪造的数字签名成为可能。
比特币正是使用椭圆曲线乘法作为其密码学的基础。
在比特币系统中,我们使用公钥密码学来创建一个控制访问比特币的密钥对。密钥对包含一个私钥和从它派生出来的一个唯一的公钥。公钥用于接收比特币,而私钥用于为比特币支付进行交易签名。
公钥和私钥之间存在一种数学关系,允许使用私钥在消息上生成签名。这个签名可以在不泄露私钥的情况下通过公钥进行验证。
支付比特币时,比特币的当前所有者需要在交易中展示其公钥和签名(每次交易的签名都不同,但均从同一个私钥创建)。比特币网络中的所有人都可以对所提交的公钥和签名进行验证,来确认该交易是否有效,即确认支付者在转账时对所交易的比特币拥有所有权。
在大多数钱包实现中,为了方便起见,私钥和公钥被一起存储为密钥对。但是,可以从私钥计算公钥,所以只存储私钥也是可以的。
(2)私钥和公钥
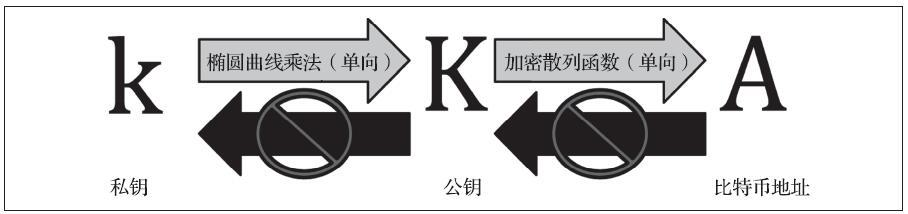
一个比特币钱包中包含一组密钥对,每个密钥对包含一个私钥和一个公钥。私钥(k)是一个数字,通常是随机选择的。基于私钥可以使用椭圆曲线乘法这个单向加密函数来生成一个公钥(K)。基于公钥(K),可以使用单向加密散列函数来生成一个比特币地址(A)。
在这一节中,我们将从生成私钥开始,介绍如何用椭圆曲线运算将私钥转换成一个公钥,最后,如何从公钥生成比特币地址。
私钥、公钥和比特币地址之间的关系如下图所示。
为什么在比特币中使用非对称加密?
它并不被用于对比特币交易“加密”(保密)。相反,非对称加密技术最有用的特性是能够生成数字签名。可以将私钥应用到比特币交易的数字指纹上,以生成数字签名。该签名只能由拥有私钥的人生成。但是任何可以访问其公钥和交易指纹的人都可以使用它们来验证签名的真伪。这种非对称加密的有用特性使得任何人都可以验证每个交易上的每个签名,同时确保只有私钥的所有者才能生成有效的签名。
(3)私钥
私钥只是一个随机选择的数字。对私钥的所有权和控制权是用户对相应的比特币地址中的所有资金的控制根源。
在比特币交易中,私钥用于生成支付比特币所需的签名以证明对资金的所有权。私钥在任何时候都必须保密,因为一旦泄露给第三方就相当于让他们控制了此私钥所保护的比特币。私钥也必须得到备份和保护,避免意外丢失,因为一旦丢失无法恢复,其所保护的比特币也会永远丢失。
比特币私钥只是一个数字。你可以用硬币、铅笔和纸来随机生成你的私钥:抛硬币256次,用纸和笔记录硬币正反面出现的次数,并转换为0和1,就此得到的256位二进制数字可作为私钥在比特币钱包里使用。根据该私钥,可进一步生成公钥。
从一个随机数生成私钥
生成密钥的第一步也是最重要的一步,是要找到足够安全的熵源,即随机性来源。生成一个比特币私钥在本质上就是“在1和2256之间选一个数字”。只要选取的结果是不可预测或不可重复的,那么选取数字的具体方法并不重要。比特币软件使用操作系统底层的随机数生成器来产生256位的熵(随机性)。通常情况下,操作系统随机数生成器由人工随机源进行初始化,这就是为什么你也许会被要求晃动你的鼠标几秒钟。
更准确地说,私钥可以是1和n-1之间的任何数字,其中n是一个常数(n=1.158×1077,略小于2256),并被定义为在比特币里所使用的椭圆曲线的阶。要生成这样的私钥,我们随机选择一个256位的数字,并检查它是否小于n-1。从编程的角度来看,一般是通过在一个密码学安全的随机源中取出一长串随机字节,对其使用SHA256散列算法进行运算,这样就可以方便地产生一个256位的数字。如果运算结果小于n-1,我们就有了一个合适的私钥。否则,我们就用另一个随机数再重复一次这个过程。
不要自己写代码或使用编程语言提供的简易随机数生成器来获得一个随机数。使用密码学安全的伪随机数生成器(CSPRNG),并且需要有一个来自具有足够熵值源的种子。使用随机数生成器的函数库时,必须仔细研读其文档,以确保它是密码学安全的。正确实施CSPRNG是密钥安全性的关键所在。
下面是一个以十六进制格式显示的随机生成的私钥(k)(256位的二进制数以64位十六进制数显示,每个十六进制数占4位):
1E99423A4ED27608A15A2616A2B0E9E52CED330AC530EDCC32C8FFC6A526AEDD
比特币私钥空间的大小是2256,这是一个非常大的数字。用十进制表示的话,大约是1077。给你一些实际的概念作对比,目前可见宇宙估计含有1080个原子。
要使用比特币核心客户端生成一个新的密钥,可使用getnewaddress命令。出于安全考虑,命令运行后只显示生成的公钥,而不显示私钥。如果要bitcoind显示私钥,可以使用dumpprivkey命令。dumpprivkey命令会把私钥以Base58校验和编码格式显示,这种私钥格式被称为钱包导入格式(Wallet Import Format,WIF)。
下面给出了使用这两个命令生成和显示私钥的例子:
$ bitcoin-cli getnewaddress 1J7mdg5rbQyUHENYdx39WVWK7fsLpEoXZy $ bitcoin-cli dumpprivkey 1 J7mdg5rbQyUHENYdx39WVWK7fsLpEoXZyKxFC1jmwwCoACiCAWZ3eXa96mBM6tb3TYzGmf6YwgdGWZgawvrtJ
dumpprivkey命令打开钱包并提取由getnewaddress命令生成的私钥。除非密钥对都存储在钱包里,否则bitcoind并不能从公钥得知私钥。dumpprivkey命令无法从公钥得到对应的私钥,因为这是不可能的。这个命令只是显示钱包中已知的由getnewaddress命令生成的私钥。
你还可以使用Bitcoin Explorer命令行工具,使用命令seed、ec-new和ec-to-wif生成和显示私钥:
$ bx seed | bx ec-new | bx ec-to-wif 5J3mBbAH58CpQ3Y5RNJpUKPE62SQ5tfcvU2JpbnkeyhfsYB1Jcn
前面说过,私钥的产生和比特币协议本身没有绑定关系,只要遵循安全的编码规范,任何人都可以实现一套公私钥生成系统。下图展示了一个在线比特币秘钥生成的UI界面。

(4)公钥
通过椭圆曲线乘法可以从私钥计算得到公钥,这是不可逆转的过程:K=k*G。其中k是私钥,G是被称为生成点的常数点,而K是所得公钥。其反向运算,被称为“寻找离散对数”(已知公钥K来求出私钥k)是非常困难的,就像去试验所有可能的k值,即暴力搜索。
在演示如何从私钥生成公钥之前,我们先详细地介绍下椭圆曲线密码学。
椭圆曲线乘法是密码学家称之为“陷阱门”的一种函数:在一个方向(乘法)很容易计算,而在相反的方向(除法)不可能计算。私钥的所有者可以容易地创建公钥,然后放心地与全世界共享,确信没有人可以从公钥中逆向计算得出私钥。这个数学技巧成为证明比特币所有权的不可伪造和安全的数字签名的基础。
(5)椭圆曲线密码学
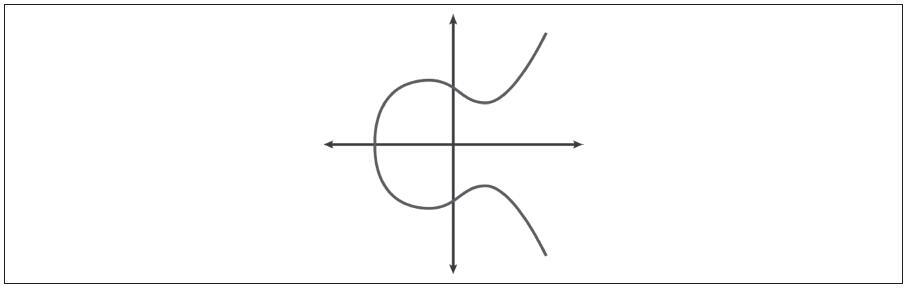
椭圆曲线密码学(Elliptic Curve Cryptography)是一种基于离散对数问题的非对称密码学或公钥密码学,它是在椭圆曲线的点上进行加法和乘法表示的。
下图是一个椭圆曲线的示例,类似于比特币所用的曲线。
比特币使用的是一个特定的椭圆曲线和一组数学常数,它是由美国国家标准与技术研究所(NIST)制定的标准secp256k1定义的。secp256k1曲线由下述函数定义,该函数可产生一条椭圆曲线:
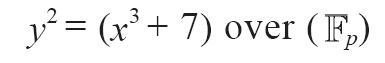
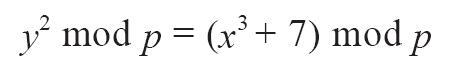
上述mod p(质数p取模)表明该曲线是在素数阶p的有限域内,也写作Fp,其中p=2256-232-29-28-27-26-24-1,是非常大的质数。
因为这条曲线被定义在一个质数阶的有限域内,而不是定义在实数范围,它的函数图像看起来像分散在两个维度上的离散的点,因此很难可视化。然而,其中的数学原理与实数范围内的椭圆曲线相似。作为一个例子,下图显示了在一个小了很多的质数阶17的有限域内的椭圆曲线,其形式为网格上的一系列散点。而secp256k1的比特币椭圆曲线可以被想象成一个极大的网格上一系列更为复杂的散点。
例如,下面是坐标为(x,y)的点P,它是secp256k1曲线上的点。
P =
(55066263022277343669578718895168534326250603453777594175500187360389116729240, 32670510020758816978083085130507043184471273380659243275938904335757337482424)下例展示了如何使用Python检查。
# -*- coding: utf-8 -*-
if __name__ == '__main__':
p = 115792089237316195423570985008687907853269984665640564039457584007908834671663
x = 55066263022277343669578718895168534326250603453777594175500187360389116729240
y = 32670510020758816978083085130507043184471273380659243275938904335757337482424
print (x ** 3 + 7 - y ** 2) % p
在椭圆曲线的数学原理中,有一个点被称为“无穷远点”,这大致对应于0在加法中的作用。在计算机中,有时用x=y=0表示(虽然这不满足椭圆曲线方程,但这是一个可以检查的简单独立的例子)。
还有一个+运算符,叫作“加法”,它有一些属性,类似于小学生学习的实数加法。在椭圆曲线上给定两点P1和P2,第三点P3=P1+P2也在椭圆曲线上。
几何学上,第三点P3是通过在P1和P2之间画一条线来计算得到的。这条线恰好在一个额外的地方与椭圆曲线相交。此点记作P′3=(x,y),然后将其在x轴上翻折得到P3=(x,-y)。
下面是几个可以解释为何需要“无穷远点”的特殊案例。
若P1和P2是同一点,P1和P2间的连线则为点P1的切线。曲线上有且只有一个新的点与该切线相交。该切线的斜率可用微积分求得。尽管我们只关注整数坐标的二维曲线,但这些技巧还是很管用的。
在某些情况下(例如,如果P1和P2有相同的x值,但y值不同),则切线将完全垂直,在这种情况下,P3=“无穷远点”。
- 若P1是“无穷远点”,那么其和P1+P2=P2
- 若P2是无穷远点,则P1+P2=P1
这就是无穷远点类似于0的作用。事实证明,在这里+运算符遵守结合律,这意味着(A+B)+C=A+(B+C)。这就是说我们可以直接不加括号书写A+B+C,而不至于混淆。至此我们已经定义了椭圆加法,我们可以对乘法用拓展加法的标准方法进行定义。给定椭圆曲线上的点P,如果k是整数,则kP=P+P+P+…+P(k次)。注意,在这种情况下k有时被混淆而称为“指数”。
(6)创建公钥
以一个随机生成的私钥k为起步,我们将其与曲线上预定的生成点G相乘以获得曲线上的另一点,也就是相应的公钥K。生成点是secp256k1标准的一部分,对所有比特币密钥都是相同的:
K=k*G
其中k是私钥,G是生成点,K是在该曲线上所得的点,是公钥。
因为所有比特币用户的生成点是相同的,一个私钥k乘以G必将得到相同的公钥K。k和K之间的关系是固定的,但只能单向运算,即从k得到K。这就是可以把比特币地址(从K衍生而来)与任何人共享而不会泄露私钥(k)的原因。
此数学方法是单向的,所以私钥可以转换为公钥,但公钥不能反向转换回私钥。
为实现椭圆曲线乘法,我们将之前产生的私钥k与生成点G相乘得到公钥K:
K = 1E99423A4ED27608A15A2616A2B0E9E52CED330AC530EDCC32C8FFC6A526AEDD * G
公钥K被定义为一个点K=(x,y):
K = (x, y)
其中,
x = F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A y = 07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDB
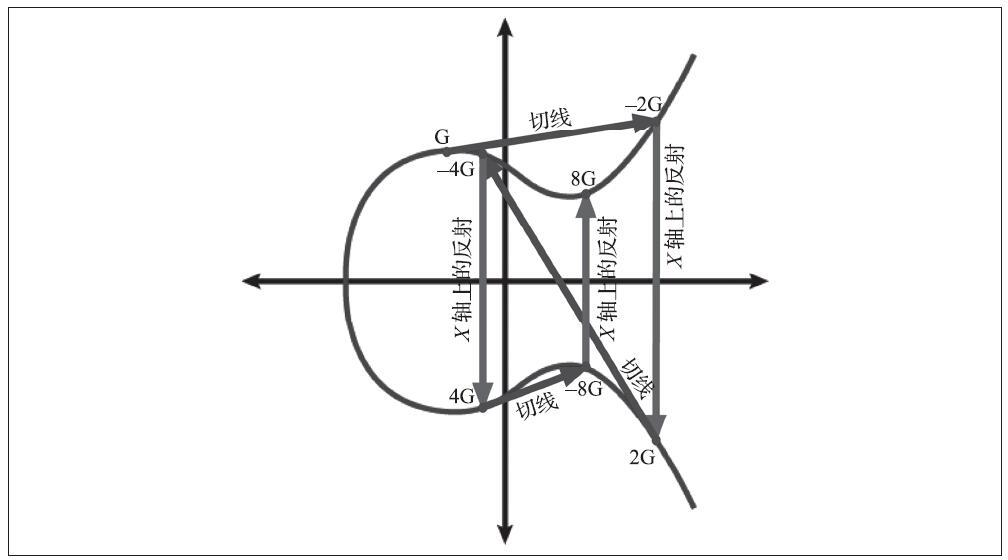
为了可视化点和整数的乘法,我们将选用较为简单的实数范围的椭圆曲线。请记住,其中的数学原理是相同的。我们的目标是找到生成点G的倍数kG,也就是将G自我相加k次。在椭圆曲线中,点的相加等同于从该点画切线找到与曲线相交的另一点,然后翻折到x轴。
下图显示了在曲线上得到G、2G、4G的几何操作。
大多数比特币程序使用OpenSSL加密库(http://bit.ly/1ql7bm8)进行椭圆曲线计算,例如,调用EC_POINT_mul()函数来计算获得公钥。
比特币地址
比特币地址是一个由数字和字母组成的字符串,你可以把它分享给任何想给你发比特币的人。由公钥(公钥同样是由数字和字母组成的一串字符串)生成的比特币地址以数字“1”开头。下面是一个比特币地址的例子:
1J7mdg5rbQyUHENYdx39WVWK7fsLpEoXZy
比特币地址通常在比特币交易中以“收款方”出现。如果把比特币交易比作一张支票,比特币地址就是受益人,也就是我们要填写收款人的一栏。一张支票的收款人可能是某个银行账户,也可能是某个公司、机构,甚至是现金。纸质支票不需要指定一个特定的账户,而是用一个抽象的名字作为收款人,这使它成为一种相当灵活的支付工具。
与此类似,比特币交易使用比特币地址这一概念提供类似的抽象,使比特币交易变得非常灵活。比特币地址可以代表一对公钥和私钥的所有者,也可以代表其他东西,比如支付脚本。
现在让我们来看一个简单的例子,由公钥生成的比特币地址。
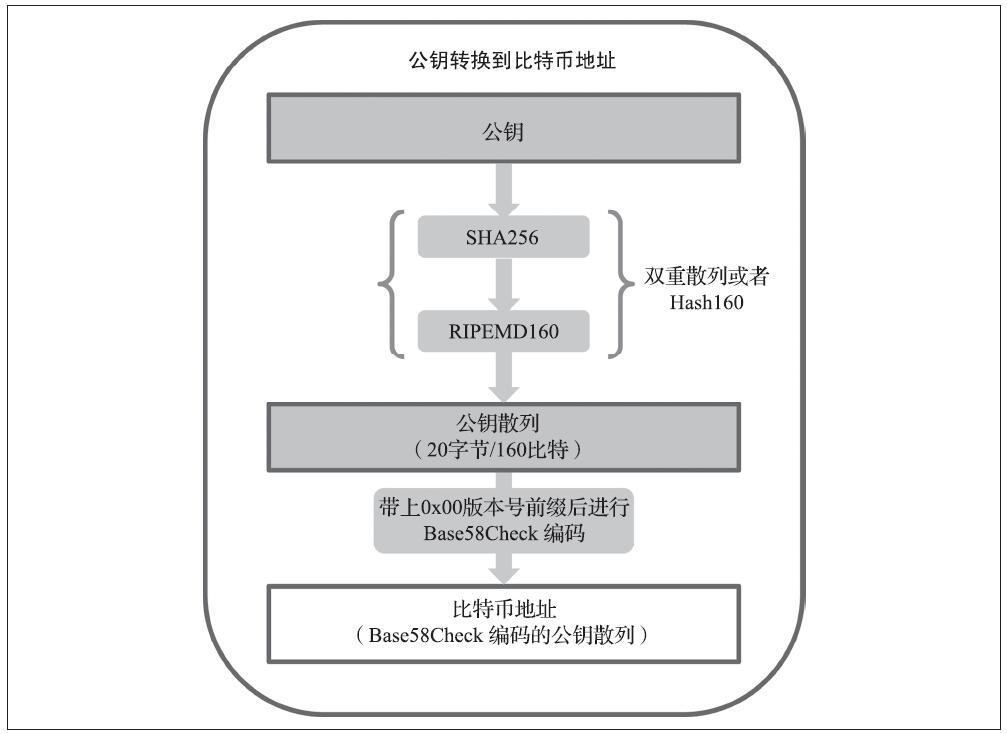
比特币地址可由公钥经过单向的加密散列算法得到。散列算法是一种单向函数,它能接收任意长度的输入值产生一个指纹或散列。加密散列函数在比特币中被广泛使用,作为比特币地址、脚本地址以及挖矿中的工作量证明算法。由公钥生成比特币地址时使用的算法是Secure Hash Algorithm(SHA)和RACE Integrity Primitives Evaluation MessageDigest(RIPEMD),或者叫SHA256和RIPEMD160。
以公钥K为输入,计算其SHA256散列值,并以此结果计算RIPEMD160散列值,得到一个长度为160位(20字节)的数字:
A=RIPEMD160(SHA256(K))
上述公式中K是公钥,A是生成的比特币地址。
比特币地址与公钥不同。比特币地址是由公钥经过单向的散列函数生成的。
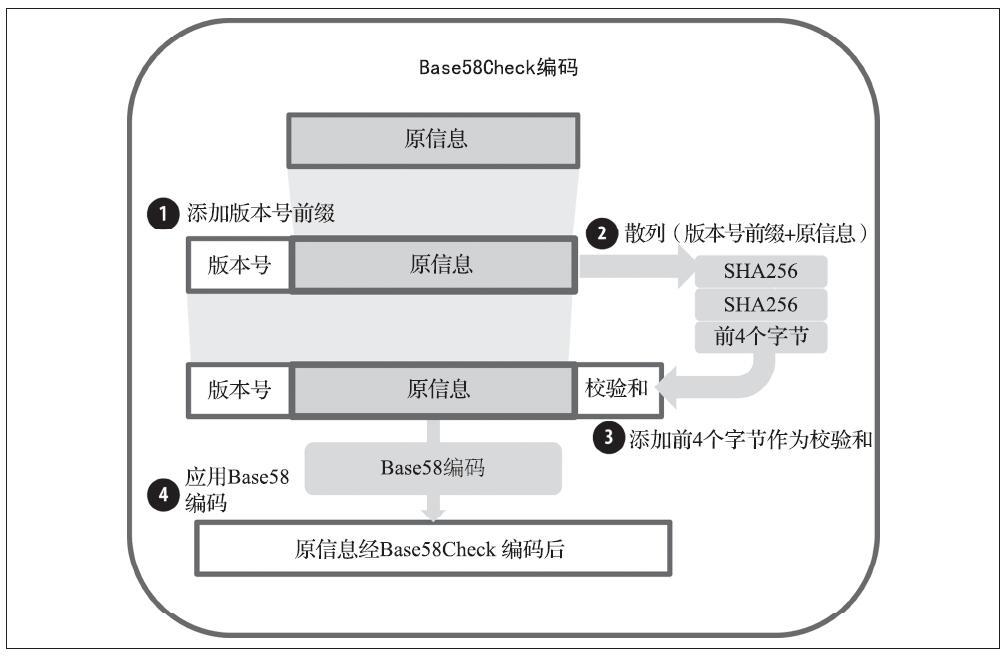
比特币地址通常都是经过“Base58Check”编码的,这种编码使用了58个字符(一种Base58数字系统)和一个校验码来提高人工可读性、避免歧义,并防止在地址转录和输入中发生错误。Base58Check编码也被用于比特币的其他许多地方,例如比特币地址、私钥、加密的密钥和脚本散列中,用来提高可读性和录入的正确性。
下图描述了如何从公钥生成比特币地址。
(1)Base58和Base58Check编码
为了以紧凑的方式表示长串数字,使用更少的符号,许多计算机系统使用基数大于10的混合字母数字表示法。例如,传统的十进制系统使用0到9这10个数字,十六进制系统使用16个符号,0到9的10个数字外加字母A到F作为六个附加符号。以十六进制格式表示的数字比相应的十进制表示更短。
更加紧凑的Base64表示法使用26个小写字母,26个大写字母,10个数字和2个符号(例如“+”和“/”),用于在电子邮件这样的基于文本的媒介中传输二进制数据。Base64通常用于编码邮件中的附件。Base58是一种基于文本的二进制编码格式,用在比特币和其他的加密货币中。这种编码格式不仅实现了数据压缩,保持了易读性,还具有错误诊断和预防功能。Base58是Base64编码格式的子集,同样使用大小写字母和10个数字,但舍弃了一些容易错读和在特定字体中容易混淆的字符。具体来讲,Base58不含Base64中的0(数字0)、O(大写字母o)、l(小写字母L)、I(大写字母i),以及“+”和“/”两个字符。简而言之,Base58就是由不包括0、O、l、I这4个字符的大小写字母和数字组成。
比特币的Base58字母表如下:
123456789ABCDEFGHJKLMNPQRSTUVWXYZabcdefghijkmnopqrstuvwxyz
Base58Check是一种常用在比特币中的Base58编码格式,为了防止输入和转录错误,增加安全性,内置检查错误的编码。检验和(checksum)是添加到正在编码的数据末端的额外4个字节。校验和是从编码的数据的散列值中得到的,所以可以用来检测并避免转录和输入中产生的错误。使用Base58check编码时,解码软件会计算数据的校验和并和编码中自带的校验和进行对比。二者不匹配则表明有错误产生,那么这个Base58Check的数据就是无效的。
一个错误的比特币地址就不会被钱包软件接受为有效的地址,否则这种错误会造成资金丢失。
为了将数据(数字)转换成Base58Check格式,我们先要对数据添加一个叫作“版本字节”的前缀,这个前缀用来方便地识别编码的数据类型。例如,
- 比特币地址的前缀是0(十六进制表示是0x00)
- 私钥编码时前缀是128(十六进制表示是0x80)
下表会列出一些常见的版本前缀。

接下来,我们计算“双散列”校验和,意味着要对之前的计算结果(前缀和数据)运行两次SHA256散列算法:
checksum = SHA256(SHA256(prefix+data))
在产生的长32个字节的散列值(hash-of-a-hash)中,我们只取前4个字节。这4个字节就作为检验错误的代码或者校验和。校验和会被添加到数据之后。
结果由三部分组成:
- 前缀
- 数据
- 校验和
这个结果采用之前描述的Base58字母表编码。
下图描述了Base58Check编码的过程。
在比特币中,大多数需要向用户展示的数据都使用Base58Check编码,编码后的数据紧凑、易读,而且易于检验错误。
Base58Check编码中的版本前缀是用来创造易于辨别的格式,当在Base58中编码时,在Base58Check编码的有效负载开始时包含特定的字符。这些字符使用户可以轻松明确被编码的数据的类型以及如何使用它们。这就是不同的地方,例如,
- Base58Check编码的比特币地址是以1开头的
- Base58Check编码的私钥WIF是以5开头的
下表展示了一些版本前缀和它们对应的Base58格式。

我们回顾比特币地址产生的完整过程,从私钥到公钥(椭圆曲线上的某个点),再到两次散列的地址,最终到Base58Check编码。
(2)密钥的格式
公钥和私钥都可以以多种不同格式呈现。虽然看起来格式不同,但是密钥所编码的数字并没有改变。这些不同的编码格式主要是用来方便人们无误地使用和识别密钥。
1、私钥的格式
私钥可以以许多不同的格式表示,所有这些格式都对应同一个256位的数字。下表展示了私钥的三种常见格式。不同的格式在不同的场景下使用。

- 十六进制和原始的二进制格式用在软件的内部,很少展示给用户看。
- WIF格式用在钱包之间密钥的输入和输出,也用于显示私钥的二维码(条形码)。
下表展示用这三种不同的格式生成的同一个私钥。

这些表示法都是用来表示相同的数字、相同的私钥的不同方法。虽然编码后的字符串看起来不同,但不同的格式彼此之间可以很容易地相互转换。
我们使用Bitcoin Explorer中的wif-to-ec命令来显示两个WIF键代表相同的私钥:
$ bx wif-to-ec 5J3mBbAH58CpQ3Y5RNJpUKPE62SQ5tfcvU2JpbnkeyhfsYB1Jcn 1e99423a4ed27608a15a2616a2b0e9e52ced330ac530edcc32c8ffc6a526aedd $ bx wif-to-ec KxFC1jmwwCoACiCAWZ3eXa96mBM6tb3TYzGmf6YwgdGWZgawvrt J1e99423a4ed27608a15a2616a2b0e9e52ced330ac530edcc32c8ffc6a526aedd
2、从Base58Check解码
Bitcoin Explorer命令使得编写用于处理比特币密钥、地址和交易的shell脚本和命令行“管道”变得容易。你可以使用Bitcoin Explorer在命令行上解码Base58Check格式。
我们使用base58check-decode命令解码未压缩的密钥:
$ bx base58check-decode 5J3mBbAH58CpQ3Y5RNJpUKPE62SQ5tfcvU2JpbnkeyhfsYB1Jcn
wrapper{
checksum 4286807748
payload 1e99423a4ed27608a15a2616a2b0e9e52ced330ac530edcc32c8ffc6a526aedd
version 128
}结果包含密钥作为有效负载,WIF版本前缀128和一个校验和。
请注意,压缩密钥的“有效负载”附加了后缀01,表示导出的公钥需要被压缩:
$ bx base58check-decode KxFC1jmwwCoACiCAWZ3eXa96mBM6tb3TYzGmf6YwgdGWZgawvrtJ
wrapper{
checksum 2339607926
payload 1e99423a4ed27608a15a2616a2b0e9e52ced330ac530edcc32c8ffc6a526aedd01
version 128
}3、将十六进制转换为Base58Check编码
要转换成Base58Check(与上一个命令相反),我们使用Bitcoin Explorer的base58check-encode命令,并提供十六进制私钥,以及WIF版本前缀128:
bx base58check-encode 1e99423a4ed27608a15a2616a2b0e9e52ced330ac530edcc32c8ffc6a526aedd --version 128 5J3mBbAH58CpQ3Y5RNJpUKPE62SQ5tfcvU2JpbnkeyhfsYB1Jcn
4、将十六进制(压缩格式密钥)转换为Base58Check编码
要将压缩格式的私钥进行Base58Check编码,我们需在十六进制私钥的后面添加后缀01,然后使用上述的方法编码:
$ bx base58check-encode 1e99423a4ed27608a15a2616a2b0e9e52ced330ac530edcc32c8ffc6a526aedd01 --version 128KxFC1jmwwCoACiCAWZ3eXa96mBM6tb3TYzGmf6YwgdGWZgawvrtJ
生成的WIF压缩格式的私钥以字母“K”开头,用以表明被编码的私钥有一个后缀“01”,且该私钥只能被用于生成压缩格式的公钥。
5、公钥的格式
公钥也可以用多种不同的格式来表示,通常分为非压缩格式公钥和压缩格式公钥。
从前文可知,公钥是在椭圆曲线上的一个点,由一个坐标值(x,y)组成。公钥通常表示为前缀04紧接着两个256位的数字,其中一个256位数字是公钥的x坐标,另一个256位数字是y坐标。前缀04表示其为非压缩格式公钥,压缩格式公钥以02或者03开头。
下面是由前文中的私钥所生成的公钥,其坐标x和y如下:
x = F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A y = 07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDB
下面是同样的公钥以520位的数字(130个十六进制数字)来表达。这个520位的数字以前缀04开头,紧接着是x及y坐标,组成格式为04 x y:
K = 04F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A07CF33DA18BD734C600B96A72BBC4749D5141C90EC8AC328AE52DDFE2E505BDB
6、压缩格式公钥
将压缩的公钥引入比特币,是为了减少交易的大小,并为存储比特币区块链数据库的节点节省磁盘空间。大部分比特币交易包含了公钥,用于验证用户的凭据和支付比特币。每个公钥有520位(包括前缀,x坐标,y坐标),如果乘以每个区块数百个的交易,或者每天发生的成千上万的交易,区块链里就会被写入大量的数据。
如前所述,一个公钥是椭圆曲线上的一个点(x,y)。而椭圆曲线实际是一个数学方程,曲线上的点实际是该方程的一个解。因此,如果我们知道了公钥的x坐标,就可以通过解方程y2mod p=(x3+7)mod p得到y坐标的值。这种方案可以让我们只存储公钥的x坐标,略去y坐标,从而将公钥的大小和存储空间减少了256位。每个交易所需要的字节数减少了几乎一半,日积月累,这就大大节省了数据传输和存储。
未压缩格式公钥使用04作为前缀,而压缩格式公钥是以02或03作为前缀。让我们来研究下需要这两种不同前缀的原因:因为椭圆曲线加密等式的左边是y2,也就是说y的解是来自于一个平方根,可能是正值也可能是负值。更形象地说,y坐标可能在x坐标轴的上面或者下面。从下图的椭圆曲线图中可以看出,曲线是对称的,也就是说从x轴看就像对称的镜子中的影像。因此,如果我们想省略y坐标,就必须储存y的符号(正值或者负值)。换句话说,对于给定的x值,我们需要知道y值在x轴的上面还是下面,因为它们代表椭圆曲线上不同的点以及不同的公钥。当我们在质数p阶的有限域上使用二进制算术计算椭圆曲线的时候,y坐标可能是奇数或者偶数,分别对应前面所讲的y值的正负符号。因此,为了区分y坐标的两种可能值,我们在生成压缩格式公钥时,如果y是偶数,则使用02作为前缀;如果y是奇数,则使用03作为前缀。这样就可以根据公钥中给定的x值,正确推导出对应的y坐标值,从而将公钥解压缩为在椭圆曲线上的完整的点坐标。
下图阐释了公钥压缩。
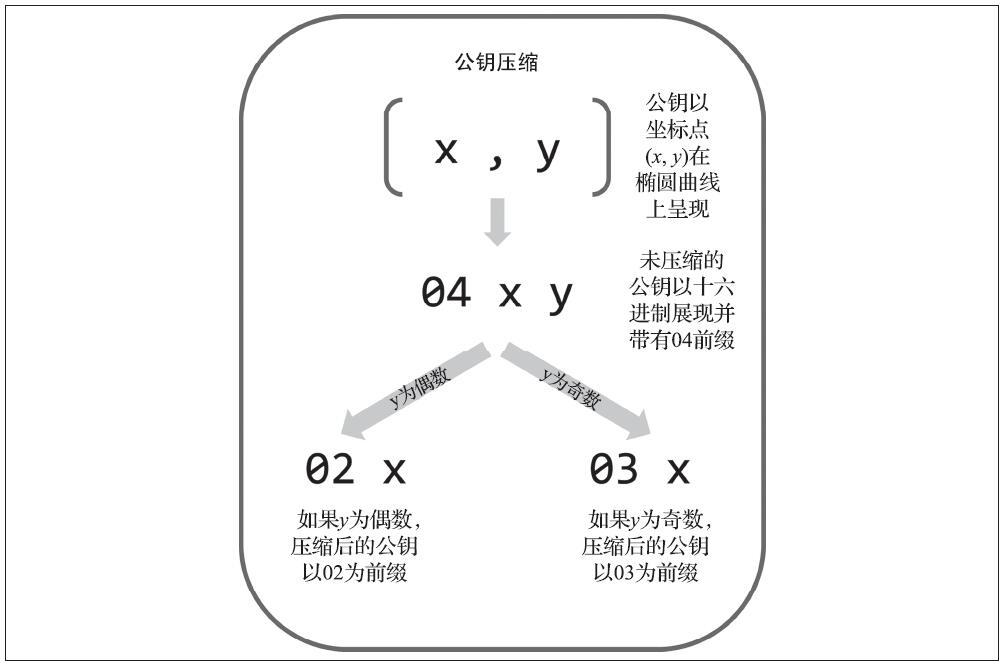
下面是前述章节所生成的公钥,使用了264位(66个十六进制数字)的压缩格式显示,其中前缀03表示y坐标是一个奇数。
K = 03F028892BAD7ED57D2FB57BF33081D5CFCF6F9ED3D3D7F159C2E2FFF579DC341A
这个压缩格式公钥对应着同样的一个私钥,这意味它是由同样的私钥所生成的。但是压缩格式公钥和非压缩格式公钥看起来很不同。更重要的是,如果我们使用双散列函数(RIPEMD160(SHA256(K)))将压缩格式公钥转化成比特币地址,得到的地址将会不同于由非压缩格式公钥产生的比特币地址。这样的结果会让人迷惑,因为一个私钥可以生成两种不同格式的公钥——压缩格式和非压缩格式,而这两种格式的公钥可以生成两个不同的比特币地址。但是,这两个不同的比特币地址的私钥是同一个。
压缩格式公钥渐渐成为各种不同的比特币客户端的默认格式,它可以大大减少交易所需的字节数,同时也节约存储区块链所需的磁盘空间。然而,并非所有的客户端都支持压缩格式公钥,于是那些较新的支持压缩格式公钥的客户端就不得不考虑如何处理那些来自较老的不支持压缩格式公钥的客户端的交易。这在钱包软件导入另一个钱包软件的私钥时就会变得尤其重要,因为新钱包需要扫描区块链并找到所有与这些被导入私钥相关的交易。比特币钱包应该扫描哪个比特币地址呢?不论是通过压缩的公钥产生的比特币地址,还是通过非压缩的公钥产生的地址,都是合法的比特币地址,都可以被私钥签名,但是它们是不同的比特币地址。
为了解决这个问题,当私钥从钱包中被导出时,代表私钥的WIF在较新的比特币钱包里被处理的方式不同,表明该私钥已经被用来生成压缩的公钥以及压缩的比特币地址。这个方案可以解决导入私钥来自于老钱包还是新钱包的问题,同时也解决了通过公钥生成的比特币地址是来自于压缩格式公钥还是非压缩格式公钥的问题。最后新钱包在扫描区块链时,就可以使用对应的比特币地址去查找该比特币地址在区块链里所发生的交易。
7、压缩格式私钥
实际上“压缩格式私钥”是一种名称上的误导,因为当一个私钥被使用WIF压缩格式导出时,不但没有压缩,而且比“非压缩格式”私钥要多一个字节。因为私钥被加了一个字节的后缀01,见下表,用以表明该私钥是来自于一个较新的钱包,只能被用来生成压缩的公钥。
私钥本身是非压缩的,也不能被压缩。“压缩的私钥”实际上只是表示“用于生成压缩格式公钥的私钥”,而“非压缩格式私钥”用来表明“用于生成非压缩格式公钥的私钥”。为避免更多误解,应该只能说导出格式是“WIF压缩格式”或者“WIF”,而不能说这个私钥是“压缩”的。
下表显示了相同的密钥,在WIF和WIF压缩格式中的编码。

请注意,十六进制压缩私钥格式在末尾有一个额外的字节(十六进制为01)。虽然Base58编码版本前缀对于WIF和WIF压缩格式都是相同的(0x80),但在数字末尾添加一个字节会导致Base58编码的第一个字符从5变为K或L,考虑到对于Base58这是十进制编码100号和99号之间的差别。对于100是一个数字长于99的数字,它有一个前缀1,而不是前缀9。当长度变化,它会影响前缀。在Base58中,前缀5改变为K或L,因为数字的长度增加了一个字节。
要注意的是,这些格式并不是可互换使用的。在实现了压缩格式公钥的较新的钱包中,私钥永远只能被导出为WIF压缩格式(以K或L为前缀)。对于较老的没有实现压缩格式公钥的钱包,私钥将只能被导出为WIF格式(以5为前缀)。这样做的目的就是为了给导入这些私钥的钱包一个信号:是否钱包必须搜索区块链寻找压缩或非压缩公钥和地址。
如果一个比特币钱包实现了压缩格式公钥,那么它将会在所有交易中使用该压缩格式公钥。钱包中的私钥将会被用来在曲线上生成公钥点,这个公钥点将会被压缩。压缩格式公钥被用来生成交易中使用的比特币地址。当从一个实现了压缩格式公钥的新的比特币钱包导出私钥时,钱包导入格式(WIF)将会被修改为WIF压缩格式,该格式将会在私钥的后面附加一个字节大小的后缀01。最终的Base58Check编码格式的私钥被称作compressedWIF(压缩)私钥,以字母“K”或“L”开头。而以“5”开头的是从较老的钱包中以WIF(非压缩)格式导出的私钥。
“压缩格式私钥”是一个不当用词!私钥不是压缩的。WIF压缩格式的私钥只是用来表明它们只能被生成压缩格式的公钥和对应的比特币地址。相反,“WIF压缩”编码的私钥还多出一个字节,因为这种私钥多了后缀“01”。该后缀是用来区分“非压缩格式”私钥和“压缩格式”私钥。
用Python实现秘钥和比特币地址
(1)使用pybitcointools库生成格式化的密钥和比特币地址
下面是一个示例,我们使用pybitcointools库(导入为“bitcoin”)来生成和显示不同格式的密钥和比特币地址。
# -*- coding: utf-8 -*-
import cryptos as bitcoin
if __name__ == '__main__':
# Generate a random private key
valid_private_key = False
while not valid_private_key:
private_key = bitcoin.random_key()
decoded_private_key = bitcoin.decode_privkey(private_key, 'hex')
compressed_private_key = private_key + '01'
valid_private_key = 0 < decoded_private_key < bitcoin.N
print("Private Key (hex) is: ", private_key)
print("Private Key (decimal) is: ", decoded_private_key)
print("Private Key Compressed (hex) is: ", compressed_private_key)
# Convert private key to WIF format bin_to_b58check(encode(priv, 256, 32)+b'\x01', 128+int(vbyte))
wif_encoding_private_key = bitcoin.encode_privkey(decoded_private_key, 'wif')
wif_compressed_private_key = bitcoin.encode_privkey(decoded_private_key, 'wif_compressed')
print("Private Key(WIF) is: ", wif_encoding_private_key)
print("Private Key(WIF-Compressed) is: ", wif_compressed_private_key)
# Multiply the EC generator point G with the private key to get a public key point
public_key = bitcoin.privkey_to_pubkey(decoded_private_key)
print("Public Key (x,y) coordinates is:", public_key)
# Encode as hex, prefix 04
hex_encoded_public_key = bitcoin.encode_pubkey(public_key, 'hex')
print("Public Key (hex) is:", hex_encoded_public_key)
# Compress public key, adjust prefix depending on whether y is even or odd
hex_compressed_public_key = bitcoin.encode_pubkey(public_key, 'hex_compressed')
print("Compress Public Key (hex) is:", hex_compressed_public_key)
# Generate compressed bitcoin address from compressed public key
print("Compressed Bitcoin Address (b58check) is:", bitcoin.pubkey_to_address(hex_compressed_public_key))
(2)用椭圆曲线计算比特币密钥
下面是另外一个示例,使用的是Python ECDSA库来做椭圆曲线计算而非使用任何定制的bitcoin库。
# -*- coding: utf-8 -*-
import ecdsa
import random
from ecdsa.util import string_to_number, number_to_string
if __name__ == '__main__':
# secp256k1, http://www.oid-info.com/get/1.3.132.0.10
_p = int('FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEFFFFFC2F', base=16)
_r = int("FFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFEBAAEDCE6AF48A03BBFD25E8CD0364141", base=16)
_b = int("0000000000000000000000000000000000000000000000000000000000000007", base=16)
_a = int("0000000000000000000000000000000000000000000000000000000000000000", base=16)
_Gx = int("79BE667EF9DCBBAC55A06295CE870B07029BFCDB2DCE28D959F2815B16F81798", base=16)
_Gy = int("483ada7726a3c4655da4fbfc0e1108a8fd17b448a68554199c47d08ffb10d4b8", base=16)
curve_secp256k1 = ecdsa.ellipticcurve.CurveFp(_p, _a, _b)
generator_secp256k1 = ecdsa.ellipticcurve.Point(curve_secp256k1, _Gx, _Gy, _r)
oid_secp256k1 = (1, 3, 132, 0, 10)
SECP256k1 = ecdsa.curves.Curve("SECP256k1", curve_secp256k1, generator_secp256k1, oid_secp256k1)
ec_order = _r
curve = curve_secp256k1
generator = generator_secp256k1
def random_secret():
random_char = lambda: chr(random.randint(0, 255))
convert_to_int = lambda array: int("".join(array).encode("hex"), base=16)
byte_array = [random_char() for i in range(32)]
return convert_to_int(byte_array)
def get_point_pubkey(point):
if point.y() & 1:
key = '03' + '%064x' % point.x()
else:
key = '02' + '%064x' % point.x()
return key.decode('hex')
def get_point_pubkey_uncompressed(point):
key = '04' + \
'%064x' % point.x() + \
'%064x' % point.y()
return key.decode('hex')
# Generate a new private key.
secret = random_secret()
print("Secret: ", secret)
# Get the public key point.
point = secret * generator
print("EC point:", point)
print("BTC public key:", get_point_pubkey(point).encode("hex"))
# Given the point (x, y) we can create the object using:
point1 = ecdsa.ellipticcurve.Point(curve, point.x(), point.y(), ec_order)
assert point1 == point 上面代码中使用os.urandom,它是底层操作系统提供的一个密码学安全的随机数生成器(CSRNG)。在像诸如Linux这样的类Unix操作系统下,它从/dev/urandom中提取;在Windows中,它将调用CryptGenRandom()函数。如果找不到合适的随机性源,将抛出错误NotImplementedError。
这里使用的随机数生成器是出于演示目的,它并不适合生成系统所需的高质量的比特币密钥,因为它的实现没有足够的安全性。
高级秘钥和地址
(1)加密私钥(BIP-38)
私钥必须保密。私钥的保密需求是毋庸置疑的,但在实践中却很难实现,因为它与同等重要的可用性和安全目标相冲突。
当你需要为了避免私钥丢失而存储备份时,会发现维护私钥私密性是一件相当困难的事情。通过密码加密保存私钥的钱包可能要安全一点,但钱包也需要备份。有时用户因为要升级或重装钱包软件,需要将密钥从一个钱包转移到另一个钱包。私钥备份也可能需要存储在纸张上或者外部存储介质里,比如U盘。但如果备份文件失窃或丢失呢?
这些矛盾的安全目标推进了便携、方便、可以被众多不同钱包和比特币客户端理解的加密私钥标准BIP-38的出台。
BIP-38提出了一个通用标准,使用一个口令加密私钥并使用Base58Check对加密的私钥进行编码,这样加密的私钥就可以安全地保存在备份介质里,安全地在钱包间传输,保持密钥在任何可能被暴露情况下的安全性。这个加密标准使用了AES(Advanced EncryptionStandard),它是由NIST建立的,并广泛应用于商业和军事应用的数据加密标准。
BIP-38加密方案的输入项通常是一个使用WIF编码的比特币私钥,一般是前缀为“5”的Base58Check字符串。此外,BIP-38加密方案还可以接收一个由几个单词组成的长密码作为输入项,通常由一系列复杂的字母数字字符组成。BIP-38加密方案的结果是一个以前缀6P开头的Base58check编码的加密私钥。如果你看到一个以6P开头的键,它是加密的并且需要一个密码口令来转换(解密)回到一个可以在任何钱包中使用的WIF格式的私钥(前缀为5)。
许多钱包应用程序现在都能识别出BIP-38加密的私钥,并将提示用户输入密码口令来解密和导入密钥。第三方应用程序,比如非常有用的基于浏览器的BitAddress(http://bitaddress.org)(Wallet Details tab),可以用于解密BIP-38密钥。
通常使用BIP-38加密的密钥用例是纸钱包,用一张纸张来备份私钥。只要用户选择了强口令,使用BIP-38加密私钥的纸钱包就非常安全,这也是一种很棒的比特币离线存储方式(也被称作“冷存储”)。
在bitaddress.org上测试下表中的加密密钥,看看如何输入密码以得到加密密钥。
5J3mBbAH58CpQ3Y5RNJpUKPE62SQ5tfcvU2JpbnkeyhfsYB1Jcn MyTestPassphrase


(2)P2SH和多重签名地址
正如我们所知,传统的比特币地址从数字1开头并且来源于公钥,而公钥来源于私钥。虽然任何人都可以将比特币发送到一个1开头的地址,但比特币只能在通过相应的私钥签名和公钥散列值后才能消费。
以数字3开头的比特币地址是P2SH(pay-to-script hash)地址,有时被错误地称为多重签名或多重签名地址。它们指定比特币交易中受益人为一个脚本的散列,而不是公钥的所有者。这个特性在2012年1月由BIP-16引进,目前因为BIP-16提供了增加功能到地址本身的机会而正被广泛采纳。不同于P2PKH(pay-to-public-key-hash),交易会发送资金到传统的以1开头的比特币地址,资金被发送到以3开头的地址时,需要的不仅仅是一个公钥的散列值和一个私钥签名来作为所有者证明。在创建地址的时候,这些具体的要求会被指定在脚本中,这个地址的所有输入都将受到相同的要求。
P2SH地址是由一个交易脚本创建的,它定义了谁可以消费这个交易输出。编码一个P2SH地址涉及使用一个在创建比特币地址用到过的双重散列函数,并且只能应用于脚本而不是公钥:
script hash = RIPEMD160(SHA256(script))
产生的脚本散列由Base58Check编码,将编码前的版本前缀为5的地址,编码后得到开头为3的编码地址。一个P2SH地址的例子是
3F6i6kwkevjR7AsAd4te2YB2zZyASEm1HM
可以使用Bitcoin Explorer命令脚本编码获得,比如script-encode、sha256、ripemd160和base58check-encode,举例如下:
$ echo dup hash160 [ 89abcdefabbaabbaabbaabbaabbaabbaabbaabba ] equalverify checksig > script $ bx script-encode < script | bx sha256 | bx ripemd160 | bx base58check-encode --version 5 3F6i6kwkevjR7AsAd4te2YB2zZyASEm1HM
P2SH不一定和多重签名的标准交易一样。虽然P2SH地址通常都是代表多重签名,但也可能是编码其他类型的交易脚本。
多重签名地址和P2SH
目前,P2SH函数最常见的实现是多重签名地址脚本。顾名思义,底层脚本需要多个签名来证明所有权,此后才能消费资金。
设计比特币多重签名特性时需要从总共N个密钥中获得M个签名(也被称为“阈值”),被称为M-N多重签名,其中M等于或小于N。这类似于传统的银行中的“联名账户”概念。比如,Bob雇佣的创建网站的网页设计师Gopesh,可为他的业务设计一个2-3的多重签名地址,确保除非至少两个业务合作伙伴签名,否则没有交易可以进行支付。
(3)靓号地址
靓号地址是包含了人类可读信息的有效比特币地址。例如,1LoveBPzzD72PUXLzCkYAtGFYmK5vYNR33包含了Base-58字母love。
靓号地址需要生成并通过数十亿的候选私钥测试,直到一个私钥能生成具有所需靓号样式的比特币地址。虽然有一些优化过的靓号地址生成算法,但该方法必须涉及随机选择一个私钥,生成公钥,再生成比特币地址,并检查是否与所要的靓号样式相匹配,重复数十亿次,直到找到一个完全匹配的地址。
一旦找到一个匹配所要样式的靓号地址,对应这个靓号地址的私钥可以和其他地址的私钥一样被拥有者使用和消费比特币。靓号地址不比其他地址具有更强或更弱的安全性。它们依靠和其他地址相同的椭圆曲线密码学ECC和SHA函数。你无法比任何别的地址更容易地获得一个靓号样式开头的地址的私钥。
1、生成靓号地址
认识到比特币地址不过是由Base58字母代表的一个数字是非常重要的。搜索“1Kids”开头的样式,我们会发现从1Kids11111111111111111111111111111到1Kidszzzzzzzzzzzzzzzzzzzzzzzzzzzzz的地址。这些以“1Kid”开头的地址范围中大约有5829
个地址(约为1.4×1051)。
下表显示了这些包含“1Kids”前缀的地址。

我们把“1Kids”这个前缀当作一个数字,我们可以看看比特币地址中这个前缀出现的频率。如果是一台没有任何特殊硬件的普通性能桌面电脑,可以每秒搜索大约10万个密钥。
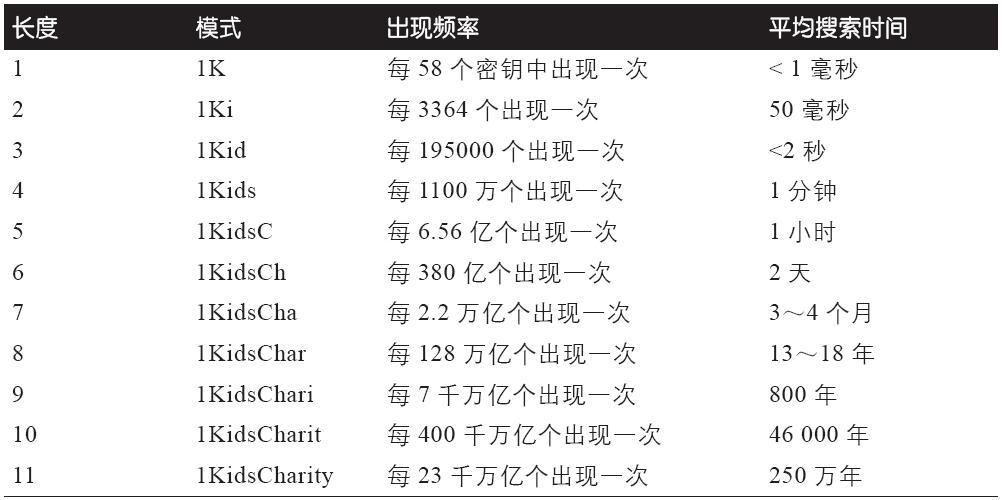
正如你所见,即使有数千台的电脑同时进行运算,她仍要花很长时间才能创建出以“1KidsCharity”开头的靓号地址。每增加一个字符就会增加58倍的计算难度。超过七个字符的样式通常需要专用的硬件才能被找出,譬如用户定制的具有多个图形处理单元(GPU)的台式机。那些通常是无法继续在比特币挖矿中盈利的矿机,被重新赋予了寻找靓号地址的任务。用GPU系统搜索靓号的速度比用通用CPU快很多个量级。
生成一个靓号地址是一项使用蛮力的过程:尝试一个随机密钥,检查生成的地址是否和所需的样式相匹配,重复这个过程直到成功地找到靓号为止。
下面是个靓号矿工的例子,用C++程序写的用于寻找靓号地址的程序。这个例子运用到了libbitcoin库。
#include <algorithm>
#include <string>
#include <bitcoin/bitcoin.hpp>
// CAUTION: Depending on implementation this RNG may not be secure enough!
// CAUTION: Do not use vanity keys generated by this example in production.
bc::ec_secret random_secret()
{
// Create a new secret.
bc::ec_secret secret;
// Fill a secret-sized buffer with random data.
bc::data_chunk buffer(secret.size());
bc::pseudo_random_fill(buffer);
// Copy the data to the secret and return it.
bc::build_array(secret, { buffer });
return secret;
}
// Extract the Bitcoin address from an ec secret.
std::string bitcoin_address(const bc::ec_secret& secret)
{
// Convert secret to a compressed public key.
bc::ec_compressed public_key;
bc::secret_to_public(public_key, secret);
// Generate the payment address of the public key.
bc::wallet::payment_address address(public_key);
// Return the address in base58 encoded form.
return address.encoded();
}
// Convert a string to lower case.
std::string to_lower(const std::string& address, size_t size)
{
std::string lower(address);
const auto tolower = [](unsigned char c){ return std::tolower(c); };
std::transform(lower.begin(), lower.begin() + size, lower.begin(), tolower);
return lower;
}
int main(int argc, char* argv[])
{
// The string we are searching for (converted to lower case).
const char *sarch_code = "1little";
const auto size = std::strlen(sarch_code);
const std::string prefix = to_lower(sarch_code, size);
std::cout << "Searching for address with prefix: " << prefix << std::endl;
std::string lower;
std::string address;
bc::ec_secret secret;
// Loop until the address starts with our prefix...
do
{
// Generate a random secret.
secret = random_secret();
// Get the secret's payment address.
address = bitcoin_address(secret);
// Convert the address to lower case for comparison.
lower = to_lower(address, size);
}
while (!bc::starts_with(lower.begin(), lower.end(), prefix));
// Success!
std::cout << "Found vanity address! " << address << std::endl;
std::cout << "Secret: " << bc::encode_base16(secret) << std::endl;
return 0;
}
// pkg-config --cflags --libs libbitcoin-system
// pkg-config --cflags --libs libbitcoin
// g++ -o vanity-miner vanity-miner.cpp -stdlib=libc++ -std=c++0x $(pkg-config --cflags --libs libbitcoin-system)
// g++ -o vanity-miner vanity-miner.cpp -stdlib=libc++ -std=c++0x $(pkg-config --cflags --libs libbitcoin)
// g++ -o vanity-miner vanity-miner.cpp $(pkg-config --cflags --libs libbitcoin-system)
// g++ -o vanity-miner vanity-miner.cpp $(pkg-config --cflags --libs libbitcoin)
// time ./vanity-miner 你可以尝试在源代码中sarch_code这一搜索模版,看看如果是四个字符或者五个字符的搜索模板需要花多长时间!
注意!hex的比特币公钥地址要以1开头,靓号地址也必须遵循这是个规定。
2、靓号地址安全性
靓号地址既可以增加,也可以削弱安全措施,它们着实是一把双刃剑。用于改善安全性时,一个独特的地址使对手难以使用他们自己的地址替代你的地址,以欺骗你的顾客支付他们的账单。不幸的是,靓号地址也可能使得任何人都能创建一个类似于随机地址的地址,甚至另一个靓号地址,从而欺骗你的客户。
商家可以让人捐款到她宣布的一个随机生成地址(如1J7mdg5rbQyUHENYdx39WVWK7fsLpEoXZy),或者可以生成一个以“1Kids”开头的靓号地址以显得更独特。
在这两种情况下,使用单一固定地址(而不是每笔捐款用一个单独的动态地址)的风险之一是小偷有可能会黑进你的网站,用他自己的地址取代你的地址,从而将捐赠转移给他自己。如果你在不同的地方公布了你的捐款地址,你的用户可以在付款之前检查以确保这个地址跟在你的网站、邮件和传单上看到的地址是同一个。在随机地址为1j7mdg5rbqyuhenydx39wvwk7fslpeoxzy的情况下,普通用户可能会只检查头几个字符“1j7mdg”,就认为地址匹配。使用靓号地址生成器,那些想通过替换类似地址来盗窃的人可以快速生成与前几个字符相匹配的地址,如下表所示。

那靓号地址会不会增加安全性呢?
如果商家生成1Kids33q44erFfpeXrmDSz7zEqG2FesZEN的靓号地址,用户很可能看到靓号样式的字母和随后的额外几个字符,例如在地址部分中注明了1Kids33。这样就会迫使攻击者生成至少6个字符相匹配的靓号地址(比之前多2个字符),就要花费多3364(58×58)倍的努力。
本质上,商家付出的努力(或者靓号矿池付出的)迫使攻击者不得不生成更长的靓号样式。如果商家花钱请矿池生成8个字符的靓号地址,攻击者将会被逼迫到生成10字符的境地,那将是个人电脑无法生成的,对于定制的靓号矿机或靓号矿池来说这也是极其昂贵的。对商家来说可承担得起的支出,对攻击者来说则变成了无法承担的开销,特别是当欺诈的潜在回报不足以支付生成靓号地址所需的费用时更是如此。
(4)纸钱包
纸钱包是打印在纸张上的比特币私钥。有时为了方便起见,纸钱包也包括相应的比特币地址,但这不是必要的,因为地址可以从私钥中导出。纸钱包是一个非常有效的建立备份或者线下存储比特币(即“冷存储”)的方式。作为备份机制,纸钱包可以在由于电脑硬盘损坏、失窃或意外删除等情况造成密钥丢失时,提供安全保障。作为一个冷存储的机制,如果纸钱包密钥在线下生成并永久不在电脑系统中存储,它们在应对黑客攻击、键盘记录器或其他在线电脑威胁时更具有安全性。
纸钱包有许多不同的形状、大小和外观设计,但基本原则是一个密钥和一个地址打印在纸张上。下表展现了纸钱包最基本的形式。

通过使用工具就可以很容易地生成纸钱包,例如使用bitaddress.org网站上的客户端JavaScript生成器。这个页面包含所有生成密钥和纸钱包所需的代码,甚至在完全失去网络连接的情况下,你也可以用它生成密钥和纸钱包。若要使用它,先将HTML页面保存到本地磁盘或外部U盘。从Internet网络断开,用浏览器打开此文件。更好的方式是用一个原始操作系统启动你的电脑,比如一个由光盘启动的Linux系统。任何在脱机情况下使用这个工具所生成的密钥,都可以通过USB线(不是无线打印)在本地打印机上打印出来,从而制造出只存在于纸张上而从未存储在任何在线系统上的密钥和纸钱包。
将这些纸钱包放置在防火保险柜内,发送比特币到相应的比特币地址上,从而实现了一个简单但非常有效的冷存储解决方案。下图展示了通过bitaddress.org网站生成的纸钱包。
这个简单的纸钱包系统的不足之处是那些被打印下来的密钥容易被盗窃。一个能够接近这些纸的小偷只需偷走这些纸或者用照相设备拍下纸上的密钥,就能控制被这些密钥保护的比特币。一个更复杂的纸钱包存储系统使用BIP-38加密的私钥。打印在纸钱包上的这些私钥被其所有者记住的一个口令保护起来。没有口令,这些被加密过的密钥是毫无用处的。它们仍旧优于用口令保护的钱包,因为这些密钥从没有在线过,并且必须从保险箱或者其他物理的安全存储中取出。


虽然你可以多次存款到纸钱包中,但是你最好一次性提取里面所有的资金。因为如果你提取的金额少于其中的总金额的话,有些钱包可能会生成一个找零地址。并且,如果你所用的电脑被病毒感染,那么就有可能泄露私钥。一次性提走所有余款可以减少私钥泄露的风险,如果你所需的金额比较少,那么请把余额发送到一个新的纸钱包里。
纸钱包有许多设计和大小,并有许多不同的特性。可将纸钱包作为礼物送给他人,有季节性的主题,如圣诞节和新年主题。另外一些则是设计某种方式隐藏私钥,如用不透明的刮刮贴,或者折叠和防篡改的铝箔胶粘密封,保存在银行金库或保险箱内。下图展示了几个不同安全和备份功能的纸钱包的例子。
其他设计有密钥和地址的额外副本,类似于票根形式的可以拆卸存根,让你可以存储多个副本以防火灾、洪水或其他自然灾害。


二、钱包
“钱包”一词在比特币中有多重含义。
- 广义上讲,钱包是一个应用程序,为用户提供交互界面。钱包控制用户访问权限,管理私钥和地址,跟踪余额以及创建和签名交易。
- 狭义上讲,从程序员的角度来看,“钱包”是指用于存储和管理用户私钥的数据结构。
在本章中,我们将深入介绍第二层含义,即钱包是私钥的容器,通常以结构化文件或简单数据库的形式来实现。
钱包技术概述
比特币要在真实商业社会中大规模使用,就必须同时考虑到安全性、灵活性、易用性等多维度指标。比特币钱包是涉及到用户核心秘钥的一个关键组件,在基于密码学的安全性的同时,也必须同时考虑到人类的使用习惯和记忆习惯等因素。
在本节中,我们将总结为用户构建友好、安全和灵活的比特币钱包的各项技术。
关于比特币的一个常见误解是比特币钱包包含比特币。实际上,钱包只包含密钥。比特币被记录在比特币网络的区块链中。用户通过使用钱包中的密钥签署交易来控制网络上的比特币。从某种意义上说,比特币钱包是一个钥匙扣(keychain)。
比特币钱包只包含私钥,而不包含比特币。每个用户都有一个包含多个密钥的钱包。钱包实际上是包含私钥/公钥对的钥匙串。用户使用私钥签名交易,从而证明他们拥有交易(比特币)转账所有权。比特币以交易记录(通常记为vout或txout)的形式存储在区块链中。
有两种主要类型的钱包,区别在于它们包含的多个私钥是否相互关联。
- 第一种类型是非确定性钱包(nondeterministic wallet),其中每个私钥都是从随机数独立生成的,密钥彼此之间无关联。这种钱包也称为简单钥匙串(Just a Bunch Of Keys,一堆私钥的集合),简称JBOK钱包。
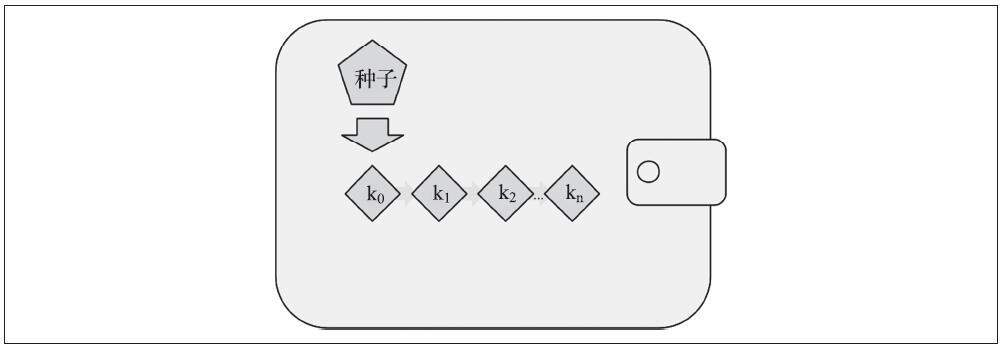
- 第二种类型是确定性钱包(deterministic wallet),其中所有的私钥都是从一个主私钥派生出来,这个主私钥即为种子(seed)。该类型钱包中所有私钥都相互关联,如果有原始种子,则可以再次生成全部私钥。确定性钱包有许多不同的密钥派生方法。最常用的派生方法是使用树状结构,称为分层确定性钱包或HD钱包。确定性钱包由种子派生出来的。为了便于使用,种子被编码为英文单词,也称为助记词。
(1)非确定性(随机)钱包
在最早的比特币客户端中(也就是Bitcoin Core),钱包只是随机生成私钥的集合。例如,Bitcoin Core客户端在首次启动时会预先生成100个随机私钥,并根据需要生成更多的私钥,而且每个私钥只使用一次。这种钱包现在被确定性钱包替代,因为它们难以管理、备份以及导入。随机密钥的缺点就是如果你生成很多私钥,那么你必须保存所有私钥的副本,这就意味着这个钱包必须经常性地备份。每个密钥都必须备份,否则如果钱包变得无法访问,则其控制的资金将不可避免地丢失。如果为了减少备份而复用地址,这种情况直接与避免地址重复使用的原则相冲突——每个比特币地址只用于一次交易。地址重复使用会将多个交易与此地址关联在一起,这样会减少隐私。
当你想避免重复使用地址时,0型非确定性钱包并不是好的选择,特别是如果你想避免地址重用,因为它意味着管理许多密钥,这就需要频繁的备份。
虽然Bitcoin Core客户端包含0型钱包,但比特币的核心开发者并不鼓励大家使用此钱包。下图展示的是一个非确定性钱包,其中含有无关联的随机密钥的集合。
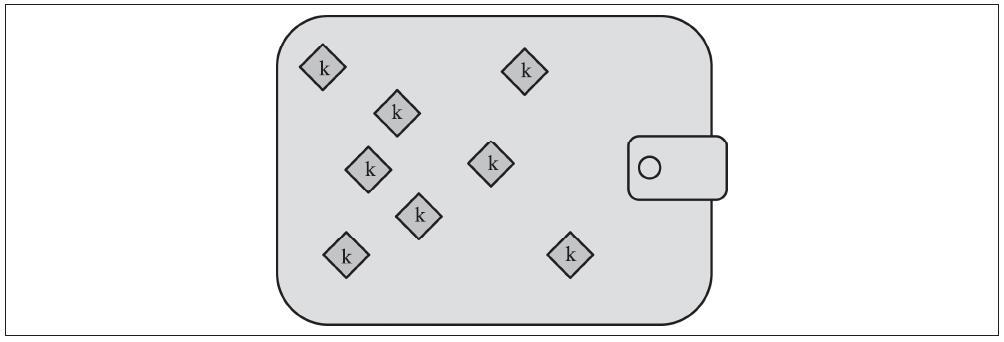
除了简单的测试之外,不要使用非确定性钱包。备份和使用钱包太麻烦了。相反,推荐使用基于行业标准的HD钱包,可以用助记词种子进行备份。
(2)确定性(种子)钱包
确定性,或者“种子”钱包所包含的私钥都是通过使用单向散列(hash)函数从公共种子派生出来的。种子是一串随机生成的数字,这串数字结合索引编号和“链码”可派生出其他私钥。
在确定性钱包中,种子可以恢复所有派生的私钥,因此创建时的一个简单种子备份就足够了。种子也可以用于钱包的导入/导出,在不同的钱包之间可以轻松转移所有私钥。下图为确定性钱包的逻辑图。
(3)分层确定性钱包(BIP-32/BIP-44)
确定性钱包被开发成更容易从单个“种子”派生出许多密钥。确定性钱包目前最高级的版本是通过BIP-32标准定义的HD钱包。HD钱包的私钥是以树状结构派生的,父私钥可以派生出一系列子私钥,每个子私钥又可以派生出一系列孙私钥,以此类推,可以无限派生。树状结构如下图所示。
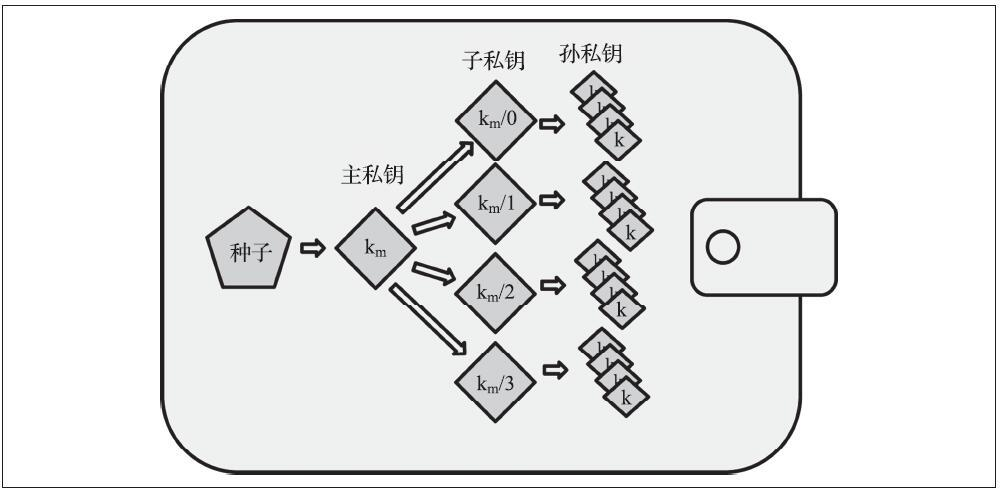
与非确定性(随机)钱包相比,HD钱包具有两大优点。
- 第一,树状结构可以用来表达额外的组织含义。例如当一个特定分支的子私钥被用来收款并使用不同的分支的子私钥用来负责支出。分支私钥也适用于公司组织架构,可以给公司部门、子公司、特殊机构以及会计部门分配不同的分支。
- 第二,HD钱包可以让用户去创建一系列公钥而无须知晓相对应的私钥。这样HD钱包可在安全性不高的服务器中使用或者作为收款专用,为每笔交易提供不同的公钥。公钥不需要被预先加载或者派生,同时在服务器上也没有可用于支付的私钥。
(4)种子和助记词(BIP-39)
HD钱包具有管理多个密钥和地址的强大机制。如果HD钱包的种子是由一组标准化的英文单词生成,这样易于抄录,也可在不同钱包间转移、导出和导入,那就更方便了。这些英文单词称为助记词,标准由BIP-39定义。
今天,大多数比特币钱包(以及其他加密货币的钱包)都使用此标准,并且可以使用能互用的助记词(interoperable mnemonics)进行种子的导入/导出以便进行备份和恢复。
让我们从实用角度出发,来看看以下哪种类型的种子更容易转录、在纸上记录、不易误读,以及在不同的钱包导入/导出。
16进制表示的种子:
0C1E24E5917779D297E14D45F14E1A1A
助记词表示的种子:
army van defense carry jealous true garbage claim echo media make crunch
(5)钱包最佳实践
随着比特币钱包技术的成熟,出现了一些常见的行业标准,使比特币钱包具有广泛的适用性、易用性、安全性和灵活性。这些通用标准是:
- 助记词标准,基于BIP-39
- HD钱包标准,基于BIP-32
- 多用途HD钱包结构标准,基于BIP-43
- 多币种和多账户钱包标准,基于BIP-44
这些标准可能会随着发展而改变或过时,但是现在它们形成彼此依赖的整体,因此这些标准已成为事实上的比特币钱包标准。
这些标准已被大部分软件以及硬件比特币钱包所采用,这使得钱包之间相互通用。用户可以导出在其中一个钱包上生成的助记词,并将其导入另一个钱包,以恢复所有的交易、密钥和地址。
支持这些标准的软件钱包包括(按字母顺序排列)
- Breadwallet
- Copay
- Multibit HD
- Mycelium
支持这些标准的硬件钱包包括(按字母顺序排列)
- Keepkey
- Ledger
- Trezor
以下将详细介绍这些技术。
如果你正准备实现一个比特币钱包,建议将其构建为HD钱包,遵循BIP-32、BIP-39、BIP-43和BIP-44标准,将种子编码为助记词以便备份。
(6)使用比特币钱包
Trezor是一款简单的USB设备,有两个按钮,用于存储私钥(以HD钱包的形式)和签署交易。Trezor钱包遵循本章讨论的所有行业标准,因此不受制于任何专有技术或单一供应商的解决方案。

当首次使用Trezor时,该设备从内置的硬件随机数生成器生成助记词和种子。在初始化阶段,钱包在屏幕上按顺序逐个显示带序号的单词,见下图。

通过写下这些助记词,使用者创建了一个备份,可以在Trezor设备丢失或损坏的情况下用于恢复。助记词可以在新的Trezor钱包,或者任一种兼容的软件和硬件钱包中进行恢复。
请注意,单词序列很重要,因此助记词备份针对每个单词都要有编号。使用者必须仔细记录每个单词的编号,以保持正确的顺序。

为了简单起见,上表只列出了12个词的助记词。事实上,大多数硬件钱包会生成更安全的24个词的助记词。助记词不管长短都是以完全相同的方式使用。
钱包技术细节
现在我们来深入了解被众多比特币钱包所使用的重要行业标准。
(1)助记词编码标准(BIP-39)
助记词编码是表示(可编码成)确定性钱包的随机数种子的英语单词序列。助记词足以重新创建种子,并从种子那里重新创建钱包和所有派生的私钥。
由助记词编码实现的确定性钱包应用程序会在首次创建钱包时向用户显示12~24个序列的单词。该序列的单词就是钱包的备份,可用于在相同或任何兼容的钱包应用中恢复和重新创建所有私钥。与随机数字序列相比,助记词使用户备份钱包更加容易,因为它们易于阅读和正确转录。
助记词经常与“脑钱包”混淆。它们是不一样的,主要区别在于脑钱包由用户选择的单词组成,而助记词是由钱包随机创建并展现给用户的。这个重要的区别使助记词更加安全,因为人类生成随机数的能力非常弱。
助记词在BIP-39中有详细的定义。请注意,BIP-39是助记词标准的一个实施方案。还有一个早于BIP-39不同的标准,使用不同的单词组,由Electrum钱包使用。BIP-39由开发Trezor硬件钱包的公司提出,与Electrum标准并不兼容。然而,BIP-39现在已经在多家通用性实践方面获得了广泛的行业支持,应该被视为事实上的行业标准。
BIP-39定义了助记词和种子的创建,我们在这里分9步描述。为清晰起见,该过程分为两部分:
- 第1~6步参见“创建助记词”一节
- 第7~9步参见“从助记词生成种子”一节
1、创建助记词
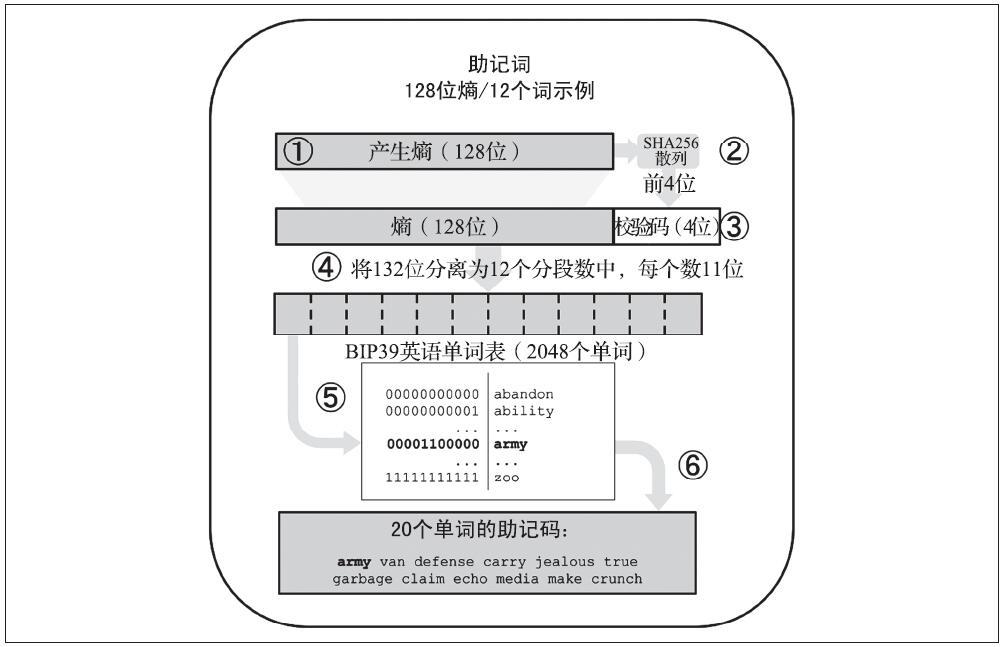
助记词是由钱包使用BIP-39中定义的标准化过程自动生成的。钱包从熵源(随机源)开始,添加校验码(check-sum),然后将随机数映射到单词列表:
- 创建一个128~256位的随机数(熵)。
- 提取随机数的SHA256散列值的前x位(x等于随机数位数除以32)作为检验和。
- 将校验码添加到随机序列的末尾。
- 将序列按11位进行划分。
- 将每11位的值映射到一个含2048(211)个单词的预定义字典中。
- 生成的有顺序的单词组就是助记词。
下图展示了熵如何生成助记词。
下表展示了熵数据的大小和助记词的长度之间的关系。

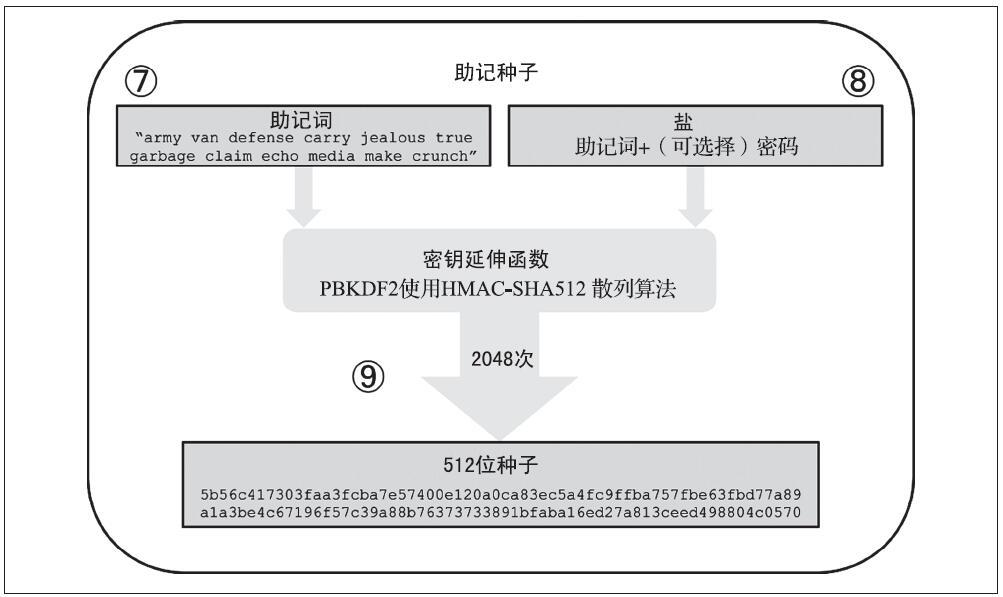
2、从助记词生成种子
助记词表示长度为128~256位的熵(随机数)。通过使用密钥延伸函数PBKDF2,熵被用于派生出更长的(512位)种子。将所得的种子用于构建确定性钱包并派生密钥。
密钥延伸函数有两个参数:
- 助记词
- 盐(slat)
在密钥延伸函数使用盐的目的是增加构建能够进行暴力破解的查找表的难度。在BIP-39的标准中,盐还有另一个目的,它允许引入密码(passphrase),可作为保护种子的一个附加安全保障。
创建助记词之后的第7~9步是:
- PBKDF2密钥延伸函数的第一个参数是从步骤6生成的助记词。
- PBKDF2密钥延伸函数的第二个参数是盐。由固定的字符串“mnemonic”与可选的用户输入的密码字符串连接组成。
- PBKDF2将助记词和盐作为参数,调用2048次HMAC-SHA512散列算法,生成一个512位的值作为其延伸的最终输出。这个512位的值就是种子。
下图显示了从助记词如何生成种子。
密钥延伸函数计算2048次散列是一种非常有效的保护,可以防止对助记词或密码的暴力攻击。它使得攻击代价非常昂贵(从计算的角度),需要尝试成千上万个密码和助记词的组合,而密钥延伸函数可以产生的种子是海量的(2512)。
下表展示了一些助记词的例子和它所生成的种子(没有密码)。
128位熵的助记词,没有密码所产生的种子

128位熵的助记码,增加密码所产生的种子

256位熵的助记词,没有密码所产生的种子

3、BIP-39中的可选密码
BIP-39标准允许在派生种子时使用可选的密码。如果没有使用密码,则使用常量字符串“mnemonic”作为默认密码,从任何给定的助记词产生一个特定的512位种子。如果使用密码短语,密钥延伸函数会从同样的助记词产生出不同的种子。
事实上,只要有助记词,每一个不同的密码短语都会导致不同的种子。本质上,没有“错误”的密码,所有密码都是有效的,它们只是会导致不同的种子,形成一大批可能未初始化的钱包。可能的钱包的集合非常大(2512),使用暴力破解或随机猜测是不可能破解的。
BIP-39中没有“错误的”密码。每个密码都会生成一个钱包,只是未使用的钱包是空的而已。
可选密码带来两个重要特性:
- (存储在大脑中的)密码成为第二个安全因子,使得助记词不能单独使用,避免了助记词备份被盗后资金受损。
- 起到掩人耳目的效果,把其中一个选定的密码指向有少量资金的钱包,分散攻击者的注意力,使其不再关注拥有大额资金的“真正”钱包。
但需要注意的是,使用密码也会导致丢失的风险:
- 如果钱包所有者无行为能力或死亡,没有人知道密码,种子将变得无用,所有存储在钱包中的资金都将永远丢失。
- 相反,如果所有者将密码与种子备份在相同的地方,则违反了上述双因素保护的目的。
虽然密码是非常有用的,但它们只能与精心计划的备份和恢复流程结合使用,考虑到所有者可能的个人风险,应该允许其家人恢复加密货币资产。
4、使用助记词代码
BIP-39在多种编程语言中实现成函数库:python-mnemonic(https://github.com/trezor/python-mnemonic)
SatoshiLabs团队在Python中提出了BIP-39标准的参考实现。bitcoinjs/bip39(https://github.com/bitcoinjs/bip39)
作为流行的bitcoinJS框架的一部分,在JavaScript中实现了BIP-39。libbitcoin/mnemonic(https://github.com/libbitcoin/libbitcoin/blob/master/src/wallet/mnemonic.cpp)
作为流行的Libbitcoin框架的一部分,在C++中实现了BIP-39。
还有一个在独立的网页中实现的BIP-39生成器,对于测试和实验非常有用。下图展示了这个独立的网页,可以生成助记词、种子和扩展私钥。
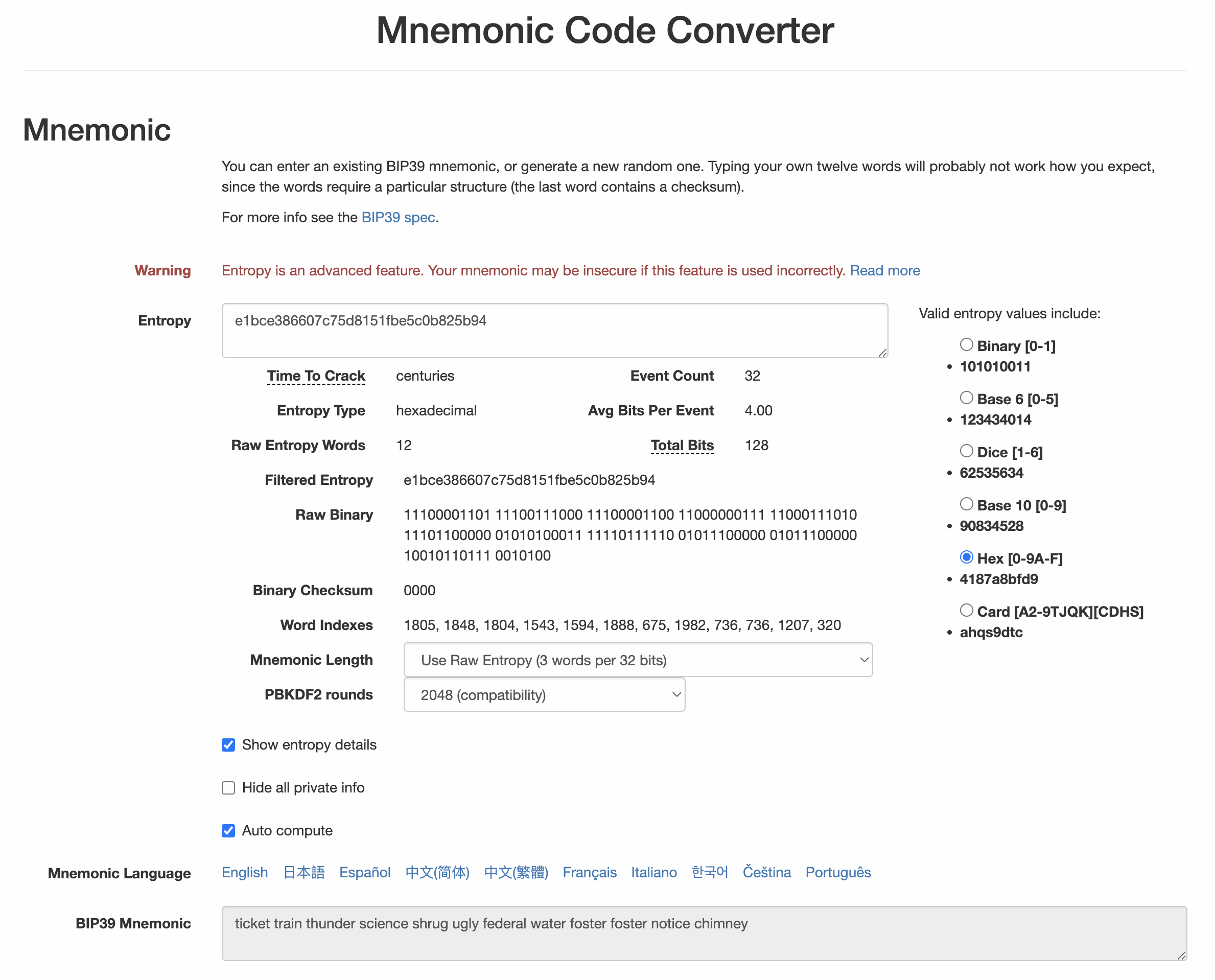
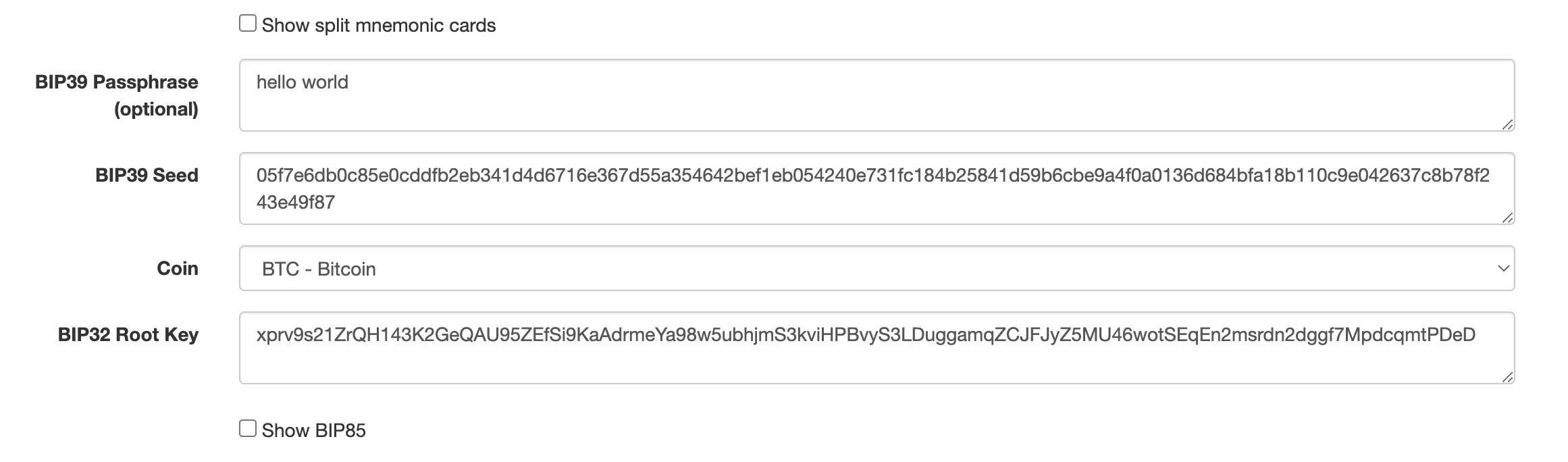
BIP-39生成器可以离线使用,也可以访问地址(https://iancoleman.io/bip39/)。
(2)从种子中创建HD钱包
HD钱包从单个128位、256位,或512位的随机数根种子(root seed)中创建。最常见的情况是,这个种子是从助记词产生的,如上一节所述。
HD钱包中的所有私钥都是从这个根种子确定性地派生出来的,这使得在任何兼容的HD钱包中都可以从该种子重新创建整个钱包。这使得备份、恢复、导出和导入包含数千甚至数百万个密钥的HD钱包变得很容易,只需传输根种子的助记词即可。
下图展示了创建主私钥以及HD钱包的主链码的过程。
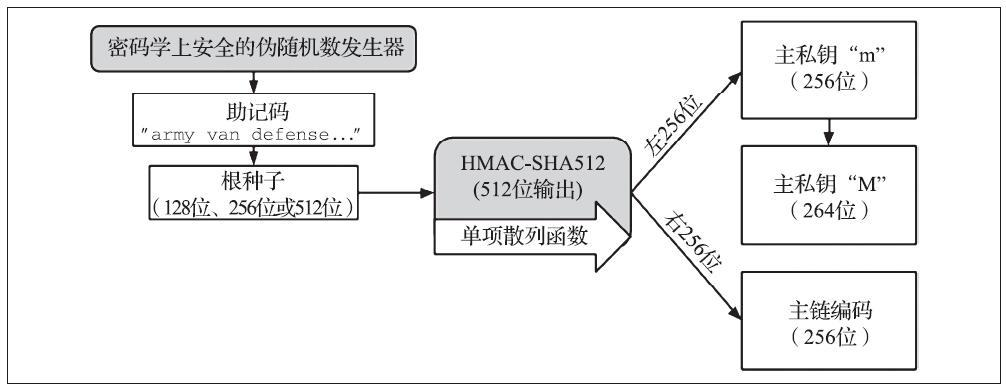
根种子(还有可选密码)输入到HMAC-SHA512算法中就可以得到一个可用来创造主私钥(m)和主链码(c)的散列值。
- 主私钥(m)可以通过标准椭圆曲线m*G乘法流程来生成相对应的主公钥(M)。
- 主链码(c)用于从父私钥创造子私钥的那个函数中引入随机数(熵)。
1、私有子密钥的派生
分层确定性钱包使用CKD(child key derivation,子私钥派生)函数从父私钥派生出子私钥。
子密钥派生函数是基于单向散列函数的,这个函数结合了:
- 一个父私钥或者公钥(ECDSA未压缩密钥)
- 一个256位的链码
- 一个32位的索引码
链码是用来给这个确定性过程引入随机数据的,以便知道索引编号和子私钥也不足以派生其他子私钥。因此,有了子密钥并不能让它派生出自己的兄弟姐妹私钥,除非你已有链码。初始链码种子(在树的根部)是用根种子生成的,而后续的链码从各自的父链码中派生出来。
这三个项(父私钥、链码、索引号)相结合进行散列可以生成子密钥,如下所示。
将父公钥、链码以及索引号结合在一起并且用HMAC-SHA512函数散列之后可以产生512位的散列值。所得的512位散列值可被拆分为两部分。右半部分的256位可以给子链当链码,左半部分256位以及索引码被加载在父私钥上来派生子私钥。
在下图中,我们将看到这个说明。索引码被设为0以产生父私钥的第0个子私钥(即第一个索引,在计算机行业中,索引通常以0开始计数)。
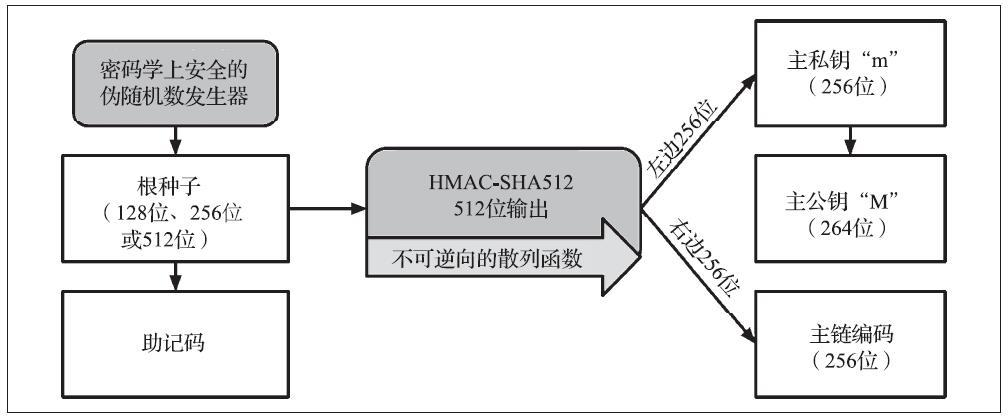
改变索引码可以让我们由父私钥派出子序列中的其他子私钥。比如子私钥0、子私钥1、子私钥2,等等。
每一个父私钥可以有2147483647(231)个子私钥。231是整个整数类型232范围可用的一半,因为另一半是为特定类型的派生而保留的。
向密码树下一层重复这个过程,每个子私钥都可以成为父私钥,继续创造它自己的子私钥,这样可以无穷无尽地派生。这个特性是基于单向陷门函数的单向可重入性保证的。
2、使用派生的子私钥
子私钥和非确定性(随机)私钥无法区分,因为派生函数是单向的,所以子私钥不能被用来推导它们的父私钥。子私钥也不能用来发现它们的相同层级的姊妹密钥。比如你有第n个子私钥,你不能推导它前面的第(n-1)个或者后面的第(n+1)个子私钥或者在同一顺序中的其他子私钥。只有父私钥加上链码才能派生所有的子私钥。
没有子链码,子私钥也不能用来派生出任何孙私钥。你需要同时有子私钥以及对应的链码才能创建一个新的分支来派生出孙私钥。
那子私钥有什么用呢?它可以用来生成公钥和比特币地址。之后它就可以被用来签名交易去消费已经支付到此地址的收款。
子私钥、对应的公钥以及比特币地址和随机创造的密钥与地址是无法区分的。它们是子私钥序列一部分的事实,只有创建它们的HD钱包函数知晓。一旦被创建出来,它们就和“正常”密钥一样运行了。
3、扩展密钥
正如我们之前看到的,只需要三个输入量:一个私钥、一个链码以及想要的子私钥的索引号,私钥派生函数就可以用来创建私钥树上任何层级的子私钥。将私钥以及链码这两个重要的部分组合在一起,称为扩展密钥(extended key)。术语“扩展密钥”也被认为是“可扩展的密钥”,因为这种密钥可以用来派生子密钥。
扩展密钥可以简单地表示为将256位私钥与256位链码串联成的512位序列并储存。实际上有两种类型的扩展密钥:
- 私钥以及链码组成扩展私钥,它可用来派生子私钥(子私钥可以用来派生子公钥)。
- 公钥以及链码组成扩展公钥,它可以用来派生子公钥。
将扩展密钥视为HD钱包中私钥树结构的一个分支的根。利用分支的根你可以派生出这个分支的剩余部分。扩展私钥可以创建一个完整的分支,而扩展公钥只能够创建一个包含公钥的分支。
扩展密钥由私钥(或者公钥)和链码组成。扩展密钥可以派生出子私钥并且能派生出密钥树结构中自己的子分支。共享扩展密钥就意味共享整个子分支。
扩展密钥使用Base58Check来编码,从而能轻松地在不同的兼容BIP-32标准的钱包之间导入/导出。扩展密钥使用特殊的版本号进行Base58Check编码,所以编码的字符中,会出现“xprv”或“xpub”这样的前缀(扩展私钥前缀为xprv,扩展公钥前缀为xpub)。这种前缀可以让编码更易被识别。因为扩展密钥是512位或者513位,所以它比我们之前见到的Base58Check编码字符串更长一些。
以下面的扩展私钥为例,它使用Base58Check编码后为:
xprv9tyUQV64JT5qs3RSTJkXCWKMyUgoQp7F3hA1xzG6ZGu6u6Q9VMNjGr67Lctvy5P8oyaYAL9CAWrUE9i6GoNMKUga5biW6Hx4tws2six3b9c
这是上面扩展私钥对应的扩展公钥,同样使用Base58Check编码:
xpub67xpozcx8pe95XVuZLHXZeG6XWXHpGq6Qv5cmNfi7cS5mtjJ2tgypeQbBs2UAR6KECeeMVKZBPLrtJunSDMstweyLXhRgPxdp14sk9tJPW9
4、子公钥派生
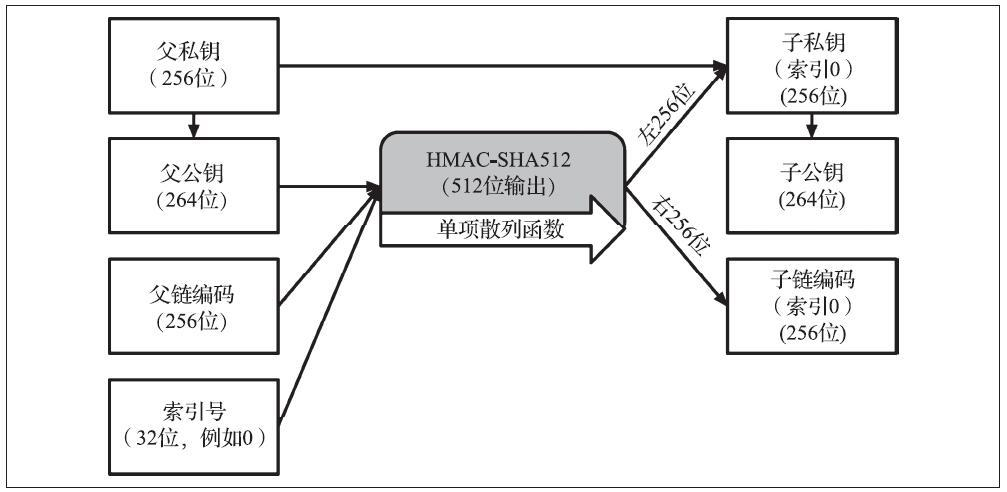
如前所述,HD钱包的一个非常有用的特点是能够从父公钥派生子公钥,而不需要父私钥。这为我们提供了两种生成子公钥的方法:通过子私钥生成,或者直接通过父公钥生成。
因此,可以使用扩展公钥派生出HD钱包结构中该分支的所有公钥(并且只有公钥)。
这种便捷方式可以用来创建非常安全的部署方式——公钥部署:服务器或者应用程序可以拥有扩展公钥的副本但没有私钥。这种部署方式可以创造出无限数量的公钥以及比特币地址,但是发送到这些地址里的比特币此时都不能花费。同时,在另一个更安全的服务器上,扩展私钥可以派生出所有相对应的私钥用于签名交易以及花费这些比特币。
此解决方案的一个常见场景是在电商的服务器上安装扩展公钥。服务器可以使用这个公钥派生函数来为每一笔交易(例如,客户的购物车)创建一个新的比特币地址。服务器上不会保存可能被盗的私钥。如果没有HD钱包,想做到这一点的话,唯一的方法就是在单独的安全服务器上生成成千上万个比特币地址,然后将其预先加载到电商服务器上。这种方法很麻烦,需要不断维护以确保电商服务器不会“用完”地址。
此解决方案的另一种场景是冷存储或者硬件钱包。在这种情况下,扩展私钥可以储存在纸钱包或者硬件设备中(比如Trezor硬件钱包),与此同时扩展公钥可以在线保存。用户可以任意创建“收款”地址,而私钥可以安全地在离线状态下保存。为了使用资金,用户可以用扩展私钥在比特币钱包中进行离线签名或者通过硬件钱包设备(比如Trezor)签名交易。
下图阐述了扩展父公钥来派生子公钥的机制。
(3)在网店中使用扩展公钥
继续Gabriel电商网店的故事,让我们看看Gabriel是如何使用HD钱包的。
Gabriel开始是出于爱好而开的网店,在一个网上WordPress托管服务上建了个网站,作为他的网上商店。他的网店非常简单,只有几个页面和一个带有比特币地址的表单页。
Gabriel使用他的Trezor设备生成的第一个比特币地址作为他的商店的收款地址。这样,所有付款都将付给他的Trezor硬件钱包所控制的地址。
客户可以使用表单页提交订单并向Gabriel发布的比特币地址付钱,并触发一封电子邮件,其中包含需要Gabriel处理的订单详情。当每周只有几个订单时,这个系统运行得很好。
然而,这家小型网络商店变得相当成功,吸引了很多来自当地社区的订单。Gabriel很快就不知所措了,由于所有订单都支付相同的地址,因此难以正确匹配订单和交易,特别是当付款数相同的多个订单紧密相连时。
HD钱包可以在不知道私钥的情况下派生子公钥,该特性为Gabriel提供了更好的解决方案。Gabriel可以在他的网站上加载一个扩展公钥(xpub),该公钥可为每个客户订单派生一个唯一的地址。Gabriel可以从他的Trezor上花费资金,但加载在网站上的xpub只能生成地址和收取资金。HD钱包的这个特性是个非常好用的安全特性,Gabriel的网站不包含任何私钥,因此不需要高级别的安全性。
为了导出xpub,Gabriel将基于Web的软件与Trezor硬件钱包配合使用。必须插入Trezor设备才能导出扩展公钥。请注意,硬件钱包永远不会导出私钥,这些密钥始终保留在设备上。下图显示了Gabriel用于导出xpub的Web界面。
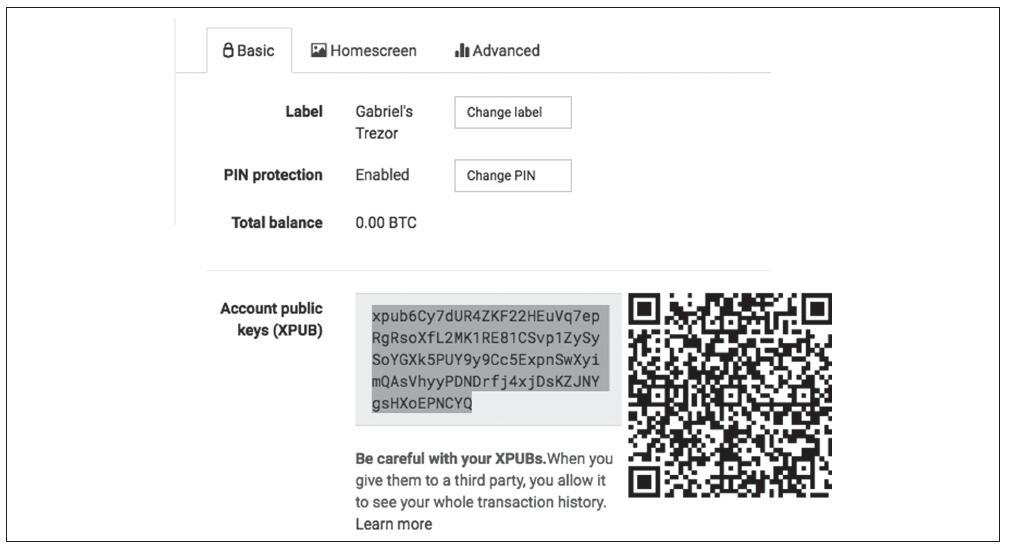
Gabriel将xpub复制到他的比特币购物网店的软件中。他用的是Mycelium Gear,这是一个开源的网店插件,可用于各种网店和CMS系统。Mycelium Gear使用xpub为每个订单生成一个唯一的地址。
1、子私钥强派生
从xpub派生一个分支公钥的能力非常有用,但它有一些潜在的风险。知道xpub并不能访问子私钥。但是,因为xpub包含有链码,所以如果某个子私钥已知,或者被泄露,则可以将其和链码一块派生所有其他的子私钥。一个泄露的子私钥和父链可以推导出所有的子私钥。更糟糕的是,子私钥与父链码可以用来推断父私钥。
为了应对这种风险,HD钱包使用了强派生(hardened derivation)函数来替代原来的派生函数。它可以“打破”父公钥以及子链码之间的关系。这个强派生函数使用了父私钥去推导子链码,而不是父公钥。这就在父/子顺序中创造了一道“防火墙”,拥有链码并不能够用来推算父私钥或者姊妹私钥。强派生函数看起来几乎与正常的派生函数相同,不同之处在于父私钥被用来输入至散列函数而不是父公钥中,如图5-13所示。
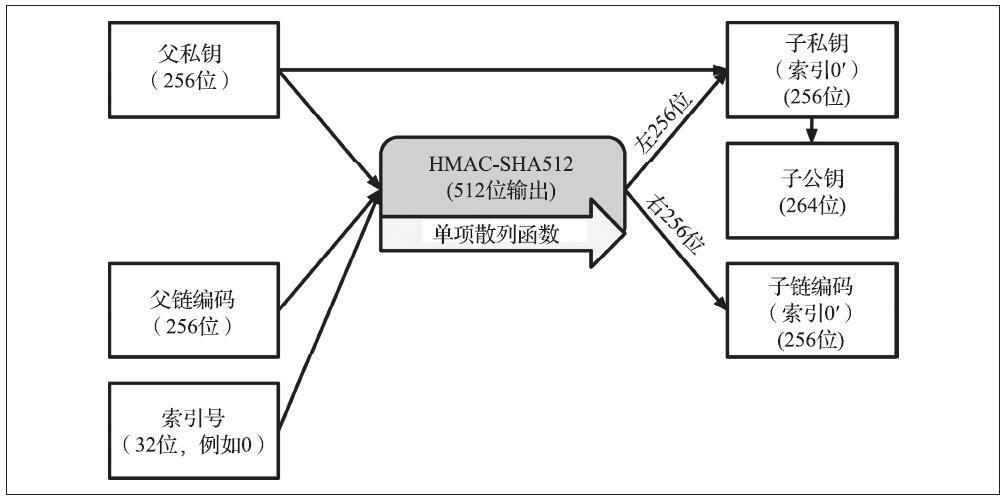
当使用私钥强派生函数时,得到的子私钥以及链码与使用一般派生函数所得到的结果完全不同。得到的私钥“分支”可用于生成不易受攻击的扩展公钥,因为它所含的链码不能用来推导或者暴露任何私钥。强派生也因此被用于密钥树中扩展公钥的上一层以创造“间隙/防火墙”。
简单来说,如果你想使用xpub的便利来派生分支子公钥,而不会使自己面临泄露链码的风险,则应该强派生父节点而不是普通派生父节点。作为最佳实践,为了避免被人推导出主私钥,建议主私钥所衍生的第一层级的子私钥都使用强派生。
2、正常派生和强派生的索引码
用在派生函数中的索引码是32位的整数。为了区分私钥是从常规派生函数还是从强化派生函数中派生出来,索引码的取值分为两个范围。索引码在0和231-1(0x0到0x7FFFFFFF)之间的用于常规派生。索引码在231和232-1(0x80000000到0xFFFFFFFF)之间的用于强派生。因此,索引码小于231就意味着子私钥是常规的,而大于或者等于231的子私钥就是强化型的。
为了让索引码更容易被阅读和显示,强派生的索引号码也是从0开始展示的,但是右上角有一个小撇号。第一个常规子私钥因此被表述为0,但是第一个强化子私钥(索引号为0x80000000)就被表示为0'。第二个强化子私钥的索引码为0x80000001,并显示为1',以此类推。当你看到HD钱包中索引码为i',这就意味值为231+i。
3、HD钱包私钥识别符(路径)
HD钱包中的私钥是用“路径”命名的,且每个级别之间用斜杠(/)字符来表示,下见表。

由主私钥派生出的私钥起始以“m”打头。由主公钥派生的公钥起始以“M”打头。
因此,父私钥生成的第一个子私钥是m/0。第一个子公钥是M/0。第一个子私钥的子私钥就是m/0/1,以此类推。
密钥的“祖先”次序是从右向左读,直到最终派生出它的主密钥。举个例子,标识符m/x/y/z描述的是子私钥m/x/y的第z个子私钥。而子私钥m/x/y又是m/x的第y个子私钥。m/x又是m的第x个子私钥。
4、HD钱包树状结构的导航
HD钱包树状结构提供了极大的灵活性。每一个父扩展密钥都有40亿个子密钥:20亿个常规子密钥和20亿个强化子密钥。而每个子密钥又会有40亿个子密钥并且以此类推。只要你愿意,这个树结构可以无限地派生到无穷代。但是由于有了这个灵活性,对无限的树状结构进行展示就变得异常困难。尤其是对于在不同的HD钱包之间进行迁移,因为内部存在的树状结构的可能性是无穷无尽的。
两个比特币改进建议(BIP)提供了这个复杂问题的解决办法——通过标准化的HD钱包密钥树。BIP-43提出给私钥树强派生第一层某些索引码赋予特殊的含义,便于识别私钥的用途。基于BIP-43,HD钱包应该只用树的第一层级的索引码定义用途,并且将此分支作为该用途专用。举个例子,HD钱包只使用分支m/i'/下的私钥用于索引码“i”定义的特殊用途。
扩展该规范,BIP-44提出了一个多账户结构作为BIP-43下的“目的”编号44'。在BIP-44结构之后的所有高清钱包由于它们只使用树的一个分支而被识别:m/44'/。
BIP-44指定了包含5个预定义树状层级的结构:
m / purpose' / coin_type' / account' / change / address_index
第1层的purpose总是被设定为44'。第2层的“coin_type”特指币种,允许多货币HD钱包中的货币在第二个层级下有自己的子树结构。这是目前已经定义的三种货币:Bitcoin使用m/44'/0'、Bitcoin Testnet使用m/44'/1',以及Litecoin使用m/44'/2'。
树的第3层级是“account”,这允许用户创建多个独立的子账号,便于财务统计或者部门管理。举个例子,一个HD钱包可能包含两个比特币子“账户”:m/44'/0'/0'和m/44'/0'/1'。每个账户都是它自己子树的根。
第4层级就是“change”。每一个HD钱包在这一层都有两个子树,一个用来创建收款地址,另外一个用来创建找零地址。注意无论先前的层级是否使用强派生,这一层级使用的都是常规派生。这是为了允许这一层级的树可以在不安全环境下使用扩展公钥。
被HD钱包派生的可用地址是第4层级的子级,就是第5层级的“address_index”。比如,第一个主账户的第3个收款地址就是M/44'/0'/0'/0/2。
下表展示了更多的例子。

三、交易
比特币交易是比特币系统中最重要的部分。根据比特币系统的设计原理,系统中任何其他的部分都是为了确保比特币交易可以被生成、能在比特币网络中得以传播和通过验证,并最终添加至全球比特币交易总账簿(比特币区块链)。
比特币交易本质上包含交易参与者价值转移的相关信息数据结构。比特币区块链是一本全球复式记账总账簿,每笔交易都是在比特币区块链上的一个公开记录。
交易的底层细节
以”0627052b6f28912f2703066a912ea577f2ce4da4caa5a5fbd8a57286c345c2f2″这笔交易为例,在底层,实际的交易数据看起来与典型的区块浏览器展现的信息非常不同。我们在各种比特币应用程序用户界面中看到的大多数高级信息实际上并不直接存在于比特币系统中。


我们可以使用Bitcoin Core的命令行界面(getrawtransaction和decodeawtransaction)来检索Alice的“原始”交易,对其进行解码,并查看它包含的内容。结果如下:
{
"version": 1,
"locktime": 0,
"vin": [
{
"txid":"7957a35fe64f80d234d76d83a2a8f1a0d8149a41d81de548f0a65a8a999f6f18",
"vout": 0,
"scriptSig":"3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813[A
LL]0484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf",
"sequence":4294967295
}
],
"vout": [
{
"value": 0.01500000,
"scriptPubKey": "OP_DUP OP_HASH160 ab68025513c3dbd2f7b92a94e0581f5d50f654e7 OP_EQUALVERIFY OP_CHECKSIG"
},
{
"value": 0.08450000,
"scriptPubKey": "OP_DUP OP_HASH160 7f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a8 OP_EQUALVERIFY OP_CHECKSIG",
}
]
}你可能会对这笔交易的底层信息存在一些疑问,比如:
- Alice的地址在哪里?
- Bob的地址在哪里?
- Alice发送的0.1个币的“账户”在哪里?
在比特币底层系统里,没有具体的货币,没有发送者,没有接收者,没有余额,没有账户,没有地址。所有这些概念都构建在更高的抽象层次上,是为了让使用者更容易理解比特币。
我们接下来来逐层剖析这些底层概念和原理。
交易的输出和输入
比特币交易的基础组成部分是交易输出(transaction output)。交易输出是不可分割的比特币货币,记录在区块链上,并被整个网络识别为有效。比特币完整节点跟踪所有可用和可消费的输出,称为“未花费的交易输出”(unspent transaction outputs),即UTXO。所有UTXO的集合被称为UTXO集。
UTXO集大小在新的UTXO增加时而增长,并在UTXO被消耗时而缩小。每一个交易都代表UTXO集中的变化(状态转换)。
当我们说用户的钱包已经“收到”比特币时,我们的意思是,钱包已经检测到钱包所控制的密钥可用的UTXO。因此,用户的比特币“余额”是指用户钱包中可用的UTXO总和,而它们可能分散在数百个交易和区块中。用户余额,这个概念是比特币钱包应用创建的。比特币钱包通过扫描区块链并汇聚所有属于该钱包控制的私钥的UTXO来计算该用户的余额。大多数钱包会维护一个数据库或使用数据库服务来存储所有属于钱包私钥的UTXO以便快速引用(查询)。
一个UTXO可以是1“聪”(satoshi)的任意倍数(整数倍)。就像美元的最小单位是表示两位小数的“分”一样,比特币的最小单位是八位小数的“聪”。尽管UTXO可以是任意值,但一旦被生成,就不可分割。这是UTXO值得被强调的一个重要特性:UTXO是面值为“聪”的离散且不可分割的价值单位,一个UTXO只能在一次交易中作为一个整体被消耗。
如果一个UTXO面值大于一笔交易所需,它仍然必须作为整体全部使用,但同时会在交易中生成零头。例如,你有一个价值20比特币的UTXO并且想支付1比特币,那么你的交易必须消耗掉整个20比特币的UTXO,并产生两个输出(UTXO):一个支付了1比特币给接收人,另一个支付了19比特币的找零到你的钱包。由于UTXO的不可分割特性,大部分比特币交易都会产生找零。
想象一下,一位顾客要买1.5元的饮料。她掏出钱包并试图从所有硬币和钞票中找出一种组合来凑齐她要支付的1.5元。如果可能的话,她会选刚刚好的零钱(比如一张1元纸币和5个一毛硬币)或者是小面额的组合(比如3个五毛硬币)。如果都不行的话,她会用一张大面额的钞票,比如5元纸币。如果她把5元给了商店老板,她会得到3.5元的找零,并把找零放回她的钱包以供未来的交易使用。
类似地,一笔比特币交易可以是任意金额,但必须从用户可用的UTXO(不管UTXO的面额是多少)中创建出来。用户不能再把UTXO面额进一步拆分,就像不能把一元纸币撕开而继续当货币使用一样。用户的钱包应用通常会从用户可用的UTXO中进行合适的挑选,来拼凑出一个大于或等于交易所需的金额。
就像现实生活一样,比特币应用可以使用一些策略来满足付款需求:组合若干小额UTXO,并算出准确的找零;或者使用一个比交易额大的UTXO然后进行找零。所有这些将可花费UTXO进行复杂组合的工作都是由用户的钱包自动完成的,对用户来说是不可见的。这些只有在程序化构建来自UTXO的原始交易时才有意义。
交易会消耗先前记录的未使用的UTXO,并创建可供未来交易使用的新的UTXO。通过这种方式,大量的比特币在消费和创建UTXO的交易链中在所有者之间进行转移。
从包含输入与输出的交易链角度来看,有一个特殊交易,被称为“币基交易”(Coinbase Transaction),它是每个区块中的第一笔交易,这笔交易由“获胜”矿工设置,创建全新比特币并支付给该矿工作为采矿奖励。币基交易并不消费UTXO,相反,它有一种称为“coinbase”的特殊类型的输入。这也就是为什么比特币可以在挖矿过程中被创造出来。
输入和输出哪一个是先产生的呢?先有鸡还是先有蛋呢?严格来讲,应先产生输出,因为可以创造新比特币的“币基交易”没有输入,但它可以无中生有地产生输出。
(1)交易输出
每一笔比特币交易都会创造输出,并被比特币账簿(区块链)记录下来。除特例之外,几乎所有的输出都能创造一定数量的可用于支付的比特币,也就是UTXO。这些UTXO被整个网络识别,所有者可在未来的交易中使用它们。
UTXO在UTXO集(UTXOset)中被每一个全节点比特币客户端追踪。新的交易从UTXO集中消耗(花费)一个或多个输出。
交易输出包含两部分:
- 一定量的比特币,面值为“聪”(satoshis)即最小的比特币单位
- 作为花费输出所需条件的加密难题(cryptographic puzzle)
这个加密难题也被称为锁定脚本(locking script)、见证脚本(witness script),或脚本公钥(scriptPubKey)。
现在,我们来深入看看Alice的交易,看看我们是否可以找到并识别输出。在JSON编码中,输出位于名为vout的数组(列表)中:
"vout": [
{
"value": 0.01500000,
"scriptPubKey": "OP_DUP OP_HASH160 ab68025513c3dbd2f7b92a94e0581f5d50f654e7 OP_EQUALVERIFY OP_CHECKSIG"
},
{
"value": 0.08450000,
"scriptPubKey": "OP_DUP OP_HASH160 7f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a8 OP_EQUALVERIFY OP_CHECKSIG",
}
]如你所见,交易包含两个输出。每个输出都由一个值和一个加密难题来定义。
在BitcoinCore显示的编码中,该值显示以bitcoin为单位,但在交易本身中,它被记录为以聪(satoshi)为单位的整数。每个输出的第二部分是设定支出条件的加密难题。Bitcoin Core将其显示为scriptPubKey,并向我们展示了一个可读的脚本表示。
在我们深入研究锁定和解锁UTXO之前,我们需要了解交易输入和输出的整体结构。
交易序列化——输出
当交易数据通过网络传输或在应用程序之间交换时,数据是被序列化过的。序列化是将内部的数据结构表示转换为可以一次发送一个字节的格式(也称为字节流)的过程。序列化最常用于编码通过网络传输或用于文件中存储的数据结构。
交易输出的序列化格式如下表所示。

大多数比特币函数库和架构不会在内部将交易存储为字节流,因为每次需要访问单个字段时,都需要复杂的解析。为了方便和可读性,比特币函数库将交易内部存储在数据结构(通常是面向对象的结构)中。
- 从交易的字节流表示转换为函数库的内部数据结构表示的过程称为反序列化或交易解析。
- 转换回字节流以通过网络传输、散列化(hashing)或存储在磁盘上的过程称为序列化。
大多数比特币函数库具有用于交易序列化和反序列化的内置函数。
我们来看看从十六进制表示的序列化数据中手动解码出Alice的交易,找到我们之前提到的元素。
0100000001186f9f998a5aa6f048e51dd8419a14d8a0f1a8a2836dd734d2804fe65fa35779000000008b483045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e381301410484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adfffffffff0260e31600000000001976a914ab68025513c3dbd2f7b92a94e0581f5d50f654e788acd0ef8000000000001976a9147f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a888ac 00000000
- 0.015比特币的价值是1,500,000聪,可由十六进制16 e360表示
- 在序列化交易时,16 e360会以小端序(little-endian,最低有效字节优先)进行编码,所以它看起来像60 e316
- scriptPubKey的长度为25个字节,25在十六进制中的值为19
(2)交易输入
交易输入将UTXO(通过被引用)标记为将被消费,并通过解锁脚本提供所有权证明。
要构建一个交易,钱包从它控制的UTXO中来选择足够的面值来执行被请求的付款。有时一个UTXO就够了,其他时候需要更多。对于将用于此付款的每个UTXO,钱包将创建交易输入,指向此UTXO,并使用解锁脚本解锁它。
让我们更详细地看看交易输入的组成部分。
- 输入的第一部分是通过引用UTXO记录在区块链中的交易散列值和序号来指向UTXO的指针。
- 第二部分是一个解锁脚本,钱包构建它是为了满足UTXO中设置的消费条件。通常,解锁脚本是一个证明比特币所有权的数字签名和公钥。但是,并非所有解锁脚本都包含签名。
- 第三部分是序列号。
这是我们在之前在上一小节中提到的例子。交易输入是一个名为vin的数组(列表):
"vin": [
{
"txid":"7957a35fe64f80d234d76d83a2a8f1a0d8149a41d81de548f0a65a8a999f6f18",
"vout": 0,
"scriptSig":"3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813[A
LL]0484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf",
"sequence":4294967295
}
], 如你所见,列表中只有一个输入(因为这个UTXO包含足够面值来完成此付款,这个输入是之前区块的输出)。输入包含四个元素:
- 一个交易ID,引用包含正在使用的UTXO的交易
- 一个输出索引(vout),用于标识来自该交易中的第几个UTXO被引用(第一个为零)
- 一个scriptSig(解锁脚本),满足放置在UTXO上的支付条件,解锁支出
- 一个序列号
在Alice的交易中,输入指向的交易ID是:
7957a35fe64f80d234d76d83a2a8f1a0d8149a41d81de548f0a65a8a999f6f18
输出索引是0(即由该交易创建的第一个UTXO)。
解锁脚本由Alice的钱包构建,钱包首先检索引用的UTXO,检查其锁定脚本,然后根据锁定要求来构建所需的解锁脚本。
仅仅看这个输入,你可能已经注意到,除了了解包含它引用的交易之外,我们无从了解这个UTXO的任何内容。我们不知道它的价值(金额是多少聪),我们不知道设置支出条件的锁定脚本。要找到这些信息,我们必须通过检索整个交易来检索被引用的UTXO。请注意,由于输入的值未明确说明,因此我们还必须使用被引用的UTXO来计算在此交易中支付的费用。
不仅仅是Alice的钱包需要检索输入中引用的UTXO。一旦将该交易广播到网络,每个验证节点也将需要检索交易输入中引用的UTXO,以验证该交易。这体现了一种分布式验证的思想,所有的鉴权都通过区块链分布式验证,不信任任何的交易对手或者第三方,而区块链本身的可信度又建立在历史CPU算力的累计上。
因为缺少上下文,交易本身似乎不完整。交易在其输入中引用UTXO,但不检索该UTXO,我们无法知道输入的值或锁定条件。在编写比特币软件时,只要你想验证交易或计算交易费用或检查解锁脚本,你的代码必须首先从区块链中检索引用的UTXO,以便构建隐含但不存在上下文输入的UTXO引用。例如,要计算交易费用时,必须知道输入值总和与输出值总和。但是,如果不检索输入中引用的UTXO,我们就不知道输入的值。
因此,像单个交易中计算交易费用这样看似简单的操作事实上涉及多个交易的多个步骤和数据。
仔细品读比特币在这个问题上宏大而美妙的设计思想:
- 尽管“聪”是比特币的最小面值单位,但是“交易(UTXO)”是流通中的最小处理单位,因为在比特币中并不存在一个强力第三方机构负责对所有的“交易(UTXO)”进行汇总、结算、清账、分割等操作。一个交易中的比特币只能一次性作为输入。
- 所有的“比特币”,或者说“价值”,都通过“交易(UTXO)”在整个比特币网络上进行所有权(由秘钥提供证明)的的流转,不存在凭空出现的比特币,通过检索整个网络的所有“交易(UTXO)”,每一个比特币都可以追溯到源头以及流转路径。
- 交易的双方,并不需要对方提供任何证明,也不需要向第三方寻求证明,相反,交易的输入方只是标明用于支付所涉及的“交易(UTXO)”,并且通过提供解锁脚本证明自己拥有该“交易(UTXO)”的归属权(由密码学保证)。同时,用于支付所涉及的“交易(UTXO)”的真实性,建立在整个区块链本身的算力证明上,这是一种共识机制的体现。
我们可以使用与利用Bitcoin Core检索Alice的事务时相同的命令序列(getraw-transaction和decoderawtransaction)。通过这个,我们可以得到前面输入中引用的UTXO,并查看相应的数据。输入中引用的来自Alice以前的交易中的UTXO:
"vout": [
{ "value": 0.10000000,
"scriptPubKey": "OP_DUP OP_HASH 1607f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a8 OP_EQUALVERIFY OP_CHECKSIG"
}
]我们看到这个UTXO的值为0.1BTC,并且它有一个包含“OP_DUP OP_HASH160…”的锁定脚本(scriptPubKey)。
为了充分了解Alice的交易,我们必须检索引用以前的交易作为输入。检索以前的交易和未花费的交易输出的函数是非常普遍的,并且存在于几乎每个比特币函数库和API中。
交易序列化——交易输入
当交易被序列化以在网络上传输时,它们的输入被编码成字节流,如下表所示。

与输出一样,我们来看看是否可以从序列化格式的Alice的交易中找到输入。首先,将输入解码:
"vin": [
{
"txid":"7957a35fe64f80d234d76d83a2a8f1a0d8149a41d81de548f0a65a8a999f6f18",
"vout": 0,
"scriptSig":"3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813[A
LL]0484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adf",
"sequence":4294967295
}
],现在,我们来看看我们是否可以识别下面这些以十六进制表示法表示的字段:
0100000001186f9f998a5aa6f048e51dd8419a14d8a0f1a8a2836dd734d2804fe65fa35779000000008b483045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e381301410484ecc0d46f1918b30928fa0e4ed99f16a0fb4fde0735e7ade8416ab9fe423cc5412336376789d172787ec3457eee41c04f4938de5cc17b4a10fa336a8d752adfffffffff0260e31600000000001976a914ab68025513c3dbd2f7b92a94e0581f5d50f654e788acd0ef8000000000001976a9147f9b1a7fb68d60c536c2fd8aeaa53a8f3cc025a888ac00000 000
- 交易ID以反转字节顺序序列化(小端序列化),因此以(十六进制)18开头,以79结尾
- 输出索引为4字节组的“0”,容易识别
- scriptSig的长度为139个字节,十六进制为8b
- 序列号设置为FFFFFFFF,也容易识别
(3)交易费
大多数交易包括交易费(矿工费),以补偿比特币矿工在保障网络安全的付出。费用本身也可以作为一种安全机制,因为攻击者通过海量交易攻击网络在经济上是不可行的。
本节解释交易费是如何被包含在一个典型的交易中的。大多数钱包自动计算并计入交易费。但是,如果你以编程方式构造交易或使用命令行界面,必须手动计算并计入交易费。
交易费作为矿工打包(挖矿)一笔交易到下一个区块中的一种激励;同时作为一种抑制因素,通过对每一笔交易收取小额费用来防止对系统的滥用。成功挖到某区块的矿工将得到该区内包含的交易费,并将该区块添加至区块链中。
交易费是以千字节为单位计算的,而不是比特币交易的金额。总体而言,交易费是由比特币网络中的市场行为决定。矿工会依据许多不同的标准(包括费用)对交易进行优先级排序,甚至可能在某些特定情况下免费处理交易。但大多数情况下,交易费影响处理优先级,这意味着有足够费用的交易费更可能被打包进下一个挖出的区块中;而交易费不足或者没有交易费的交易可能会被推迟,基于尽力而为的原则在几个区块之后被处理,甚至可能根本不被处理。交易费不是强制的,而没有交易费的交易最终也可能会被处理,但是交易费将提高处理优先级。
随着时间的推移,交易费的计算方式以及在交易处理优先级上的权重已经产生了变化。起初,交易费用在整个网络中是固定不变的。渐渐地,随着网络容量和交易量的不断变化,可能受到来自市场力量的影响,收费结构开始变化。至少从2016年年初开始,比特币的容量限制已经在交易之间形成了竞争,导致了更高的交易费,免费交易彻底成为过去式。零费用或非常低费用的交易鲜少被处理,有时甚至不会在网络上传播。
在Bitcoin Core中,交易传输费用策略由选项设置。目前默认的minrelaytxfee是0.00001比特币或者千字节百分之一毫比特币。因此,minrelaytxfee在默认情况下,交易费用低于0.0001比特币将被视为免费,但只有在mempool(交易池)有空间时才会被转发;否则,会被丢弃。比特币节点可以通过调整minrelaytxfee的值来覆盖默认的交易传输费用策略。
任何创建交易的比特币服务,包括钱包、交易所、零售应用等,都必须实现交易费动态计算功能。交易费动态计算可以通过第三方费用估算服务或内置的费用估算算法来实现。如果你不确定如何实现,可以从使用第三方服务开始学习相关经验以便将来实现自己的算法来去除第三方依赖。
费用估算算法根据容量和“竞争”交易提供的费用计算适当的费用。这些算法的范围从简单(最后一个区块的平均费用或中值费用)到复杂的(统计分析)。算法估计必要的费用(以聪/字节为单位),这将使交易被选中并打包在后续一定数量的区块内的可能性很高。大多数服务为用户提供选择高、中、低优先级费用的选项。
- 高优先级意味着用户支付更高的费用,但交易很可能会打包在下一个区块中。
- 中等和低优先级意味着用户支付较低的交易费用,但交易可能需要更长时间才能确认。
许多钱包应用程序使用第三方服务进行费用计算。一个流行的服务是http://bitcoinfees.21.co,它提供了一个API和一个可视化图表,以聪/字节为单位显示了不同优先级的费用。
固定费用在比特币网络上不再可行。设置固定费用的钱包将导致用户体验不佳,因为交易往往会被“卡住”,并不被确认。不了解比特币交易和费用的用户因交易被“卡住”而感到沮丧,因为他们认为自己已经丢失资金。
费用估算服务bitcoinfees.21.co中的下图显示了10个satoshi/byte增量的费用的实时估计,以及每个范围的费用交易的预期确认时间(以分钟和块数表示)。
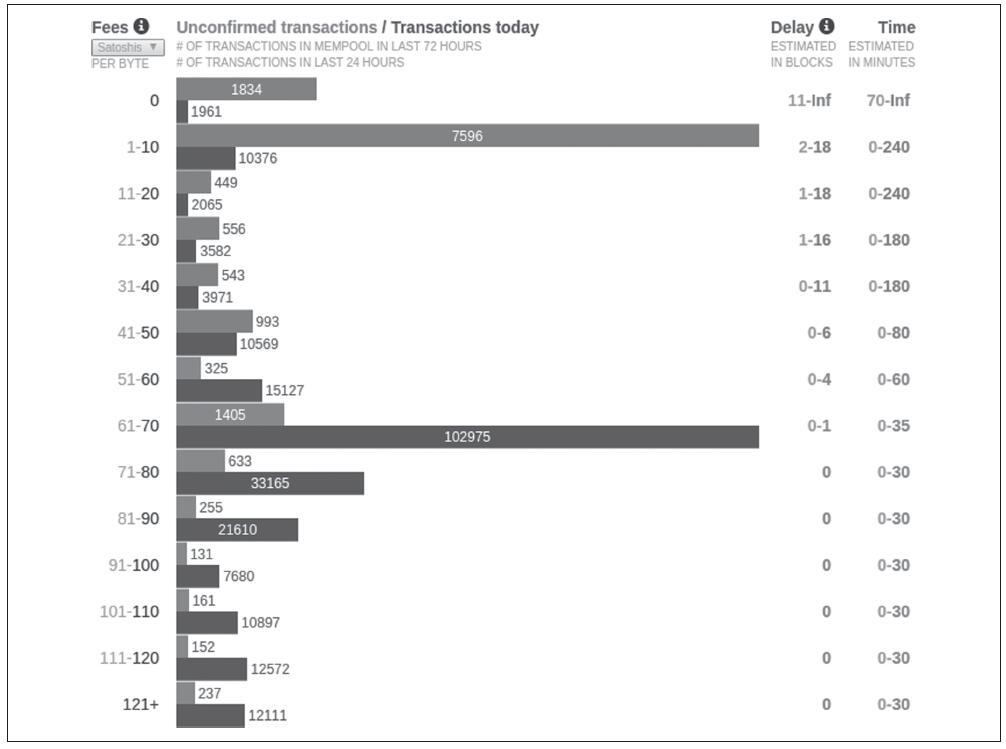
对于每个收费范围(例如,61~70聪/字节),两个水平栏显示过去24小时(102,975)费用在该范围内未确认交易的数量(1405)和交易总数。根据图表,此时推荐的高优先费用为80聪/字节,这可能导致交易在下一个块(零块延迟)中开采。据合理判断,一笔常规交易的大小约为226字节,因此单笔交易建议费用为18,080聪(0.00018080 BTC)。
费用估算数据可以通过简单的HTTP RESTAPI(https://bitcoinfees.21.co/api/v1/fees/recommended)来检索。例如,在命令行中使用curl命令:
$ curl https://bitcoinfees.21.co/api/v1/fees/recommended
{"fastestFee":80,"halfHourFee":80,"hourFee":60}API通过费用估算以聪/字节的方式返回一个JSON对象,从而实现“最快确认”(fastestFee),以及在三个块(halfHourFee)和六个块(hourFee)内确认。
(4)把交易费加入到交易中
交易的数据结构里并没有交易费的字段,相反,交易费隐含于总输入和总输出之间的差额。从所有输入中扣掉所有输出后剩余的金额会被矿工作为矿工费收走:
交易费 = 求和(所有输入) - 求和(所有输出)
交易费有点令人困惑,但又尤为重要。因为如果你正在构建自己的交易,必须确保你没有因疏忽而将不应花费的输入变成了巨额交易费。这意味着你必须考虑所有输入,如有必要则加上找零,否则你会给矿工一笔相当可观的劳务费!
举例来说,如果你在消耗了一个20比特币的UTXO来完成1比特币的付款,在交易中你必须包含一笔19比特币的找零回到你的钱包。否则,那剩下的19比特币会被当作交易费,并将由挖出你交易的矿工收走。尽管你会得到高优先级的打包处理,并且让矿工喜出望外,但这很可能并不是你想要的。
如果你忘了在手动构建的交易中增加找零的输出,系统会把找零当作交易费来处理。“不用找了!”也许不是你的真实意愿。
让我们重温一下Alice在咖啡店的交易来看看在实际中交易是如何运作的。Alice想花0.015比特币购买咖啡。为了确保这笔交易能被立即处理,她希望包含交易费用,例如0.001。这意味着总花费会变成0.016。因此她的钱包需要凑齐一个或者多个UTXO使总和为0.016或更多,如有必要,可以创建找零。我们假设她的钱包里有一个0.2比特币的UTXO可用。她的钱包就会消耗掉这个UTXO,创建一个0.015的输出给Bob的咖啡店,第二个0.184比特币的输出作为找零回到Alice的钱包,并留下未分配的0.001比特币作为交易的隐含费用。
现在让我们看看另一种情况。在菲律宾的儿童慈善总监Eugenia已经完成了为儿童购买教科书的筹款活动。她收到了来自世界各地的数千份的小额捐款,共计50比特币,所以她的钱包充满了非常小的捐款(UTXO)。现在她想用比特币从本地出版商处购买数百本教科书。
由于Eugenia的钱包应用试图构建一个较大的付款交易,因此它必须从可用的UTXO集合中获取,但该集合由许多较小金额的UTXO组成。这意味着由此产生的交易将会由超过一百个小型UTXO作为输入,但只有一个输出用来付给出版商。具有大量输入的交易将大于1000字节,也许是1000字节或几千字节大小。因此,它需要比平均大小的交易高得多的费用。
Eugenia的钱包应用会通过计算交易的大小并乘以每千字节需要的费用来计算适当的交易费。很多钱包会支付较大的交易费,以确保交易得到及时处理。更高的交易费不是因为Eugenia要付的钱很多,而是因为她的交易很复杂导致数据量大——交易费与交易的比特币价值无关的。
交易脚本和脚本语言
比特币交易脚本语言称为脚本,是一种类似Forth的基于栈执行的逆波兰表达式语言。
放置在UTXO上的锁定脚本和解锁脚本都是用这种脚本语言编写的。当一笔比特币交易被验证时,每一个输入中的解锁脚本将与其对应的锁定脚本一起执行,以确定这笔交易是否满足支付条件。
脚本是一种非常简单的语言,功能被设计的比较有限,可在很多硬件上运行,如简单的嵌入式设备也可以运行。它只能做很少的操作,并且不能完成许多现代编程语言能够做的事情。但用于验证可编程货币,这是一个深思熟虑的安全设计。
如今,大多数经比特币网络处理的交易是以“支付给Bob的比特币地址”的形式存在,并且基于称为“P2PKH”(Pay-to-Public-Key-Hash)的脚本。但是,比特币交易不局限于“支付给Bob的比特币地址”的脚本。事实上,锁定脚本可以被编写成表达各种复杂的情况。为了理解这些更为复杂的脚本,我们必须首先了解交易脚本和脚本语言的基础知识。
在本小节中,我们将会演示比特币交易脚本语言的基本组件,并说明如何使用它去表达简单的支出条件以及解锁脚本如何满足这些条件。
比特币的交易验证并不是静态不变的,而是通过脚本语言的执行来实现的。这种脚本语言允许表达几乎无限的各种条件。这也是比特币作为一种“可编程的货币”所拥有的力量。
(1)非图灵完备性
比特币脚本语言包含许多操作码,但是故意在一个重要方面做了限制——除了有条件的流控制以外,没有循环或复杂流程控制能力。这使得脚本语言是非图灵完备的,这意味着脚本复杂性和执行次数都是有限的。脚本不是通用语言,这些限制确保了这些语言不能用于创建无限循环或其他形式的“逻辑炸弹”,这种逻辑炸弹可能嵌入事务中,从而导致对比特币网络的拒绝服务攻击。
请记住,每一笔交易都会被网络中的全节点验证,受限制的语言能防止交易验证机制被作为一个漏洞而加以利用。
(2)无状态验证
比特币交易脚本语言是无状态的,因为在执行脚本之前没有状态,在执行脚本之后也不保存状态。因此,执行脚本所需的所有信息都包含在脚本中。
可以保证的是,一个脚本在任何系统上都会以相同的方式执行。如果你的系统成功验证了一个脚本,你可以确定比特币网络中的其他每个系统都会成功验证此脚本,这意味着有效的交易对每个人都有效,而且每个人都知道这一点。这种结果一致性是比特币系统的一项至关重要的优秀特性。
(3)脚本构建(锁定与解锁)
比特币的交易验证引擎依赖于两类脚本来验证比特币交易:
- 锁定脚本
- 解锁脚本
锁定脚本是一个放置在输出上面的花费条件:它指定了今后花费这笔输出必须要满足的条件。历史上,锁定脚本被称为scriptPubKey,因为锁定脚本往往含有一个公钥或比特币地址(公钥散列值)。由于认识到这种脚本技术存在着更为广泛的应用场景,因此我们将它称为“锁定脚本”(locking script)。在大多数比特币应用程序中,我们所称的“锁定脚本”将以scriptPubKey的形式出现在源代码中。你还将看到被称为见证脚本(witnessscript)的锁定脚本,或者更一般地将其视为一个密码难题(crypto graphic puzzle)。这些术语都意味着同样的东西,只是在不同的抽象层次上的称谓。
解锁脚本是“解决”或满足输出上锁定脚本设定的花费条件并允许花费输出的脚本。解锁脚本是每个交易输入的一部分,而且往往含有一个由用户的比特币钱包(通过用户的私钥)生成的数字签名。历史上,解锁脚本被称为scriptSig,因为解锁脚本常常包含一个数字签名。在大多数比特币应用的源代码中,scriptSig便是我们所说的解锁脚本。你还将看到被称为解锁脚本的见证脚本。在本文中,我们将它称为“解锁脚本”,以对应有更多使用场景的锁定脚本,同时并非所有解锁脚本都一定会包含签名。
每个比特币验证节点将通过一起执行锁定和解锁脚本来验证交易。每个输入都包含一个解锁脚本,并引用先前存在的UTXO。验证软件将复制解锁脚本,检索输入引用的UTXO,并从该UTXO复制锁定脚本。然后按顺序执行解锁和锁定脚本。如果解锁脚本满足锁定脚本条件,则输入有效。所有输入都是独立验证的,作为交易整体验证的一部分。
请注意,UTXO会永久记录在区块链中,因此它是不会变化的,并且不受在新交易中引用失败的尝试的影响。只有正确满足输出条件的有效交易才能将输出视为“已用完”,并从未使用的交易输出集(UTXO集)中移除。
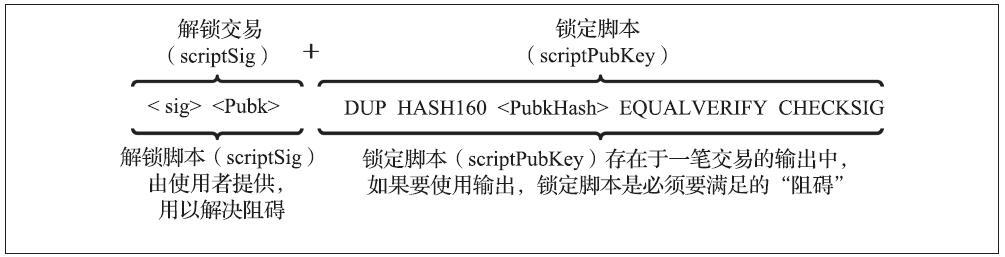
下图是最常见类型的比特币交易(P2PKH,对公钥散列的付款)的解锁和锁定脚本的示例,显示了在脚本验证之前将解锁脚本和锁定v脚本连接起来的组合脚本。
1、脚本执行栈
比特币的脚本语言是一种基于栈的语言,因为它使用被称为栈的数据结构。栈是一个非常简单的数据结构,可以将其视为一叠卡片。栈允许两个操作:push和pop。
- push会在栈顶部添加一个项目。
- pop从栈中删除顶层项目。
栈上的操作只能作用于栈中最顶端的项目。栈数据结构也被称为“后进先出”(Last-In-First-Out)或“LIFO”队列。
脚本语言通过从左到右处理每个项目来执行脚本。数字(数据常量)被推到栈上。操作码(Operators)从栈中推送或弹出一个或多个参数,对其执行操作,并可能将结果推送到栈上。例如,操作码OP_ADD将从栈中弹出两个项目,添加它们,并将结果的总和推送到栈上。
条件操作码(Conditional operators)对一个条件进行计算,产生一个TRUE或FALSE的布尔结果(boolean result)。例如,OP_EQUAL从栈中弹出两个项目,如果它们相等,则推送为TRUE(由数字1表示),否则推送为FALSE(由数字0表示)。
比特币交易脚本通常包含一个条件操作码,以便它们可以生成表示有效事务的TRUE结果。
2、一个简单的脚本
现在让我们将学到的关于脚本和栈的知识应用到一些简单的例子中。
如下图所示,脚本23 OP_ADD 5 OP_EQUAL演示了算术加法操作码OP_ADD,该操作码将两个数字相加,然后把结果推送到栈,后面的条件操作码OP_EQUAL是验算之前的和是否等于5。为了简化起见,前缀OP_在逐步演示过程中将被省略。
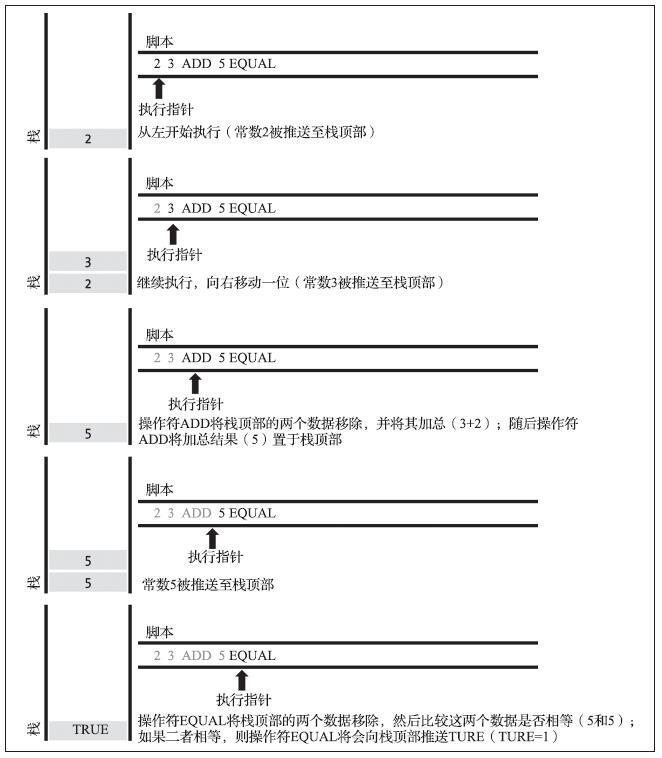
尽管绝大多数锁定脚本都指向一个公钥散列值(本质上就是比特币地址),因此需要所有权证明来支付资金,但脚本本身并不需要如此复杂。任何解锁和锁定脚本的组合只要其结果为真(TRUE),则有效。前面被我们用于说明简单算术操作码的脚本示例同样也是一个有效的锁定脚本,该脚本能用于锁定交易输出。
使用部分示例脚本作为锁定脚本:
3 OP_ADD 5 OP_EQUAL
通过包含以下解锁脚本的输入能满足该脚本:
2
验证软件将锁定和解锁脚本组合起来(解锁脚本+锁定脚本),最终脚本是:
2 3 OP_ADD 5 OP_EQUAL
正如在上图中所看到的,当脚本被执行时,结果是OP_TRUE,交易有效。不仅该笔交易的输出锁定脚本有效,同时UTXO也能被任何知晓这个运算技巧(知道是数字2)的人所使用。
如果栈顶部结果为TRUE(标记为{0x01}),任何其他非零值或脚本执行后栈为空,则交易有效。如果栈顶部的结果显示为FALSE(0字节空值,标记为{})或者脚本执行由运算符(如OP_VERIFY,OP_RETURN或OP_ENDIF等条件终止符)明确停止,则事务无效。
以下是一个稍微复杂一点的脚本,它用于计算2+7-3+1。注意,当脚本在同一行包含多个操作码时,栈允许一个操作码的结果由下一个操作码执行。
2 7 OP_ADD 3 OP_SUB 1 OP_ADD 7 OP_EQUAL
请尝试使用笔和纸张验证前面的脚本。当脚本执行结束时,你应该在栈上保留TRUE值。
3、单独执行解锁和锁定脚本
在最初版本的比特币客户端中,解锁和锁定脚本被连接并按顺序执行。出于安全因素考虑,在2010年进行修改,原因是存在一个恶意解锁脚本将数据推送到栈并破坏锁定脚本的漏洞。在当前的实现中,这两个脚本是随着栈的传递被分别执行的,下面将会详细介绍。
首先,使用栈执行引擎执行解锁脚本。如果解锁脚本在执行过程中未报错(例如,它没有遗留“悬挂”操作码),则主栈(不是备用栈)被复制并执行锁定脚本。如果使用从解锁脚本复制的栈数据执行锁定脚本的结果为“TRUE”,那么解锁脚本就成功地满足了锁定脚本所设置的条件,因此,该输入是有效的授权UTXO。如果在执行组合脚本后仍然存在除“TRUE”之外的任何结果,则输入无效,因为它未能满足放置在UTXO上的支付条件。
(4)P2PKH
比特币网络处理的大多数交易花费的都是由“付款至公钥散列”(Pay-to-Public-Key-Hash)脚本锁定的输出,这些输出都包含一个锁定脚本,将输入锁定为一个公钥散列(hash)值,即我们常说的比特币地址。由P2PKH脚本锁定的输出可以通过提供一个公钥和由相应私钥创建的数字签名来解锁(使用)。
例如,我们可以再次回顾一下Alice向Bob咖啡馆支付的案例。Alice下达了向Bob咖啡馆的比特币地址支付0.015比特币的支付指令,该笔交易的输出锁定脚本如下所示:
OP_DUP OP_HASH160 <Cafe Public Key Hash> OP_EQUALVERIFY OP_CHECKSIG
脚本中的Cafe Public Key Hash即为咖啡馆的比特币地址,但该地址不是基于Base58-Check编码。事实上,大多数比特币地址的公钥散列值都显示为十六进制码,而不是大家所熟知的基于Base58Check编码的以1开头的比特币地址。
上述锁定脚本相应的解锁脚本是:
<Cafe Signature> <Cafe Public Key>
将两个脚本结合起来可以形成如下的组合验证脚本:
<Cafe Signature> <Cafe Public Key> OP_DUP OP_HASH160 <Cafe Public Key Hash> OP_EQUALVERIFY OP_CHECKSIG
只有当解锁脚本与锁定脚本的设定条件相匹配时,执行组合验证脚本时才会显示结果为真(TRUE)。换句话说,只有当解锁脚本包含了咖啡馆的有效签名,交易执行结果才会通过(结果为真),该有效签名是从与公钥散列相匹配的咖啡馆的私钥中所获取的。
下图显示了组合脚本如何一步步检验交易有效性的过程。
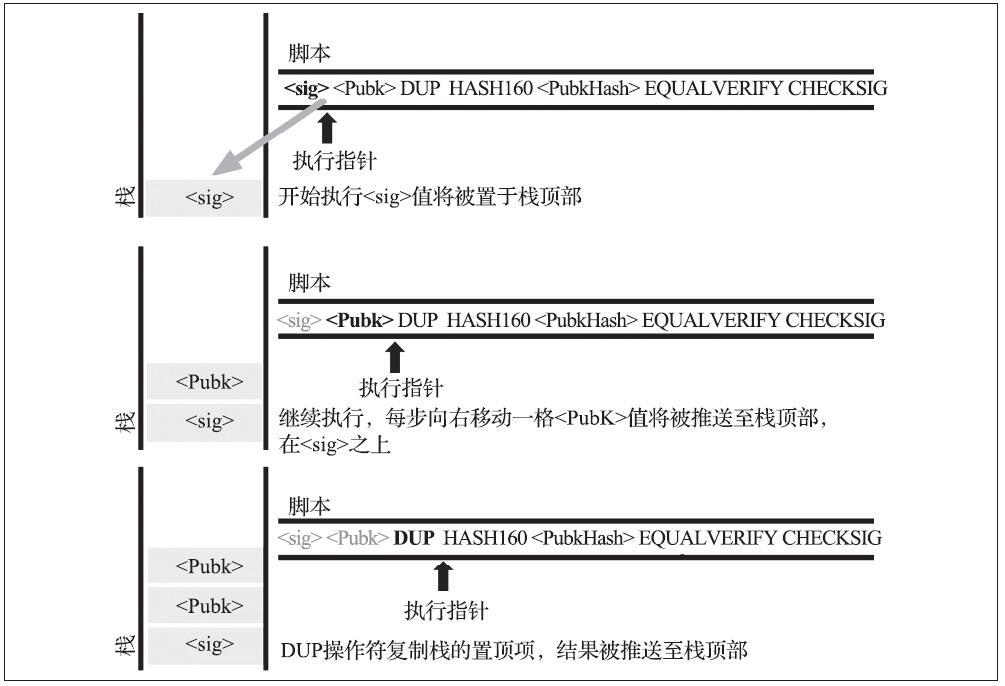
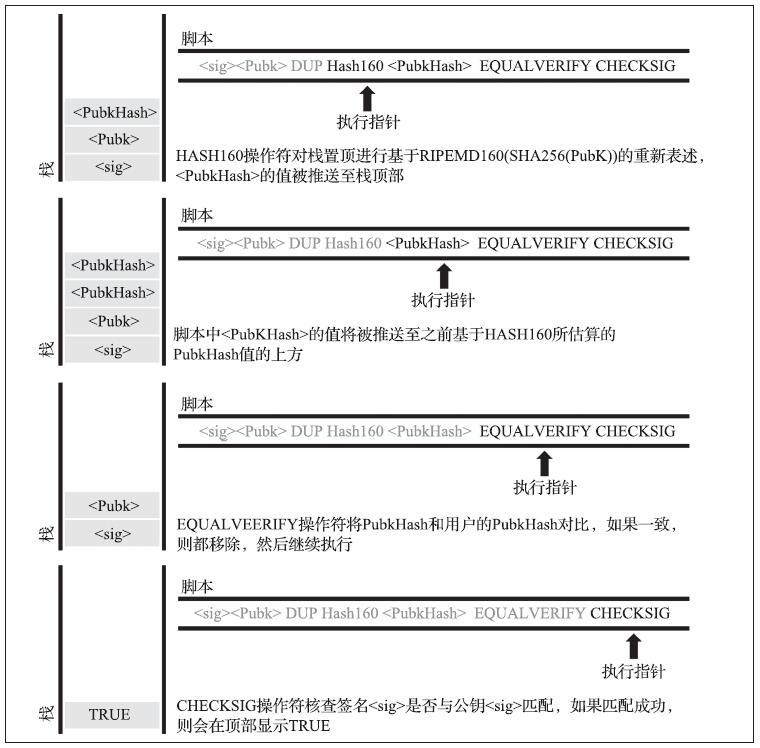
注意,这个解锁过程的栈执行过程有几点值得注意:
- 所有的交易区块都需要接受整个区块链节点的共同验证,因此,发起解锁的一方需要通过非对称加密的方式,“证明”自己的确拥有该交易的属主权限。
- 锁定脚本中的核心操作是“授权”,通过将被授权对象的公钥进行签名,借助非对称加密算法实现了授权过程。
- 在整个脚本执行过程中,被“授权”的一方的公钥分别在两个地方进行计算:1)用于标明对应比特币的授权对象;2)用于被授权对象进行自我证明就是被授权的属主
总体来看,「解锁」+「加锁」的脚本执行过程,相互咬合成了一个紧密结合的验证连,将交易双方的授权和证明过程绑定在了一起,一笔UTXO在一个交易中被标识消费出去后(锁定),在另一个交易中被引入(先解锁)用于后续的消费(再加锁)。这样,UTXO就形成一个无限延长的链条,在整个区块链上不断传播。
数字签名(ECDSA)
到目前为止,我们还没有深入探讨“数字签名”的细节。在本节中,我们将探讨数字签名如何工作,以及如何在不泄露私钥的情况下提供私钥所有权的证明。
比特币中使用的数字签名算法是椭圆曲线数字签名算法(Elliptic Curve DigitalSignature Algorithm,ECDSA)。ECDSA是用于基于椭圆曲线私钥/公钥对的数字签名的算法。
ECDSA由脚本函数OP_CHECKSIG、OP_CHECKSIGVERIFY、OP_CHECKMULTISIG和OP_CHECKMULTISIGVERIFY使用。任何时候你在锁定脚本中看到这些时,解锁脚本都必须包含一个ECDSA签名。
数字签名在比特币中有三种用途。
- 第一,签名证明私钥的所有者,即资金所有者,已经授权支出这些资金。
- 第二,授权证明是不可否认的(不可否认性)。
- 第三,签名证明交易(或交易的特定部分)在签名之后没有也不能被任何人修改。
请注意,交易的每个输入都是独立签名的。这一点至关重要,因为多个签名和输入都不属于同一位“所有者”或被同一位“所有者”使用。事实上,一个名为“CoinJoin”的特定交易方案(多人混合交易方案)就使用这个特性来创建多方交易来保护隐私。
交易的每个输入和它可能包含的任何签名完全独立于任何其他输入或签名。多方可以协作构建交易,并各自仅签一个输入。
维基百科对“数字签名”的定义 数字签名是用于证明数字消息或文档的真实性的数学方案。有效的数字签名给了一个容易接受的理由去相信:
1)该消息是由已知的发送者(身份认证性)创建的;
2)发送方不能否认已发送消息(不可否认性;
3)消息在传输中未被更改(完整性)。
(1)数字签名如何工作
数字签名是一种由两部分组成的数学方案:
- 第一部分是使用私钥(签名密钥)从消息(交易)创建签名的算法
- 第二部分是允许任何人在给定消息和公钥时验证签名合法性的算法
1、创建数字签名
在比特币的ECDSA算法实现中,被签名的“消息”是交易,或者更准确地说是交易中特定数据子集的散列。签名密钥是用户的私钥。结果是签名:
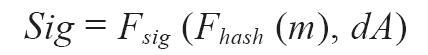
- dA是签名私钥
- m是交易(或其部分)
- Fhash是散列函数
- Fsig是签名算法
- Sig是结果签名
函数Fsig产生由两个值组成的签名Sig,通常称为R和S:
Sig = (R, S)
现在已经计算了两个值R和S,它们被序列化为字节流,使用一种称为“分辨编码规则”(Distinguished Encoding Rules)或DER的国际标准编码方案。
2、签名序列化(DER)
我们再来看看Alice创建的交易。在交易输入中有一个解锁脚本,其中包含Alice的钱包中的以下DER编码签名:
3045022100884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb02204b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e381301
该签名是Alice的钱包生成的R和S值的序列化字节流,证明她拥有授权花费该输出的私钥。序列化格式包含以下9个元素:
- 0x30表示DER序列的开始
- 0x45表示序列的长度(69字节)
- 0x02表示一个整数值
- 0x21表示整数的长度(33字节)
- R——00884d142d86652a3f47ba4746ec719bbfbd040a570b1deccbb6498c75c4ae24cb
- 0x02表示另一个整数值
- 0x20表示整数的长度(32字节)
- S——4b9f039ff08df09cbe9f6addac960298cad530a863ea8f53982c09db8f6e3813
- 后缀(0x01)指示使用的散列的类型(SIGHASH_ALL)
重要的数字是R和S;其余的数据是DER编码方案的一部分。
(2)验证签名
要验证签名,必须有签名(R和S)、序列化交易和公钥(对应于用于创建签名的私钥)。
本质上,签名的验证意味着“只有生成此公钥的私钥的所有者,才能在此交易上产生此签名。”
签名验证算法采用消息(交易或其部分的散列值)、签名者的公钥和签名(R和S值),如果签名对该消息和公钥有效,则返回TRUE值。
(3)签名散列类型(SIGHASH)
数字签名被应用于消息,在比特币中,就是交易本身。签名意味着签名者对特定交易数据的承诺(commitment)。在最简单的形式中,签名适用于整个交易,从而承诺所有输入、输出和其他交易字段。但是,一个签名可以只承诺交易中的一部分数据,这对于我们将在本节中看到的许多场景是有用的。
比特币签名有一种方法,用于通过使用SIGHASH标志来指示交易数据的哪一部分包含在由私钥签名的散列中。SIGHASH标志是附加到签名的单个字节。每个签名都有一个SIGHASH标志,并且该标志从输入到输入可以不同。具有三个签名输入的交易可以有三个带有不同SIGHASH标志的签名,每个签名签署(承诺)交易的不同部分。
请记住,每个输入可能在其解锁脚本中包含一个签名。因此,包含多个输入的交易可能具有带有不同SIGHASH标志的签名,这些标志在每个输入中承诺交易的不同部分。还要注意的是,比特币交易可能包含来自不同“所有者”的输入,他们在部分构建(和无效)的交易中可能仅签署一个输入,继而与他人协作收集所有必要的签名后再使交易生效。许多SIGHSASH标志类型,只有在你考虑到由许多参与者在比特币网络之外共同协作去更新部分签名的交易才具有意义。
有三个SIGHASH标志:ALL、NONE和SINGLE。如表6-3所示。

另外,还有一个修饰符标志SIGHASH_ANYONECANPAY,它可以与前面的每个标志组合使用。当设置ANYONECANPAY时,只有一个输入被签名,剩下的(和它们的序列号)打开以进行修改。ANYONECAN PAY的值为0x80,按位或运算,结果如下表所示。

在签名和验证过程中应用SIGHASH标志的方式是:使用交易的副本并删除其中的某些字段(将其设置为零长度并清空),将生成的交易序列化,把SIGHASH标志添加到序列化的结尾,并将计算序列化结果的散列,得到的散列值本身就是被签名的“消息”。根据使用哪个SIGHASH标志,交易的不同部分被截断,所得到的散列值其实是交易数据的不同子集产生的。在散列化前,SIGHASH作为最后一步被包含在内,签名也会对SIGHASH类型进行签署,因此不能被更改(例如,不能被矿工修改)。
所有SIGHASH类型对应交易nLocktime字段。此外,SIGHASH类型本身在签名之前附加到交易,因此一旦签名就不能修改它。
在Alice的交易的例子中,我们看到DER编码签名的最后一部分是01,这是SIGHASH_ALL标志。这会锁定交易数据,因此Alice的签名承诺的是所有的输入和输出状态。这是最常见的签名形式。
我们来看看其他一些SIGHASH类型,以及如何在实践中使用它们:
- ALL|ANYONECANPAY。这种标记可以用来做“众筹”交易,众筹发起人可以用单笔输出来构建一个交易,这笔输出将“目标”金额付给众筹发起人。这样的交易显然是无效的,因为它没有输入。但是现在其他人可以通过添加自己的输入作为捐赠来修改它们,他们用ALL|ANYONECANPAY签署自己的输入,直到收集到足够的输入以达到输出的目标金额前,交易无效,每一笔捐款都是一种“承诺”,在募集够整个目标金额之前,筹款不能收回。
- NONE。该结构可用于创建特定金额的“不记名支票”或“空白支票”。它对输入进行承诺,但允许输出锁定脚本被更改。任何人都可以将自己的比特币地址写入输出锁定脚本并兑换交易。然而,输出金额本身被签名锁定。
- NONE|ANYONECANPAY。这种构造可以用来建造一个“吸尘器”。在钱包中拥有微小UTXO的用户无法花费这些费用,因为手续费超过了这些微小UTXO的价值。借助这种类型的签名,微小UTXO可以捐赠给任何愿意募集的人并由他们随时花费。
有一些修改或扩展SIGHASH系统的建议。Blockstream的Glenn Willen将Elements项目的一部分——Bitmask Sighash Modes作为一个建议。这旨在为SIGHASH类型创建一个灵活的替代品,允许“任意的,输入和输出的矿工可改写位掩码”来表示“更复杂的合同预付方案,例如已分配的资产交换中有对变更的报价签名”。
你不会在钱包应用程序中看到SIGHASH标志作为选项功能提供。除少数特殊情况外,钱包构建P2PKH脚本并使用SIGHASH_ALL标志进行签名。要使用不同的SIGHASH标志,你必须编写软件来构造和签名交易。
更重要的是,SIGHASH标志可以被特殊用途的比特币应用程序使用,从而实现新颖的用途。
(4)ECDSA数学
如前所述,签名是由数学函数Fsig创建的,它产生由两个值R和S组成的签名。在本节中,我们将查看函数Fsig的更多细节。
签名算法首先生成一个临时(ephemeral)私公钥对。在涉及签名私钥和交易散列的转换之后,此临时密钥对用于计算R和S值。
临时密钥对基于随机数k,用作临时私钥。利用k,我们生成相应的临时公钥P(以P=k*G计算,与派生比特币公钥相同)。数字签名的R值则是临时公钥P的x轴坐标。
从那里,算法计算签名的S值,使得:
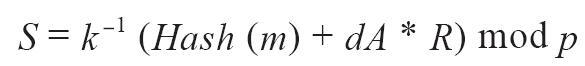
其中:
- k是临时私钥
- R是临时公钥的x坐标
- dA是签名私钥
- m是交易数据
- p是椭圆曲线的主要阶数
验证是签名生成函数的反函数,使用R、S值和公钥来计算P值,该值是椭圆曲线上的一个点(签名创建中使用的临时公钥):
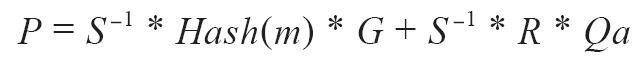
其中:
- R和S是签名值
- Qa是Alice的公钥
- m是签署的交易数据
- G是椭圆曲线生成点
如果计算结果点P的x坐标等于R,则验证者可以得出结论,签名是有效的。
请注意,在验证签名时,既不需要知道私钥也不需要透露私钥。
(5)随机性在签名中的重要性
正如前面所述,签名生成算法使用随机密钥k作为短暂私钥/公钥对的基础。k的值并不重要,只要它是随机的。如果使用相同的值k在不同的消息(交易)上生成两个签名,那么任何人都可以计算出签名私钥。在签名算法中重用相同的k值的会导致私钥的暴露!
如果在两个不同的交易中,在签名算法中使用相同的值k,则私钥可以被计算并暴露给世界!
这不仅仅是一个理论上的可能性。我们已经看到比特币中几种不同实现的交易签名算法因为这个问题导致私人密钥暴露。人们由于无意中重复使用k值而导致资金被窃取。重用k值的最常见原因是随机数生成器未正确初始化。
为了避免这个漏洞,业界最佳实践不是用熵播种的随机数生成器生成k值,而是使用交易数据本身播种的确定性随机进程。这确保每个交易产生不同的k值。在互联网工程任务组(Internet Engineering Task Force)发布的RFC6979(https://tools.ietf.org/html/rfc6979)中定义了k值的确定性初始化的行业标准算法。
如果你正在实现一种用于在比特币中签署交易的算法,则必须使用RFC 6979或类似的确定性随机算法来确保为每个交易生成不同的k值。
比特币地址、余额和其他摘要
在本章开始,我们发现交易的“幕后”看起来与它在钱包、区块链浏览器和其他面向用户的应用程序中呈现的样子非常不同。来自前几章的许多简单而熟悉的概念,如比特币地址和余额,似乎在交易结构中不存在。我们看到交易本身并不包含比特币地址,而是通过锁定和解锁比特币面值的脚本进行操作。区块链系统中的任何地方都不存在余额,而每个钱包应用程序都明明白白地显示了用户钱包的余额。
现在我们已经探讨了一个比特币交易中实际包含的内容,我们可以研究更高层次的抽象概念是如何从交易这个看似原始的组成部分中派生出来的。
让我们再来看看Alice的交易是如何在主流的资源块浏览器上呈现的。
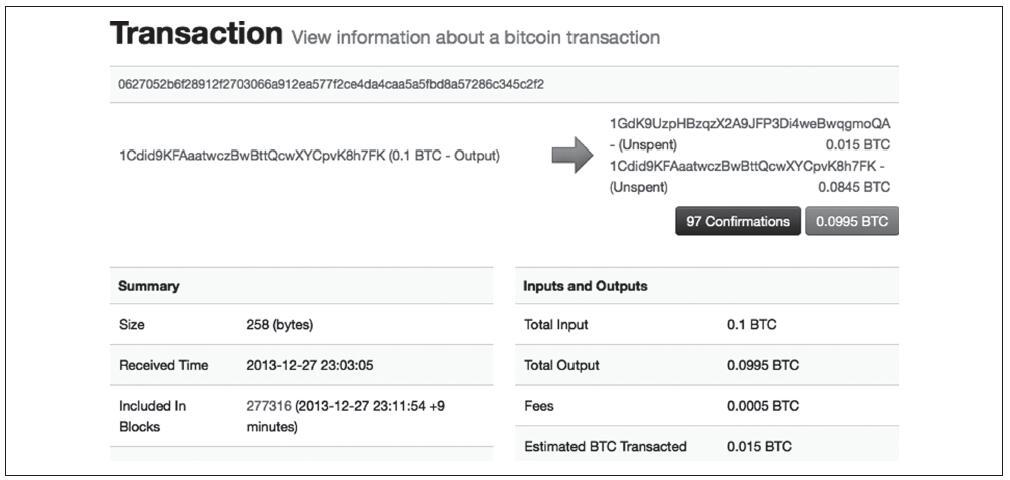
在交易的左侧,区块链浏览器将Alice的比特币地址显示为“发送者”。其实这个信息本身并不在交易中。当区块链浏览器检索到交易时,它还检索在输入中引用的先前交易,并从该交易中提取第一个输出。在该输出内是一个锁定脚本,将UTXO锁定到Alice的公钥散列(P2PKH脚本)。区块链浏览器提取公钥散列,并使用Base58Check对其进行编码,以生成和显示表示该公钥的比特币地址。
同样,在右侧区块链浏览器显示了两个输出:第一个是Bob的比特币地址,第二个是Alice的比特币地址(作为找零)。再次,为了创建这些比特币地址,区块链浏览器从每个输出中提取锁定脚本,将其识别为P2PKH脚本,并从内部提取公钥散列。最后,区块链浏览器使用Base58Check重新编码该公钥,以生成并显示比特币地址。
如果你点击Bob的比特币地址,则区块链浏览器将显示Bob的比特币地址的余额:
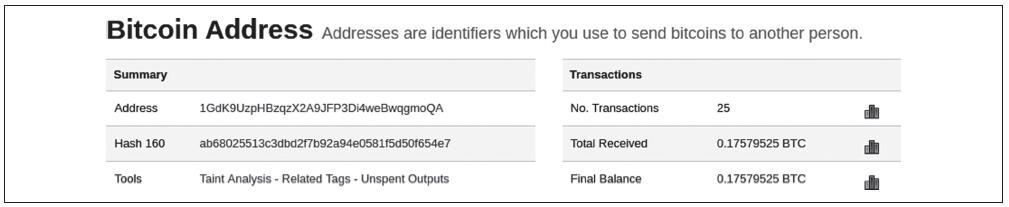
区块链浏览器显示Bob的比特币地址的余额。但比特币系统中没有任何地方存在“平衡”的概念。相反,这里显示区块链浏览器构建,如下所述。
为了构建“总收到”金额,区块链浏览器首先解码比特币地址的Base58Check编码,以检索地址中编码的Bob的公钥的160位散列值。然后,区块链浏览器将搜索交易数据库,查找使用包含Bob的公钥散列的P2PKH锁定脚本输出。通过计算所有输出的值,区块链浏览器可以生成收到的总值。
为了构建当前余额(显示为“最终余额”)需要更多的工作。区块链浏览器将当前未使用的输出作为单独的数据库,即UTXO集。为了维护此数据库,区块链浏览器必须实时监控比特币网络,添加新创建的UTXO,并删除实时已使用的UTXO,只要它们出现在未经确认的交易中。这是一个复杂的过程,不但要实时地跟踪交易在网络上的传播,同时还要保持与比特币网络的共识,确保在正确的区块链上。有时区块链浏览器未能保持同步,导致其对UTXO集的跟踪扫描不完整或不正确。通过计算UTXO集,区块链浏览器计算了引用Bob的公钥散列的所有未使用输出的值,并产生向用户显示的“最终余额”数目。
为了生成这张图片,得到这两个“余额”,区块链浏览器必须索引并搜索数十、数百甚至数十万的交易。
总之,通过钱包应用程序、区块链浏览器和其他比特币用户界面呈现给用户的信息通常源于更高层次的抽象概念组成,这些概念通过搜索许多不同的交易,检查其内容以及整合其中包含的数据而构成。为了将比特币交易呈现出类似于银行支票从发送人到接收人的这种简单视图,这些应用程序必须抽象许多底层细节。应用程序主要关注常见的交易类型:每个输入上具有SIGHASH_ALL签名的P2PKH。
因此,虽然比特币应用程序以易于阅读的方式呈现了80%以上的交易,但有时候会偏离常规的交易。有些交易包含更复杂的锁定脚本,或不同的SIGHASH标志,或许多输入和输出,这些交易显示了这些抽象概念的简单性和弱点。
每天都有数百个不包含P2PKH输出的交易在区块链上被确认。区块浏览器经常向它们发出红色警告信息,表示无法解码地址。链接https://blockchain.info/strange-transactions包含未完全解码的最新的“奇怪交易”。这些并不一定是奇怪的交易。它们是包含比常见的P2PKH更复杂的锁定脚本的交易。我们将学习如何解码和了解更复杂的脚本及其支持的应用程序。我们在下一章继续深入讨论这个话题。
四、高级交易及脚本
在上一章中,我们介绍了比特币交易的基本元素,并且研究了最常见的交易脚本类型,即P2PKH脚本。在本章中,我们将介绍更高级的脚本以及如何使用它来构建复杂条件下的交易。
多重签名
多重签名脚本设置了一个条件,其中N个公钥被记录在脚本中,并且必须提供至少M个签名才能解锁资金。这也称为M-N方案,其中N是密钥的总数,M是验证所需的签名的数量。
例如,2/3的多重签名是三个公钥被列为潜在签名人,至少有2个有效的签名才能花费资金。
此时,标准多重签名脚本最多只能包含15个公钥,这意味着可以选择1-1到15-15或该范围内的任意组合的多重签名执行任何操作。注意,这个标准仍在不断修订中,对最多15个可列出公钥的限制可能会被解除,因此请检查isStandard()函数以查看当前网络可接受的内容。
设置M-N多重签名条件的锁定脚本的一般形式是:
M <Public Key 1> <Public Key 2> ... <Public Key N> N CHECKMULTISIG
- M是花费输出所需的签名的数量
- N是列出的公钥的总数
设置2-3多重签名条件的锁定脚本如下所示:
2 <Public Key A> <Public Key B> <Public Key C> 3 CHECKMULTISIG
上述锁定脚本可由含有签名和公钥的脚本予以解锁:
<Signature B> <Signature C>
或者由3个公钥中的任意两个相一致的私钥签名组合予以解锁。
<Signature B> <Signature C> 2 <Public Key A> <Public Key B> <Public Key C> 3CHECKMULTISIG
两个脚本组合将形成一个验证脚本:执行时,只有在解锁版脚本与锁定脚本设置的条件匹配时,此组合脚本才会得到结果为真(Ture)。
上述例子中相应的解锁条件为:解锁脚本是否含有3个公钥中的任意2个相对应的私钥的有效签名。
CHECKMULTISIG执行中的bug
CHECKMULTISIG的执行过程中有一个bug,需要稍加变通解决。当CHECKMULTISIG执行时,它应该消耗栈(stack)上的M+N+2个项目作为参数。然而,由于该错误,CHECKMULTISIG将弹出(pop)超出预期的额外值或一个值。让我们用前面的验证示例更详细地看看这个例子:
<Signature B> <Signature C> 2 <Public Key A> <Public Key B> <Public Key C> 3 CHECKMULTISIG
- 首先,CHECKMULTISIG弹出顶部项目,即N(在本例中为“3”)。
- 然后它弹出N个项目,这是可签名的公钥,在本例中为公钥A、B和C。
- 然后,它弹出一个项目,即M,仲裁数(需要多少个签名)在本例中M=2。
- 此时,CHECKMULTISIG应弹出最终的M个项目,这些是签名,并查看它们是否有效。然而,不幸的是,执行中的一个错误会导致CHECKMULTISIG再多弹出一个项目(总共M+1个)。检查签名时,并不需要考虑额外的项目,因此它对CHECKMULTISIG本身没有直接影响。但是,必须存在额外的值,因为如果不存在,当CHECKMULTISIG尝试弹出空栈时,会导致栈错误和脚本失败(将交易标记为无效)。由于额外的值会被忽略,它可以是任何东西,但通常使用0代替。
因为这个bug成为共识规则的一部分,所以现在它必须永远被复制。因此正确的验证脚本将如下所示:
0 <Signature B> <Signature C> 2 <Public Key A> <Public Key B> <Public Key C> 3CHECKMULTISIG
于是解锁脚本就不是下面所示的:
<Signature B> <Signature C>
而是:
0 <Signature B> <Signature C>
从现在开始,如果你看到一个multisig解锁脚本,你应该期望在开始时看到一个额外的0,它唯一的目的是解决一个bug,却意外地成为一个共识规则。
P2SH
P2SH(Pay-to-Script-Hash)在2012年被作为一种新型、强大且能大大简化复杂交易脚本的交易类型而引入。为进一步解释P2SH的必要性,让我们先看一个实际的例子。
Mohammed是一个一个迪拜的电子产品进口商。Mohammed的公司采用比特币多重签名作为其公司会计账簿记账要求。多重签名脚本是比特币高级脚本最为常见的运用之一,是一种具有相当大影响力的脚本。针对所有的顾客支付(即应收账款),Mohammed的公司要求采用多重签名交易。基于多重签名机制,顾客的任何支付都需要至少两个签名才能解锁,一个来自Mohammed,另一个来自其合伙人或拥有备份钥匙的律师。这样的多重签名机制能为公司治理提供管控便利,同时也能有效防范盗窃、挪用和遗失。
最终的脚本非常长,如下所示:
2 <Mohammed's Public Key> <Partner1 Public Key> <Partner2 Public Key> <Partner3 Public Key> <Attorney Public Key> 5 OP_C HECKMULTISIG
尽管多重签名脚本功能十分强大,但它们使用起来很麻烦。基于之前的脚本,Moham-med必须在客户付款前将该脚本发送给每一位客户,而每一位顾客也必须使用特制的能构建自定义交易脚本的比特币钱包软件,每位顾客还得学会如何使用自定义脚本来完成交易。此外,由于脚本可能包含特别长的公钥列表,最终的交易脚本可能是普通交易脚本长度的5倍之多。额外长度的脚本将给客户造成费用负担。像这样的大型交易脚本将一直记录在所有节点内存中的UTXO集中,直到该笔资金被使用。采用这种复杂输出脚本使得实际交易变得困难重重。
P2SH正是为了解决这一实际难题而被引入的,它旨在使复杂脚本的使用能与直接向比特币地址支付一样简单。通过P2SH支付,复杂的锁定脚本将被其数字指纹(一种加密散列)所取代。当稍后试图花费此UTXO时,除了解锁脚本外,它还必须包含与散列值相匹配的脚本。简而言之,P2SH的意思是“支付与该散列值相匹配的脚本,这个脚本将在输出被使用时出示”。
在P2SH交易中,由散列值代替的锁定脚本被称为兑换脚本,因为它在兑换时显示给系统,而不是以锁定脚本形式呈现。下表列出了不使用P2SH的脚本和使用了P2SH脚本的区别。
不含P2SH的复杂脚本

P2SH复杂脚本

从表中可以看出,使用P2SH时,花费资金的条件(兑换脚本)未在锁定脚本中显示。相反,只有它的散列值在锁定脚本中出现,并且兑换脚本本身稍后会作为解锁脚本的一部分在输出时显示出来。这使得给矿工的交易费用从发送方转移到收款方,复杂的计算工作也从发送方转移到收款方。
让我们再看下Mohammed公司的例子,该公司使用复杂的多重签名脚本和相应的P2SH脚本。
首先,Mohammed公司对所有顾客订单采用多重签名脚本:
2 <Mohammed's Public Key> <Partner1 Public Key> <Partner2 Public Key> <Partner3 Public Key> <Attorney Public Key> 5 CHECKMULTISIG
如果占位符被实际的公钥取代(这里显示为以04开头的520位数字),你可以看到该脚本变得非常长:
2 04C16B8698A9ABF84250A7C3EA7EEDEF9897D1C8C6ADF47F06CF73370D74DCCA01CDCA79DCC5C395 D7EEC6984D83F1F50C900A24DD47F569FD4193AF5DE762C58704A2192968D8655D6A935BEAF2CA23 E3FB87A3495E7AF308EDF08DAC3C1FCBFC2C75B4B0F4D0B1B70CD2423657738C0C2B1D5CE65C97D7 8D0E34224858008E8B49047E63248B75DB7379BE9CDA8CE5751D16485F431E46117B9D0C1837C9D5 737812F393DA7D4420D7E1A9162F0279CFC10F1E8E8F3020DECDBC3C0DD389D99779650421D65CBD 7149B255382ED7F78E946580657EE6FDA162A187543A9D85BAAA93A4AB3A8F044DADA618D0872274 40645ABE8A35DA8C5B73997AD343BE5C2AFD94A5043752580AFA1ECED3C68D446BCAB69AC0BA7DF5 0D56231BE0AABF1FDEEC78A6A45E394BA29A1EDF518C022DD618DA774D207D137AAB59E0B000EB7E D238F4D800 5 CHECKMULTISIG
整个脚本都可由仅为20个字节的加密散列值所取代,首先采用SH256散列算法,随后对其运用RIPEMD160算法。前面脚本的20字节的散列值为:
54c557e07dde5bb6cb791c7a540e0a4796f5e97
一笔P2SH交易锁定脚本将输出与脚本散列值关联,而不是与前面特别长的脚本相关联。使用的锁定脚本为:
HASH160 54c557e07dde5bb6cb791c7a540e0a4796f5e97e EQUAL
正如你所看到的,这个脚本比前面的长脚本简短多了。取代“向5个多重签名脚本支付”,这个P2SH等同于“向符合该散列的脚本支付”。顾客在向Mohammed公司支付时,只需在其支付指令中纳入这个非常简短的锁定脚本即可。当Mohammed想要花费这笔UTXO时,附上原始兑换脚本(可计算出锁定UTXO散列值)和必要的解锁签名即可,如:
<Sig1> <Sig2> <2 PK1 PK2 PK3 PK4 PK5 5 CHECKMULTISIG>
这个组合(解锁+锁定)脚本执行分为两个阶段。
- 首先,根据锁定脚本检查兑换脚本以确保散列匹配:<2 PK1 PK2 PK3 PK4 PK5 5 CHECKMULTISIG> HASH160 <redeem scriptHash> EQUAL
- 然后,如果兑换脚本与散列匹配,解锁脚本会释放兑换脚本并加以执行:<Sig1> <Sig2> 2 PK1 PK2 PK3 PK4 PK5 5 CHECKMULTISIG
本章介绍的几乎所有脚本都只能作为P2SH脚本实现。它们不能直接用在UTXO的锁定脚本中。
(1)P2SH地址
P2SH的另一重要特征是它能将脚本散列编码为一个地址,如BIP-13中所定义的。P2SH地址是脚本的20字节散列的Base58Check编码,就像比特币地址是公钥的20字节散列的Base58Check编码一样。P2SH地址使用版本前缀“5”,这导致以“3”开头的Base58Check编码地址。
例如,Mohammed的脚本,脚本散列在Base58编码下的P2SH地址变为“39RF6JqABiHdYHkfChV6USGMe6Nsr66Gzw”。现在,Mohammed可以为其客户提供这个“地址”,他们几乎可以使用任何比特币钱包进行简单付款,就好像它是一个比特币地址一样。前缀“3”给他们提示这是一种特殊类型的地址:解锁条件对应于脚本而不是公钥,但是它的使用方式与对比特币地址的付款完全相同。
P2SH地址隐藏了所有的复杂性,因此付款人看不到也不需要看到脚本。
(2)P2SH的优点
与直接使用复杂脚本以锁定输出的方式相比,P2SH具有以下优点:
- 在交易输出中,复杂脚本由简短散列值代替,使得交易代码变短。
- 脚本能被编译为地址,支付指令的发出者和支付者的比特币钱包不需要复杂的实现就可以执行P2SH,复杂性由接受者承担。
- P2SH将构建脚本的工作转移至接收方,而非发送方。
- P2SH将长脚本数据存储的负担从输出侧(需要存储于UTXO集,过大影响内存)转移至输入侧(长脚本存储在区块链)。
- P2SH将长脚本数据存储的负担从当前(交易时)转移至未来(花费时)。
- P2SH将长脚本的交易费成本从付款方转移至收款方,收款方在使用该笔资金时必须包含兑换脚本。
(3)赎回脚本和标准确认
在0.9.2版比特币核心客户端之前,P2SH仅限于标准比特币交易脚本类型(即通过标准函数检验的脚本)。这也意味着使用该笔资金的交易中的赎回脚本只能是标准化的P2PK、P2PKH或者多重签名,不包含RETURN和P2SH。
从0.9.2版的比特币核心客户端开始,P2SH交易能包含任何有效的脚本,这使得P2SH标准更为灵活,也可以尝试用于多种新的或复杂类型的交易。
请注意,你无法将P2SH放入P2SH兑换脚本中,因为P2SH规范不是递归的。虽然在技术上可以将RETURN包含在兑换脚本中,规则中并没有细则阻止此操作,在验证期间执行RETURN将会导致事务被标记为无效,实际上并不可行。
需要注意的是,因为兑换脚本只有在你试图花费一个P2SH输出时才会在比特币网络中出现,假如你将输出与一个无效的兑换脚本的散列进行锁定,它将会被执行,该UTXO将会被成功锁定,但是你将无法使用这笔资金,因为包含无效兑换脚本的支出交易不会被接受。这样的处理机制也衍生出一个风险,因为你可以将比特币锁定在一个不能使用的P2SH中。网络会接受任何P2SH散列值,哪怕对应的是无效的兑换脚本,因为散列值本身无法呈现具体的脚本(比特币网络也无法检查脚本是否合法)。
P2SH锁定脚本包含一个兑换脚本散列,这不会提供有关兑换脚本本身内容的任何描述。即使兑换脚本无效,P2SH交易也将被视为有效并被接受。你有可能会出现类似的事故,比特币被锁死在一个无效的兑换脚本中,导致你以后再也不能花费这笔比特币了。
数据记录输出(RETURN操作符)
比特币的去中心特点和时间戳账本机制,即区块链技术,其潜在用途将大大超出支付领域。许多开发者试图充分发挥交易脚本语言的安全性和灵活性优势,将其运用于电子公证服务、股票证券和智能合约等领域。很多早期的开发者利用比特币这种能将交易输出数据放到区块链上的技术进行了很多尝试,例如,为文件记录电子指纹,则任何人都可以利用该机制通过引用特定日期的交易建立关于文档存在性的证明。
运用比特币的区块链技术存储与比特币支付不相关数据的做法是一个有争议的话题。许多开发者认为其有滥用的嫌疑,因而试图予以阻止。另一些开发者则将之视为区块链技术强大功能的有力证明,从而试图给予大力支持。那些反对非支付相关应用的开发者认为这样做将引致“区块链膨胀”,因为所有的区块链节点都将以消耗磁盘存储空间为成本,负担存储此类数据的任务。更为严重的是,此类交易仅将比特币地址当作自由组合的20个字节而使用,进而会产生不能用于交易的UTXO。因为比特币地址只是被当作数据使用,并不与私钥相匹配,所以会导致UTXO不能被用于交易,因而是一种伪支付行为。因此,这些交易永远不会被花费,所以永远不会从UTXO集中删除,并导致UTXO数据库的大小永远增加或“膨胀”。
在0.9版的比特币核心客户端上,通过采用Return操作符最终实现了妥协。Return允许开发者在交易输出上增加80个字节的非交易数据。与伪交易型的UTXO不同,Return创造了一种明确的可复查的非交易型输出,此类数据无须存储于UTXO集。
Return输出被记录在区块链上,它们会消耗磁盘空间,也会导致区块链规模的增加,但它们不存储在UTXO集中,因此也不会导致UTXO膨胀从而占用昂贵的内存让全节点都不堪重负。
RETURN脚本的样式:
RETURN <data>
“data”部分被限制为80字节,并且通常以散列方式呈现,例如,32字节的SHA256算法输出。
许多应用程序在数据前加上前缀以帮助程序进行识别。例如,电子公证服务的证明服务采用8个字节的前缀DOCPROOF,它以ASCII编码在十六进制下为:44 4f 43 50 52 4f4f 46。
请记住,没有与RETURN对应的可以花费RETURN输出“解锁脚本”。RETURN不能使用其输出中所锁定的资金,因此它也就没有必要记录在蕴含潜在成本的UTXO集中,所以RETURN实际是没有成本的。RETURN常为一个金额为0的比特币输出,因为任何与该输出相对应的比特币都会永久丢失。假如一笔RETURN被作为一笔交易的输入,脚本验证引擎将会阻止验证脚本的执行,将交易标记为无效。如果你碰巧将RETURN的输出作为另一笔交易的输入,则该交易是无效的。
一笔标准交易(通过了isStandard()函数检验的)只能有一个RETURN输出。但是单个RETURN输出能与任意类型的交易输出进行组合。
比特币核心版本0.10中增加了两个新的命令行选项。
- 选项datacarrier控制RETURN交易的传输和打包,默认设置为“1”以允许RETURN。
- 选项datacarriersize是一个数字参数,指定RETURN脚本的最大大小(以字节为单位),默认为83字节,意味着允许数据最多为80个字节,因为数据需要加上一个字节的RETURN操作码和两个字节的PUSHDATA操作码。
最初提出了RETURN的提议,限制为80字节,但是当功能被正式开放时,限制被减少到40字节。2015年2月,在Bitcoin Core的0.10版本中,限制恢复到80字节。节点可以选择不传输或打包RETURN,或者传输或打包包含少于80字节数据的RETURN。
时间锁
时间锁(Timelocks)是只允许在某个时间点之后才可以被支出的交易或输出。比特币从一开始就有一个交易级的时间锁定功能。它由交易中的nLocktime字段实现。在2015年年底和2016年中期推出了两个新的时间锁定功能,可提供UTXO级别的时间锁定功能。它们是
- CHECKLOCKTIMEVERIFY
- CHECKSEQUENCEVERIFY
时间锁对于后期交易和将资金锁定到将来的日期非常有用。更重要的是,时间锁将比特币脚本延伸到时间的维度,为复杂的多级智能合同打开了大门。
(1)交易锁定时间
比特币从一开始就有一个交易级的时间锁功能。交易锁定时间(nLocktime)是交易级设置(交易数据结构中的一个字段),它定义交易有效的最早时间,并且可以在网络上传输或添加到区块链中。
锁定时间也称为nLocktime,是来自于Bitcoin Core代码库中使用的变量名称。在大多数交易中将其设置为零,以指示即时传播和执行。如果nLocktime不为零并低于5亿,它将被解释为块高度,在指定的块高度之前交易无效而无法被传输或包含在区块链中。如果超过5亿,它被解释为Unix纪元时间戳(自1970年1月1日之后的秒数),并且交易在指定时间之前无效。指定未来块或时间的nLocktime的交易必须由初始构建交易的系统持有,并且只有在有效后才被发送到比特币网络。如果交易在指定的nLocktime之前传输到网络,那么第一个收到节点就会认为交易无效而拒绝该交易,并且交易不会被传输到其他节点。
使用nLocktime相当于一张远期支票。
交易锁定时间限制
nLocktime有一个局限性,虽然它可以在将来花费一些输出,但它不会使用户在那之前花费不了。我们用下面的例子来解释一下。
Alice将其输出中的一个输出到Bob的地址,并将交易nLocktime设置为未来3个月。Alice将该交易发送给Bob进行保存。通过这次交易,Alice和Bob知道:
- 在3个月过去之前,Bob不能完成交易进行变现。
- Bob可以在3个月后完成交易。
然而:
- Alice可以创建另一个交易,双重花费相同的输入,而不需要锁定时间。因此,Alice可以在3个月过去之前花费相同的UTXO。
- Bob无法保证Alice不会这样做。这就相当于说开出远期支票的付款方在收款方兑换支票之前花掉了账户中的钱,则这张远期支票在到期就无法正常兑现了。
了解交易nLocktime局限性非常重要。上述例子唯一的保证是Bob在3个月过去之前无法兑换它,但不能保证Bob能得到资金。
为了实现这样的保证(既保证Bob在3个月过去之前无法兑换它,也保证Bob能得到资金),时间限制必须放在UTXO本身上,并成为锁定脚本的一部分,而不是交易。这是通过下一种形式的时间锁定来实现的,也称为检查锁定时间验证(Check Lock Time Verify,CLTV)。
(2)检查锁定时间验证
2015年12月,一种新的时间锁形式被引入比特币作为软分叉升级。根据BIP-65中的规范,脚本语言添加了一个名为CHECKLOCKTIMEVERIFY(CLTV)的新脚本操作符。CLTV是每个输出的时间锁定,而不是和nLocktime一样的交易时间锁定。这可以在应用时间锁的方式上提供更大的灵活性。
简单来说,通过在输出的兑换脚本中添加CLTV操作码来限制输出,从而保证输出在指定的时间过后才能被使用。
- nLocktime是交易级别的时间锁
- CLTV是输出级别的时间锁。
CLTV不会取代nLocktime,而是用于限制特定的UTXO,并通过将nLocktime设置为更大或相等的值,从而达到在未来才能花费这笔钱的目的。
CLTV操作码采用一个参数作为输入,是个与nLocktime(块高度或Unix纪元时间)相同格式的数字。如VERIFY后缀所示,CLTV是验证类操作码,如果执行结果为FALSE,则停止执行脚本,如果结果为TRUE,则继续执行。
为了使用CLTV锁定输出,可以将其插入到输出的兑换脚本中。例如,如果Alice直接支付到Bob的地址,输出通常会包含一个如下的P2PKH脚本:
DUP HASH160 <Bob's Public Key Hash> EQUALVERIFY CHECKSIG
要锁定一段时间,比如说3个月以后,交易将是一个P2SH交易,其中包含一个赎回脚本:
<now + 3 months> CHECKLOCKTIMEVERIFY DROP DUP HASH160 <Bob's Public Key Hash> EQUALVERIFY CHECKSIG
其中<now+3 months>交易打包3个月后的块高度或时间值:当前块高度+12,960(块)或当前Unix纪元时间+7,760,000(秒)。
当Bob尝试花费这个UTXO时,他构建了一个引用此UTXO作为输入的交易。他在输入的解锁脚本中使用他的签名和公钥,并将交易nLocktime设置为等于或大于Alice设置的CHECKLOCKTIMEVERIFY时间锁。然后,Bob在比特币网络上广播此交易。
Bob的交易验证如下。
- 如果Alice设置的CHECKLOCKTIMEVERIFY参数小于或等于支出交易的nLocktime,脚本将继续执行(就好像执行“无操作”或NOP操作码一样)。
- 否则,脚本停止执行,并且该交易被视为无效。
更确切地说,如果满足以下条件之一,CHECKLOCKTIMEVERIFY失败并停止执行,标记交易无效(详见:BIP-65):
- 栈为空的。
- 栈中的顶部项小于0。
- 顶层栈项和nLocktime字段的锁定类型(高度或者时间戳)不相同。
- 顶层栈项大于交易的nLocktime字段。
- 输入的nSequence字段值为0xffffffff。
CLTV和nLocktime使用相同的格式来描述时间锁定,无论是块高度还是自Unix纪元以秒钟以来所经过的时间。最重要的是,在一起使用时,nLocktime的格式必须与输入中的CLTV格式相匹配,它们必须以秒为单位引用块高度或时间。
CLTV执行后,如果结果为TRUE,则其之前的时间参数仍然作为栈中的顶层项目,并且可能需要使用DROP删除,才能正确执行后续脚本操作码。为此,你将经常在脚本中看到将CHECKLOCKTIMEVERIFY和DROP一起使用。
通过将nLocktime与CLTV结合使用,可以优化前面方案存在的问题。由于Alice锁定了UTXO本身,因此在3个月的锁定时间到期之前Bob或Alice都无法花费它。
通过将时间锁定功能直接引入到脚本语言中,CLTV允许我们开发一些非常有趣的复杂脚本。
该标准在BIP-65(CHECKLOCKTIMEVERIFY)(https://github.com/bitcoin/bips/blob/master/bip-0065.mediawike)中定义。
(3)相对时间锁
nLocktime和CLTV都是绝对时间锁定,因为它们指定绝对时间点。接下来我们要研究的两个时间锁,特征是锁定时间是相对,因为它们将消耗输出的条件指定为输出从区块链中确认的经过时间。
相对时间锁是有用的,因为它们允许将两个或多个相互依赖的交易链接在一起,同时对依赖于从先前交易的确认所经过的时间的一个交易施加时间约束。换句话说,在UTXO被记录在区块链之前,时钟不开始计数。这个功能在双向状态通道和闪电网络中特别有用。
相对时间锁同时具有交易级功能和脚本级操作码。
- 交易级相对时间锁定是基于对每个交易输入中设置的交易字段nSequence的值的共识规则实现的。
- 脚本级相对时间锁定使用CHECKSEQUENCEVERIFY(CSV)操作码实现。
相对时间锁是根据BIP-68与BIP-112的规范共同实现的,其中,
- BIP-68通过与相对时间锁运用一致性增强的数字序列(https://github.com/bitcoin/bips/blob/master/bip-0068.mediawiki)实现
- BIP-112中运用了CHECKSEQUENCEVERIFY(https://github.com/bitcoin/bips/blob/master/bip-0012.mediawiki)操作码实现。
BIP-68和BIP-112是在2016年5月作为软分叉升级时被激活的一个共识规则。
(4)带nSequence的相对时间锁
通过在每个输入中设置nSequence字段,可以在交易的每个输入上设置相对时间锁。
1、nSequence的本义
nSequence字段的最初意图(但从未被实现)是允许修改mempool中的交易。在该用途中,包含nSequence值低于232(0xFFFFFFFF)的输入的交易表明一个尚未“最终确定”的交易。这样的事务将保存在mempool中,直到被另一个消耗相同输入并具有较大nSequence值的交易所代替。一旦收到一个交易,其输入的nSequence值为232,它将被视为“最终确定”并被矿工打包。
nSequence的本义从未被正确实现,并且在不利用时间锁定的交易中nSequence的值通常设置为232。对于使用nLocktime或CHECKLOCKTIMEVERIFY的交易,nSequence值必须设置为小于232,才能使时间锁生效。通常设置为232-1(0xFFFFFFFE)。
2、nSequence作为一个共识的相对时间锁
由于BIP-68的激活,新的共识规则适用于任何包含nSequence并且值小于232的输入的交易(bit 1<<31 is not set)。在编程语言里,这意味着如果没有设置最高有效(bit1<<31),它是一个表示“相对锁定时间”的标志。否则(bit 1<<31 set),nSequence值被保留用于其他用途,例如启用CHECKLOCKTIMEVERIFY、nLocktime、Opt-In-Replace-By-Fee以及其他未来的新功能。
当输入脚本中的nSequence值小于231时,该交易就是一个相对时间锁定的交易。这种交易只有到了相对锁定时间后才生效。例如,具有一个30个区块的nSequence相对时间锁的输入的交易只有在从输入中引用的UTXO开始的区块起至少过了30个区块时才有效。由于每个输入都有nSequence字段,因此交易可能包含任何数量的时间锁的输入,所有这些输入时间锁都满足才可以使交易有效。交易可以同时包括有时间锁定输入(nSequence<231)和没有相对时间锁定(nSequence>=231)的输入。
nSequence值以块或秒为单位指定,但与nLocktime中使用的格式略有不同。有一个类型标志值用于区分计数块和计数时间(以秒为单位)。类型标志设置在第23个最低有效位(即值1<<22)。如果设置了类型标志,则nSequence值将被解释为512秒的倍数。如果未设置类型标志,则nSequence值被解释为块数。
当将nSequence解释为相对时间锁定时,只考虑16个最低有效位。一旦设置了相对时间锁的标志位(位32和位23),nSequence值通常用16位掩码(例如nSequence&0x0000FFFF)来“取值”。
下图显示由BIP-68定义的nSequence值的二进制示意图。

基于nSequence值来执行相对时间锁的共识定义在BIP-68中。标准定义详见BIP-68,使用序列号作为相对时间锁的一个共识。
(5)带CSV的相对时间锁
就像CLTV和nLocktime一样,有一个脚本操作码用于相对时间锁定,它将利用脚本中的nSequence值。该操作码是CHECKSEQUENCEVERIFY,通常简称为CSV。
在UTXO的兑换脚本中验证时,CSV操作码仅允许输入的nSequence值大于或等于CSV参数的输入,才可以在交易中花费。实质上,这限制了UTXO的即时使用,直到此UTXO被打包到区块链,并过了一定数量的块或秒。
与CLTV一样,CSV中的值必须与相应nSequence值中的类型相匹配。如果CSV是根据块指定的,那么nSequence也是如此。如果以秒为单位指定CSV,那么nSequence也是如此。
当几个被签名的交易(已经形成链)被保持为“脱链”且不传播时,CSV的相对时间锁特别有用。子交易在父交易被传播,被打包直到消耗完相对锁定时间前不可用。
CSV细节参见BIP-112,CHECKSEQUENCEVERIFY(https://github.com/bitcoin/bips/blob/master/bip-0112.mediawiki)。
(6)过去中位时间
作为相对时间锁激活的一部分,时间锁(绝对和相对)的“时间”计算方式也有所变化。在比特币中,实际时间(wall time)和共识时间之间存在微妙但非常显著的差异。
比特币是一个分布式的网络,这意味着每个参与者都有自己的时间观(每个电脑都可以有自己的时钟,各个时钟时间并不严格同步)。在网络上的各类事件不会同时计算与发生。必须从每个节点的角度考虑网络延迟。最终,所有内容都会被同步,以创建一个公共账本。比特币每隔10分钟就会对过去存在的账本状态达成一个新的共识。
区块头中设置的时间戳是由矿工设定。共识规则允许时间有一定的误差来解决分散节点之间时钟精度的问题。然而,这会造成一种不幸的激励措施,矿工会伪造时间戳,以便通过包括还不在范围内的时间锁交易来赚取额外矿工费。
为了消除矿工伪造时间戳的动因并加强时间安全性,在相对时间锁的基础上又新增了一个BIP。这是BIP-113,它定义了一个称为“过去中位时间”(Median-Time-Past)的新的共识测量机制。
该机制通过获取最后11个块的时间戳并计算其中位数作为“过去中位时间”的值。这个中间时间值就变成了共识时间,并被用于所有的时间计算。通过取从过去大约两个小时区块的中位时间,任何一个单独块的时间戳的影响都会减小。通过这个方法,没有一个矿工可以利用时间戳从具有尚未到期的时间锁的交易中获取非法矿工费。
Median-Time-Past更改了nLocktime、CLTV、nSequence和CSV的时间计算的实现。由Median-Time-Past计算的共识时间总是比实际时间大约晚一个小时。如果你创建时间锁交易,那么要在nLocktime、nSequence、CLTV和CSV中进行编码的估计所需时间值时,应该考虑到这点。
Median-Time-Past细节参见BIP-113(https://github.com/bitcoin/bips/blob/master/bip-0113.mediawiki)。
(7)针对费用狙击的时间锁
费用狙击(Fee Sniping)是一种理论攻击情形,矿工试图从将来的块中(从最新的交易池中挑选手续费较高的交易)重写过去的块,实现“狙击”更高费用的交易,以最大限度地提高盈利能力。
例如,假设现在的最高块是块#100,000。一些矿工们会试图重新挖矿#100,000,而不是试图把#100,001号的矿区扩大到区块链。这些矿工可以选择在可被打包到候选块#100,000中包括任何有效的交易(包括尚未开采)。他们不必使用相同的交易来恢复过去的块。事实上,他们有动力打包最有利可图(每KB付费最高)的交易到区块中。它们可以是处于“旧”块#100,000中的任何交易,或者是来自当前内存池的任何交易。当矿工重新打包创建区块#100,000时,他们本质上可以提取“现在”的交易并重写到“过去”中。类似于重放攻击。
今天,这种攻击并不是非常有利可图,因为区块奖励远远高于每个区块的总交易费。但在未来的某个时候,交易费将是奖励的大部分(甚至是奖励的全部)。那时候这种情况将变得不可避免了。
为了防止“费用狙击”,当Bitcoin Core钱包创建交易时,默认情况下,它将使用nLocktime将它们限制为“下一个块”。在上述场景中,Bitcoin Core钱包将会在创建任何新的交易时将nLocktime设置为100,001。在正常情况下,这个nLocktime没有任何影响,交易只能包含在#100,001以后的块中,这至少是下一个区块。
但在区块链分叉攻击的情况下,由于所有这些交易都将被时间锁阻止在#100,001之后,所以矿工们无法从新交易中提取高额的交易费。他们只能在当时有效的任何交易中重新挖矿#100,000,这导致实质上不会获得新的交易费用。
为了实现这一点,Bitcoin Core钱包将所有新交易(没有启用时间锁定的交易)的nLocktime设置为当前块号+1,并将所有输入上的nSequence设置为0xFFFFFFFE以启用nLocktime。
具有条件控制的脚本(条件语句)
比特币脚本有一个更强大的功能是条件控制,也称为条件语句。你可能熟悉使用类似IF…THEN…ELSE的各种编程语言中的流控制。比特币条件语句看起来有点不同,但是基本上是相同的结构。
最基本而言,比特币条件操作码允许我们构建一个具有两种解锁方式的兑换脚本,这取决于验证逻辑条件的TRUE/FALSE结果。例如,如果x为TRUE,则兑换脚本为A,ELSE兑换脚本为B。
此外,比特币条件表达式可以无限“嵌套”,这意味着一个条件语句可以包含另外一个条件,另外一个条件语句可以包含别的条件语句等。Bitcoin脚本流控制可用于构造非常复杂的脚本,甚至有数千个可能的执行路径。嵌套没有限制,但共识规则会对脚本的最大大小(以字节为单位)施加限制。
比特币使用IF、ELSE、ENDIF和NOTIF操作码实现流控制。此外,条件表达式可以包含布尔运算符,如BOOLAND、BOOLOR和NOT。
乍一看,你可能会发现比特币的流量控制脚本令人困惑。这是因为比特币脚本是一种栈语言。与11 ADD“向后”(backward)表达成1+1的方式相同,比特币中的流控制语句也看起来是“向后”表达。
在大多数传统(程序)编程语言中,流控制代码如下所示:
if (condition):
code to run when condition is true
else:
code to run when condition is false
code to run in either case在基于栈的语言中,比如比特币脚本,逻辑条件出现在IF之前,这使得它看起来像“向后”,Bitcoin流控制脚本如下所示:
condition
IF
code to run when condition is true
ELSE
code to run when condition is false
ENDIF
code to run in either case阅读Bitcoin脚本时,请记住,条件语句位于IF操作码之前。
(1)带有VERIFY操作码的条件语句
比特币脚本中的另一种条件控制语句是任何以VERIFY结尾的操作码。VERIFY后缀表示如果评估的条件不为TRUE,脚本的执行将立即终止,并且该交易被视为无效。
与提供替代执行路径的IF子句不同,VERIFY后缀充当保护语句,只有在满足前提条件的情况下才会继续。
例如,以下脚本需要Bob的签名和产生特定散列的pre-image(秘密地)。
HASH160 <expected hash> EQUALVERIFY <Bob's Pubkey> CHECKSIG
为了兑换输出,Bob必须构建一个解锁脚本,提供有效的pre-image和签名:
<Bob's Sig> <hash pre-image>
没有pre-image,Bob执行检查其签名部分的脚本。
该锁定脚本也可以用IF编写:
HASH160 <expected hash> EQUAL
IF
<Bob's Pubkey> CHECKSIG
ENDIFBob的解锁脚本还是一样的:
<Bob's Sig> <hash pre-image>
带IF的脚本与使用带VERIFY后缀的操作码的脚本可以达到相同的功能;它们都作为条件语句运行。但是VERIFY的构造更高效,使用较少的操作码。
那么,我们什么时候使用VERIFY,什么时候使用IF呢?
如果我们想要做的是附加一个前提条件(保护条件语句),那么VERIFY是更好的。然而,如果我们想要有多个执行路径(流控制),那么我们需要一个IF…ELSE流控制子句。
诸如EQUAL之类的操作码会将结果(TRUE/FALSE)推送到栈上,留下结果用于后续操作码的运算。相反,以EQUALVERIFY为后缀的操作码不会在栈上留下任何东西。以VERIFY为后缀的操作码也不会将结果留在栈上。
(2)在脚本中使用流控制
比特币脚本中流控制的一个常见的用途是构建一个提供多个执行路径的兑换脚本,每个路径都有一种不同的兑换UTXO的方式。
我们来看一个简单的例子,我们有两个签名人,Alice和Bob,两人中任何一个签名都可以兑换输出。如果使用多重签名,这将被表示为1-of-2多重签名脚本。为了示范,我们将使用IF子句实现同样的功能:
IF <Alice's Pubkey> CHECKSIG
ELSE
<Bob's Pubkey> CHECKSIG
ENDIF看这个兑换脚本,你可能会想:“条件在哪里?”IF子句之前也没有也什么!
条件不是兑换脚本的一部分。相反,该解锁脚本将提供该条件,允许Alice和Bob“选择”他们想要的执行路径。
Alice用解锁脚本兑换了这个:
<Alice's Sig> 1
最后的1作为条件(TRUE),将使IF子句执行Alice具有签名的第一个兑换路径。
Bob为了兑换输出,必须通过给IF子句赋一个FALSE值来选择第二个执行路径:
<Bob's Sig> 0
Bob的解锁脚本在栈中放置一个0,导致IF子句执行第二个(ELSE)脚本,这需要Bob的签名。
由于可以嵌套IF子句,所以我们可以创建一个“迷宫”的执行路径。解锁脚本可以提供一个选择执行路径的“地图”以进行真正的执行:
IF
script A
ELSE
IF
script B
ELSE
script C
ENDIF
ENDIF在这种情况下,有三个执行路径(Script A、Script B和Script C)。解锁脚本以TRUE或FALSE值序列的形式提供路径。例如要选择路径Script B,解锁脚本必须以10(TRUE,FALSE)结束。这些值将被推送到栈,以便第二个值(FALSE)结束于栈的顶部。外部IF子句弹出FALSE值并执行第一个ELSE子句。然后,TRUE值移动到栈的顶部,并通过内部(嵌套)IF来执行,选择B执行路径。
使用这个结构,我们可以用数十或数百个执行路径构建赎回脚本,每个脚本提供了一种不同的方式来兑换UTXO。
如要花费,我们构建一个解锁脚本,通过在每个流控制点的栈上放置相应的TRUE和FALSE值来导航执行路径。
复杂的脚本示例
我们继续使用了迪拜公司所有者Mohammed的故事作为例子,他们正在经营进出口业务。
在这个例子中,Mohammed希望用灵活的规则建立公司资本账户。他创建的方案需要不同级别的授权,具体执行取决于时间锁。多重签名计划的参与者是Mohammed,他的两个合作伙伴Saeed和Zaira,以及他们公司的律师Abdul。三者根据多数原则做出决定,因此三者中的两个必须同意才能花费资金。然而,如果他们的钥匙有问题,他们希望他们的律师作为伙伴签名之一来使用资金。最后,如果所有合作伙伴都暂时无法联系到或无法工作,他们希望律师能够直接管理账户。
这是Mohammed设计的脚本(具有时间锁变量的多重签名):
1 IF 2 IF 3 2 4 ELSE 5 <30days> CHECKSEQUENCEVERIFY DROP <Abdul the Lawyer's Pubkey> CHECKSIGVERIFY 1 6 ENDIF 7 <Mohammed'sPubkey> <Saeed's Pubkey> <Zaira's Pubkey> 3 CHECKMULTISIG 8 ELSE 9 <90 days> CHECKSEQUENCEVERIFY DROP <Abdul the Lawyer's Pubkey> CHECKSIG 10 ENDIF
Mohammed的脚本使用嵌套的IF…ELSE流控制语句来实现三个执行路径。
- 在第一个执行路径中,该脚本作为三个合作伙伴的简单的2-of-3多重签名操作。该执行路径由第3行和第9行组成。第3行将多重签名的定额设置为2(2-of-3)。该执行路径可以通过在解锁脚本的末尾设置TRUE TRUE来选择:0 <Mohammed's Sig> <Zaira's Sig> TRUE TRUE。此解锁脚本开头的0是因为CHECKMULTISIG会错误地从栈中弹出一个额外的值。额外的值被CHECKMULTISIG忽略,否则脚本签名将失败。
- 第二个执行路径只能在UTXO创建30天后才能使用。那时候,它需要签署Abdul(律师)和三个合作伙伴之一(三分之一)。这是通过第7行实现的,该行将多选的法定人数设置为1。要选择此执行路径,解锁脚本将以FALSE TRUE结束:0 <Saeed's Sig> <Abdul's Sig> FALSE TRUE。为什么先FALSE后TRUE?反了吗?这是因为这两个值被推到栈,所以先push FALSE,然后push TRUE。因此,第一个IF操作码首先弹出的是TRUE。
- 第三个执行路径允许律师单独花费资金,但只能在90天之后。要选择此执行路径,解锁脚本必须以FALSE结束:<Abdul's Sig> FALSE
读者可以运行脚本来查看它在栈(stack)上的运行过程。
阅读这个例子还需要考虑几件事情。
- 为什么律师可以随时通过在解锁脚本中选择FALSE来兑换第三个执行路径?
- 在UTXO被打包到区块的5天、35天与105天后分别有多少个执行路径可以使用?
- 如果律师失去密钥,资金是否会流失?如果91天过去了,你的答案是否会改变?
- 合作伙伴如何每隔29天或89天“重置”一次时间锁,以防止律师获得资金?
- 为什么这个脚本中的一些CHECKSIG操作码有VERIFY后缀,而其他的没有?
五、比特币网络
点对点网络架构
比特币是在互联网之上依照点对点网络架构来设计的。点对点(peer-to-peer),或者说P2P,是指参与网络的每台计算机都是平等的,不存在“特殊”节点,所有节点分担提供网络服务的压力。网络节点以一种“扁平”拓扑结构在网状网络中相互连通。
在P2P网络中不存在服务器,没有中心化的服务,也不存在层级结构。一个P2P网络中的各节点同时提供服务和消费服务,这种互惠运作就是他们参与的动机。P2P网络天生具有弹性、去中心化和开放的特征。早期互联网就是P2P网络架构的一个卓越例子,IP网络中各节点是平等的。今天互联网架构有更多的层次性,但互联网协议仍然保持了扁平拓扑的本质。
在比特币之外,最大也是最成功的P2P技术应用是文件共享,Napster是这种架构的先驱而BitTorrent(BT下载)是它最近的演化。
比特币的P2P网络架构远不止一个单纯的拓扑选择。比特币被设计成一个P2P的数字现金系统,它的网络架构既是这个核心特征的反映,也是它的基础。控制的去中心化是它的一个核心设计原则,只能通过一个扁平的、去中心化的P2P共识网络来实现和维护。
“比特币网络”指的是运行比特币P2P协议的节点集合。在比特币P2P协议之外,比特币网络还包含其他的协议,例如Stratum,被用于挖矿,轻量级或者移动钱包。基于比特币协议访问比特币网络的网管路由器提供这些额外协议,将网络扩展到运行其他协议的节点。
- 矿机与矿池软件之间的通讯协议是stratum
- 矿池软件与钱包之间的通讯是bitcoinrpc接口
举个例子,Stratum服务器通过Stratum协议连接Stratum挖矿节点到比特币主网,并将Stratum协议桥接到比特币P2P协议。我们使用“扩展比特币网络”来代指包括了比特币P2P协议、矿池挖矿协议、Stratum协议以及其他任何连接比特币系统组件的相关协议的整体网络。
节点类型和角色
尽管比特币P2P网络中的节点彼此对等,但取决于支持的功能,它们可能扮演不同角色。一个比特币节点是一个功能集合:路由、区块链数据库、挖矿和钱包服务。包括全部四个功能的全节点如下图所示:
为了参与网络,所有节点必须包括路由功能,同时还可能包括其他功能。所有节点都验证和传播交易与区块,并发现维护与对等节点的连接。
在上图的全节点例子中,路由功能由一个名为“网络路由节点”或者带有字母“N”的圆圈表示。
一些节点维护了一份完整、最新的区块链副本,它们被称为“全节点”。全节点可以无须任何外部参照地自主验证任何交易。一些节点仅仅维护了区块链的一个子集,它们通过一种叫作“简易支付验证”(Simplified payment Verification,SPV)的方法验证交易。这些节点被称为SPV节点或轻量节点。
上图所示的全节点例子中,它的数据库功能由一个叫作“全区块链”或者字母“B”的圆圈表示,SPV节点则没有区块链的完整副本。
挖矿节点通过运行在特殊硬件上的工作量证明(Proof-of-Work)算法,以相互竞争的方式创建新的区块。一些挖矿节点同时也是全节点,维护了区块链的完整副本;其他的是轻量节点,参与矿池挖矿,它们依赖于矿池服务器来维护一个全节点。挖矿功能在全节点中由一个叫作“矿工”或者字母“M”的黑色圆圈表示。
用户钱包也可能是全节点的一部分,这在桌面比特币客户端上比较常见。但越来越多的用户钱包,尤其是运行在诸如智能手机等资源有限设备上的钱包都是SPV节点。钱包功能在下图中由一个叫作“钱包”或者字母“W”的绿色圆圈展示。
除了这些比特币P2P协议的主要节点类型之外,还有一些服务器和节点运行了其他的协议,例如特殊矿池挖矿协议、轻量级客户端访问协议等。
下图描述了扩展比特币网络中最为常见的节点类型。

扩展比特币网络
运行比特币P2P协议的比特币主网由5000~8000个运行不同版本比特币内核客户端(Bitcoin Core)的监听节点,以及数以百计的运行各类比特币P2P协议实现(例如,Bitcoin Classic、Bitcoin Unlimited、BitcoinJ、Libbitcoin、btcd和bcoin等)的节点组成。
比特币P2P网络中的一小部分节点也是挖矿节点,它们竞争挖矿,验证交易,并创建新的区块。许多大公司通过运行基于比特币内核客户端的全节点客户端来接入比特币网络,它们具备区块链的完整副本和网络节点,但不具备挖矿和钱包的功能。这些节点作为网络的边缘路由器,通过它们能构建其他服务(交易所、钱包、区块浏览器、商家支付处理)等。
如前所述,扩展比特币网络既包括了运行比特币P2P协议的网络,也包含运行特殊协议的节点。连接在比特币P2P主网上的是一些矿池服务器以及协议网关,它们把运行其他协议的节点连接起来。这些节点大都是矿池挖矿节点和轻量钱包客户端,它们通常不带有区块链的完整备份。
下图展示了扩展比特币网络,它包括多种类型的节点、网关服务器、边缘路由器、钱包客户端以及它们相互连接用到的各类协议。
比特币中继网络
虽然比特币P2P网络能服务于各种类型节点的普遍需求,但对比特币挖矿节点的特殊需求,它的网络延迟显得太高了。
比特币矿工已经被卷入了一场关于解决工作量证明和延伸区块链问题的竞争,这个竞争是非常时间敏感的。在这场竞争中,比特币矿工必须最小化在传播一个获胜区块和开始下一轮竞争之间的时间。在挖矿行业,网络延时直接和利润率相关。
比特币中继网络是一个尝试最小化在矿工之间传送区块延时的网络。最初的比特币中继网络(http://www.bitcoinrelaynetwork.org)是核心开发者Matt Corallo在2015年创建的,以便能在矿工之间以极低延时实现区块的快速同步。这个网络由几个托管在全球Amazon Web Service(由美国亚马逊公司提供的云计算服务)的基础设施上的特殊节点组成,用来连接绝大多数的矿工和矿池。
最初的比特币中继网络在2016年被替换成快速互联网比特币中继引擎(Fast Internet Bitcoin Relay Engine,简称为FIBRE,参见http://bitcoinfibre.org),它还是由核心开发者Matt Corallo创建的。FIBRE是一个基于UDP协议的中继网络,在网络节点之间传播区块。FIBRE实现了紧凑区块(compact block)的优化来进一步降低传送的数据量与网络延时。
Falcon(http://www.falconnet.org/about)是另一个中继网络(仍在提案阶段),它是基于康奈尔大学的研究提出的。Falcon使用“直通式路由”而非“存储-转发”来降低延时。这种方法当收到一个区块的一部分内容时就开始传输,而不是等到完整的区块被接收。
中继网络不是比特币P2P网络的替代品。相反,它们是覆盖网络,为存在特殊需求的节点之间提供额外的链接。就好像高速公路不是村道的替代品,而是交通繁忙的两点之间的捷径,但你仍然需要有小路连接到高速公路。
网络发现
当一个新的节点启动后,为了参与网络协同,它必须发现网络中其他的比特币节点。为了开始这个过程,一个新节点必须至少发现一个现存网络节点并连接上它。因为比特币网络拓扑不以地理位置定义,其他节点的地理位置是完全无关的,所以任意现有比特币节点可以随机选取。
为了连接到一个已知节点,节点间要建立一个TCP连接,通常在8333端口上(这个端口号通常就被当作比特币使用的),或者如果有指定端口也可以使用指定端口。在建立连接时,节点会通过发送一个包含基本识别信息的版本消息开始一次“握手”(见下图)。
对等节点之间的握手
消息内容包括:
- nVersion:客户端使用比特币P2P协议版本(例如:70002)。
- nLocalServices:节点支持的本地服务列表,现在这个值就是NODE_NETWORK。
- nTime:当前时间。
- addrYou:当前节点所见的远程节点IP地址。
- addrMe:本地节点发现的本地节点IP地址。
- subver:子版本信息,用于展示本节点运行的软件类型(例如:/Satoshi:0.9.2.1/)。
- BestHeight:本节点区块链的块高。
(版本网络消息的例子可以参见Github(http://bit.ly/1qlsC7w)。)
version(版本)消息始终是从一个节点到另一个节点发送的第一条消息。收到version消息的本地节点会检查远程节点报告的nVersion内容以判断远程节点是否兼容。如果远程节点兼容,本地节点会确认version信息并通过回送一个verack建立连接。
一个新节点如何发现对等节点呢?
第一种方法是使用若干“DNS种子”来查询DNS,DNS种子是提供比特币节点IP地址列表的DNS服务器。其中一些DNS种子提供稳定比特币监听节点IP地址的静态列表。一些DNS种子则是BIND(Berkeley Internet Name Daemon)的自定义实现,它们返回的一个比特币节点地址列表的随机子集,这个列表通过一个爬虫或者长时间运行的比特币节点来收集。比特币核心客户端包含五个不同DNS种子的名字。DNS种子所有权,以及DNS种子实现方式上的多样性为初始引导过程提供了高可靠性水平。
在比特币核心客户端,使用DNS种子的选项由选项开关-dnsseed控制(默认设为1,代表使用DNS种子)。
或者,对网络完全不了解的引导节点必须被提供至少一个比特币节点的IP地址,在这之后它可以通过进一步引导建立连接。命令行参数-seednode可以将指定节点当作种子来连接。当初始种子节点被用来形成引导,客户端会从它断开,然后使用新发现的对等节点
当一个或多个连接被建立,新的节点会向它的邻居发送包含自己IP地址的一个addr消息。它的邻居们会接着将这条addr消息转发给它们的邻居们,保证新接入的节点变得众所周知并被更好地连接到网络。此外,新接入的节点可以发送getaddr消息给它的邻居,要求它们返回其他对等节点的IP地址列表。这样一个节点可以发现能连接的对等节点并在网络上广而告之自己的存在以让其他节点能发现它。
下图展示了地址发现协议。
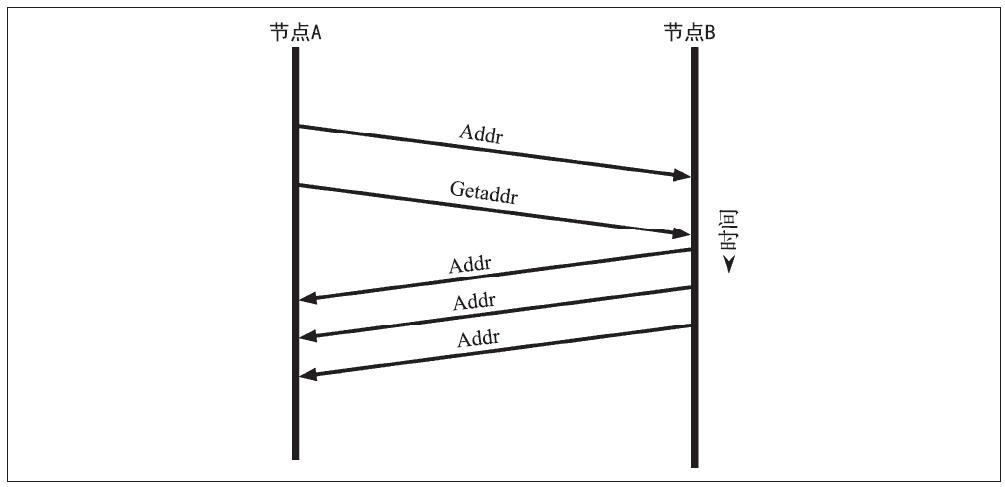
一个节点必须连接到若干个不同的对等节点以建立进入比特币网络的不同路径。路径并不是一直可靠的(因为节点可以随时加入和离开),所以当节点丢失老的连接时,还有为其他节点提供引导辅助时,它必须持续发现新节点。
新节点开始引导的时候只需要一个链接,因为第一个节点可以引导到它的对等节点,而这些对等节点可以提供进一步的引导。并且无须连接到超过一个节点,这是一种网络资源的浪费。在引导之后,节点会记住它最近连接成功的对等节点,所以当它重启之后,它可以从之前的对等网络中快速重建连接。如果之前的对等节点没有响应它的连接请求,它可以再次使用种子节点进行引导。
在一个运行比特币核心客户端的节点上,你可以使用getpeerinfo命令列出全部对等节点的连接信息:
./src/bitcoind -daemon # Starts the bitcoin daemon.
./src/bitcoin-cli --help # Outputs a list of command-line options.
./src/bitcoin-cli help # Outputs a list of RPC commands when the daemon is running.
./bitcoin-cli getpeerinfo
[
{
"id": 0,
"addr": "88.67.80.94:8333",
"addrbind": "30.221.128.229:50639",
"addrlocal": "140.205.11.5:38557",
"network": "ipv4",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": false,
"lastsend": 1668654105,
"lastrecv": 1668654105,
"last_transaction": 0,
"last_block": 1668654105,
"bytessent": 103766,
"bytesrecv": 42646322,
"conntime": 1668653983,
"timeoffset": 0,
"pingtime": 0.308433,
"minping": 0.308433,
"version": 70016,
"subver": "/Satoshi:23.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
139611,
139612,
139613,
139614,
139615,
139616,
139778,
139779,
139780,
139781,
139782,
139783,
139786,
139788,
139789,
139790
],
"addr_relay_enabled": false,
"addr_processed": 0,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00000000,
"bytessent_per_msg": {
"getdata": 102304,
"getheaders": 1053,
"headers": 25,
"ping": 64,
"pong": 64,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"block": 42640371,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 64,
"pong": 64,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "block-relay-only"
},
{
"id": 2,
"addr": "47.254.45.175:8333",
"addrbind": "30.221.128.229:50657",
"addrlocal": "140.205.11.5:38575",
"network": "ipv4",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654106,
"lastrecv": 1668654106,
"last_transaction": 0,
"last_block": 1668654106,
"bytessent": 133465,
"bytesrecv": 55307557,
"conntime": 1668653996,
"timeoffset": -1,
"pingtime": 0.386185,
"minping": 0.386185,
"version": 70016,
"subver": "/Satoshi:22.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
139630,
139631,
139632,
139731,
139733,
139735,
139737,
139738,
139773,
139774,
139776,
139777,
139804,
139806,
139807,
139809
],
"addr_relay_enabled": true,
"addr_processed": 1002,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00001000,
"bytessent_per_msg": {
"addrv2": 40,
"feefilter": 32,
"getaddr": 24,
"getdata": 131971,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 17455,
"block": 55285338,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 3,
"addr": "[2001:470:da72::2:3]:8333",
"addrbind": "[fd00:1:5:5200:97a5:6689:f4c1:34d7]:50659",
"addrlocal": "[2401:b180:1000:2:896b:ed61:896b:ed61]:32232",
"network": "ipv6",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654106,
"lastrecv": 1668654106,
"last_transaction": 0,
"last_block": 1668654106,
"bytessent": 62081,
"bytesrecv": 25278805,
"conntime": 1668653997,
"timeoffset": -14,
"pingtime": 0.572503,
"minping": 0.572503,
"version": 70016,
"subver": "/Satoshi:22.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
139662,
139663,
139664,
139791,
139794,
139796,
139797,
139803,
139812,
139814,
139815,
139819,
139820,
139821,
139822,
139824
],
"addr_relay_enabled": true,
"addr_processed": 1001,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00002527,
"bytessent_per_msg": {
"feefilter": 32,
"getaddr": 24,
"getdata": 60627,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 21187,
"block": 25252395,
"feefilter": 64,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 5,
"addr": "174.109.163.52:8333",
"addrbind": "30.221.128.229:50661",
"addrlocal": "140.205.11.5:14415",
"network": "ipv4",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654105,
"lastrecv": 1668654103,
"last_transaction": 0,
"last_block": 1668654103,
"bytessent": 52688,
"bytesrecv": 20763156,
"conntime": 1668653999,
"timeoffset": -148,
"pingtime": 1.019879,
"minping": 1.019879,
"version": 70016,
"subver": "/Satoshi:23.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138911,
"inflight": [
139665,
139666,
139667,
139668,
139669,
139670,
139671,
139672,
139673,
139674,
139675,
139676,
139677,
139678,
139679,
139680
],
"addr_relay_enabled": true,
"addr_processed": 1001,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00002297,
"bytessent_per_msg": {
"feefilter": 32,
"getaddr": 24,
"getdata": 51234,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 17485,
"block": 20744128,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 6,
"addr": "[2001:41d0:405:9600::]:8333",
"addrbind": "[fd00:1:5:5200:97a5:6689:f4c1:34d7]:50662",
"addrlocal": "[2401:b180:1000:2:896b:ed61:896b:ed61]:36331",
"network": "ipv6",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654102,
"lastrecv": 1668654102,
"last_transaction": 0,
"last_block": 1668654102,
"bytessent": 64976,
"bytesrecv": 27371734,
"conntime": 1668654000,
"timeoffset": -1,
"pingtime": 0.585595,
"minping": 0.585595,
"version": 70016,
"subver": "/Satoshi:22.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138553,
"inflight": [
139362,
139365,
139374,
139376,
139378,
139383,
139392,
139405,
139433,
139434,
139435,
139436,
139437,
139438,
139439,
139476
],
"addr_relay_enabled": true,
"addr_processed": 1002,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00002779,
"bytessent_per_msg": {
"addrv2": 52,
"feefilter": 32,
"getaddr": 24,
"getdata": 63470,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 17687,
"block": 27352504,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 7,
"addr": "83.8.50.227:8333",
"addrbind": "30.221.128.229:50667",
"addrlocal": "140.205.11.5:14421",
"network": "ipv4",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654105,
"lastrecv": 1668654106,
"last_transaction": 0,
"last_block": 1668654105,
"bytessent": 14286,
"bytesrecv": 5425942,
"conntime": 1668654006,
"timeoffset": -2,
"pingtime": 0.426027,
"minping": 0.426027,
"version": 70016,
"subver": "/Satoshi:23.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
138915,
138916,
138917,
138918,
138919,
139032,
139407,
139453,
139454,
139534,
139598,
139599,
139600,
139695,
139718,
139771
],
"addr_relay_enabled": true,
"addr_processed": 1000,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00002527,
"bytessent_per_msg": {
"addrv2": 52,
"feefilter": 32,
"getaddr": 24,
"getdata": 12780,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 17575,
"block": 5391688,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 9,
"addr": "142.127.159.213:8333",
"addrbind": "30.221.128.229:50669",
"addrlocal": "140.205.11.5:56710",
"network": "ipv4",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654106,
"lastrecv": 1668654106,
"last_transaction": 0,
"last_block": 1668654106,
"bytessent": 34001,
"bytesrecv": 15026700,
"conntime": 1668654008,
"timeoffset": -1,
"pingtime": 0.663724,
"minping": 0.663724,
"version": 70016,
"subver": "/Satoshi:0.21.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
139685,
139686,
139687,
139688,
139689,
139690,
139691,
139692,
139693,
139694,
139717,
139723,
139775,
139792,
139825,
139826
],
"addr_relay_enabled": true,
"addr_processed": 1004,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00002779,
"bytessent_per_msg": {
"feefilter": 32,
"getaddr": 24,
"getdata": 32547,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 17925,
"block": 15003966,
"feefilter": 64,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 11,
"addr": "[2a01:4f8:10b:29e9::2]:8333",
"addrbind": "[fd00:1:5:5200:97a5:6689:f4c1:34d7]:50672",
"addrlocal": "[2401:b180:1000:2:896b:ed61:896b:ed61]:40405",
"network": "ipv6",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": false,
"lastsend": 1668654106,
"lastrecv": 1668654106,
"last_transaction": 0,
"last_block": 1668654106,
"bytessent": 73285,
"bytesrecv": 32210070,
"conntime": 1668654011,
"timeoffset": -3,
"pingtime": 0.248895,
"minping": 0.248895,
"version": 70016,
"subver": "/Satoshi:22.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
139793,
139795,
139798,
139799,
139800,
139801,
139802,
139805,
139808,
139810,
139811,
139813,
139816,
139817,
139818,
139823
],
"addr_relay_enabled": false,
"addr_processed": 0,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00000000,
"bytessent_per_msg": {
"getdata": 71887,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 52,
"block": 32208475,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "block-relay-only"
},
{
"id": 12,
"addr": "72.29.170.151:8333",
"addrbind": "30.221.128.229:50691",
"addrlocal": "140.205.11.5:38609",
"network": "ipv4",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654105,
"lastrecv": 1668654105,
"last_transaction": 0,
"last_block": 1668654105,
"bytessent": 11965,
"bytesrecv": 4059919,
"conntime": 1668654024,
"timeoffset": -55,
"pingtime": 0.18453,
"minping": 0.18453,
"version": 70016,
"subver": "/Satoshi:0.21.1/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138913,
"inflight": [
138964,
138965,
138995,
139067,
139123,
139124,
139174,
139492,
139556,
139712,
139713,
139714,
139715,
139716,
139739,
139740
],
"addr_relay_enabled": true,
"addr_processed": 1001,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00001000,
"bytessent_per_msg": {
"addrv2": 40,
"feefilter": 32,
"getaddr": 24,
"getdata": 10471,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 21721,
"block": 4014050,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
},
{
"id": 13,
"addr": "[240e:3b5:3471:4cf1:b142:9526:ad21:d027]:8333",
"addrbind": "[fd00:1:5:5200:97a5:6689:f4c1:34d7]:51072",
"addrlocal": "[2401:b180:1000:2:896b:ed61:896b:ed61]:15977",
"network": "ipv6",
"services": "0000000000000409",
"servicesnames": [
"NETWORK",
"WITNESS",
"NETWORK_LIMITED"
],
"relaytxes": true,
"lastsend": 1668654106,
"lastrecv": 1668654106,
"last_transaction": 0,
"last_block": 1668654106,
"bytessent": 4373,
"bytesrecv": 847765,
"conntime": 1668654103,
"timeoffset": 0,
"pingtime": 0.073421,
"minping": 0.073421,
"version": 70016,
"subver": "/Satoshi:23.0.0/",
"inbound": false,
"bip152_hb_to": false,
"bip152_hb_from": false,
"startingheight": 763514,
"presynced_headers": -1,
"synced_headers": 763514,
"synced_blocks": 138914,
"inflight": [
139749,
139750,
139751,
139752,
139753,
139754,
139755,
139768,
139769,
139770,
139772,
139784,
139785,
139787,
139827,
139828
],
"addr_relay_enabled": true,
"addr_processed": 1000,
"addr_rate_limited": 0,
"permissions": [
],
"minfeefilter": 0.00002527,
"bytessent_per_msg": {
"feefilter": 32,
"getaddr": 24,
"getdata": 2919,
"getheaders": 1053,
"headers": 25,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 33,
"sendheaders": 24,
"verack": 24,
"version": 127,
"wtxidrelay": 24
},
"bytesrecv_per_msg": {
"addrv2": 17537,
"block": 792492,
"feefilter": 32,
"getheaders": 1053,
"headers": 106,
"ping": 32,
"pong": 32,
"sendaddrv2": 24,
"sendcmpct": 66,
"sendheaders": 24,
"verack": 24,
"version": 126,
"wtxidrelay": 24
},
"connection_type": "outbound-full-relay"
}
]用户可以通过提供-connect=<IPAddress>的选项来指定一个或多个IP地址,来覆盖原本的对等节点自动管理设置以及指定一个IP地址列表。如果这个选项被使用,该节点只会连接指定的IP地址,而不是自动发现并维护对等节点连接。
如果一个连接上没有通信,节点会定期发送一个消息以维持这个连接。如果一个节点在一个连接上超过90分钟没有通信,它会被认为已经从这个连接断开并寻找一个新的对等节点。这样,网络对动态节点和网络问题进行动态调整,在没有中央控制的情况下有机地增长和收缩。
全节点
全节点是维护了包含全部交易的一个全区块链节点。更准确地说,它们应该被称为“全区块链节点”。
在区块链的早期,所有节点都是全节点,现在比特币内核客户端也是一个全区块链节点。但随着比特币网络的规模不断扩大,不维护全区块链,而只是作为轻量客户端的多种新形态比特币客户端被引入。
全区块链节点维护了一份完整的、最新的包含全部交易的比特币区块链副本。这份副本由节点独立构建和检验,从最初的第一个区块(创世区块)开始一直构建到网络中的最新已知区块。一个全区块链节点可以独立可信地验证任何交易,而无须求助于或者依赖于其他节点或是信息源。全区块链节点依赖网络来接收关于新交易区块的更新,在验证之后合并到它本地的区块链副本中。
运行一个全区块链节点给你一个纯正的比特币体验:独立验证所有交易而无须依赖或者信任任何其他系统。可以很容易地判断出你是否运行了一个全节点,因为它需要超过100GB的永久存储(硬盘空间)来保存全区块链。如果你需要很多硬盘,并且同步一次到主网需要两到三天时间,那么你在运行一个全节点,这是与中央集权完全相反的独立自由的代价。
有几种全区块链客户端的实施方式,使用不同的编程语言和软件架构。但是,通常实施都参考比特币内核客户端,也被称为“中本聪”节点。比特币网络上超过75%的节点运行了不同版本的比特币内核。它被识别成“Satoshi”,包括在发送的版本消息的sub-version字符串中,并通过之前提到过的getpeerinfo命令来展示,例如,/Satoshi:0.8.6/。
交换”库存清单“
一个全节点连接到对等节点之后,要做的第一件事情是尝试创建一个完整区块链。如果这是一个全新节点,没有任何区块链信息,它只知道一个区块被静态嵌入在客户端软件中的创世区块。从#0号区块(创世区块)开始,新节点必须下载成千上万的区块以和网络同步并重建完整区块链。
同步区块链的过程以version(版本)消息开始,因为它包含了BestHeight信息,即一个节点的当前块高(区块的数量)。一个节点会从它的对等节点看到version消息,知道对等节点拥有的区块数量,进而和自己区块链上的区块数量进行比较。对等节点会交换一个包括它们本地区块链顶部区块散列值(指纹)的getblocks消息。如果一个对等节点能识别出接收到的散列值属于一个非顶部区块,而是属于一个更老的区块,那么就可以推断出它本地的区块链比它对等节点的区块链更长。
有更长区块链的对等节点比其他节点有更多的区块,能识别出其他节点需要哪些区块来“补齐”。它会识别出第一批500个区块,使用一个inv(库存)消息来分享和传送它们的散列值。缺少这些区块的节点之后就可以通过发送一系列getdata消息,使用来自inv消息的散列值信息来识别需要的区块并请求完整区块数据。
举个例子,让我们假设如果一个节点仅包含创世区块。它会从它的对等节点收到一个inv消息,包含链上下500个区块的散列值。它会开始向所有它连接上的对等节点请求区块,请求负载是分散的以保证它不会冲垮任何一个对等节点。该节点会跟踪每个对等节点连接上有多少区块是“正在传送”(它已经请求但是还没有接收到的区块)的,并检查该数量没有超过上限(MAX_BLOCKS_IN_TRANSIT_PER_PEER)。这样当该节点需要大量区块的时候,
它只会在之前请求被满足之后再去请求新区块,从而允许对等节点控制更新节奏,不至于冲垮整个网络。当每个区块都被收到之后,它被加入区块链。当本地区块链被逐步建立,更多的区块被请求和收到,这个过程会持续到节点和网络其他节点完成同步。
当一个节点离线,不论离线时间有多长,这个比较本地与对等节点的区块链,并接收缺失区块的过程就会被触发。如果一个节点只离线几分钟,它只缺少了几个区块;如果离线了一个月,它缺少了几千个区块。但不论哪种情况,它都会从发送getblocks消息开始,收到一个inv的响应,接着开始下载缺少的区块。
下图展示了库存与区块广播协议。
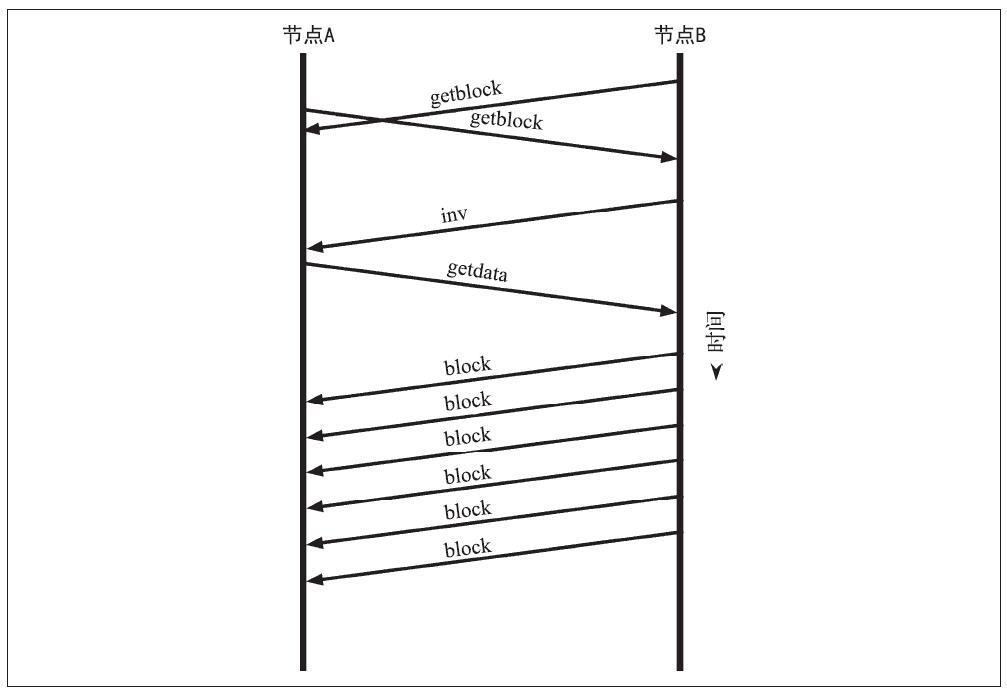
简易支付验证(SPV)节点
并非所有节点都有能力存储完整区块链。许多比特币客户端被设计成在空间和电源受限设备上运行,比如说智能手机、平板电脑或者嵌入式设备。对这些设备,通过一种简易支付验证(SPV)的方法可以允许它们在不存储完整区块链的情况下工作。这些类型的客户端被称为SPV客户端或者轻量客户端。随着比特币使用的兴起,SPV节点变成了比特币节点最常见的形式,尤其是对比特币钱包来说。
SPV节点仅下载区块头而不下载每个区块内包括的交易。由此得到的不包含交易的区块链,比完整区块链要小1000倍。SPV节点无法构建所有可用的UTXO的全貌,因为它们不知道网络上的全部交易。SPV节点的交易验证方法略有不同,它们依赖于对等节点按需提供区块链相关部分的局部视图。
打个比方,一个全节点就像在一个陌生城市中的游客,它带着一张标记了城市中每一条街道和每个地址的详细地图。作为对比,一个SPV节点就像在一个陌生城市的游客,他只知道一条主干道的名字,当要转弯的时候随机向陌生人确认转弯的方向。尽管两者都能够通过实地考察一条街道验证它的存在,没有地图的游客不知道附近有什么小路,也不知道还存在什么街道。站在教堂街23号前面,没有地图的游客无法知道城市中是否还有其他若干个“教堂街23号”的地址,也不知道当前这个地址是不是就是正确的那个。没地图游客最好的办法是问足够多的人,并且期望他们中的一些人不会戏弄他。
SPV通过参考区块链的深度而非高度来验证交易。一个全区块链节点会构建一个完全验证过的链,包含成千上万区块,及从它们开始沿着区块链(按时间逆序)一直追溯到创世区块中的全部交易。一个SPV节点会验证链上的所有区块(但不是所有交易),并把链和相关交易联系起来。
举个例子,当在块号300,000上检查一笔交易的时候,
- 一个全节点链接了从创世区块到全部300,000个区块,建立了一个完备的UTXO数据库,通过确认一个UTXO还没有被支付来验证交易的有效性。
- 一个SPV节点无法验证一个UTXO是否被支付,相反,SPV节点会用一个merkle路径在交易和包含它的区块之间建立联系。之后SPV节点会一直等到看见从300,001到300,006的6个区块被加在包含这笔交易的区块之上,并通过在区块300,006到300,001之下确立它的深度来验证交易。事实上,网络上其他节点接受300,000号区块,并在它之上至少又生成了6个区块,根据代理协议,就能证明这笔交易不是双重花费。
当一笔交易实际上不存在的时候,SPV节点无法认可这笔交易存在一个区块中。SPV节点通过请求一个merkle路径的证明并验证区块链上的工作量证明,来确认一笔交易在一个区块中的存在。但是,一笔交易的存在对SPV节点而言有可能被“隐藏”。一个SPV节点毫无疑问可以证明一笔交易存在,但无法验证某笔交易不存在因为它没有所有交易的记录,比如一笔使用同样UTXO的双重花费。这个弱点会被针对SPV节点的拒绝服务攻击或者双重花费攻击利用。为了保护它,一个SPV节点需要随机连接到一些节点来提升它至少联系到一个诚实节点的可能性。需要该随机连接意味着SPV节点对于网络分区攻击或者Sybil攻击来说是脆弱的,这时它们被连接到虚假节点或者虚假网络,并且没有到诚实节点或真实比特币网络的访问。
对大多数实际目的来说,良好连接的SPV节点在资源需求、实用性和安全性之间达成了恰当的平衡,是足够安全的。但要万无一失的话,最好的办法就是运行一个全区块链节点。
一个全区块链节点通过检查整条链上在它自己之下成千上万的区块以确保UTXO未被花费,从而验证一笔交易。而一个SPV节点通过检查自己之上的若干个区块来验证自己被埋的深度。
为了得到区块头,SPV节点使用getheaders消息而不是getblocks消息。响应的对等节点会用一个headers消息发送不超过2000个区块头。这个过程和全节点获取所有区块是一样的。SPV节点还会在到对等节点的连接上设置一个过滤器,来过滤对等节点发送的未来块和消息的流。任何目标交易都是通过使用getdata请求来获取的,对等节点产生一条包含该交易的tx消息作为响应。下图展示了区块头的同步过程。
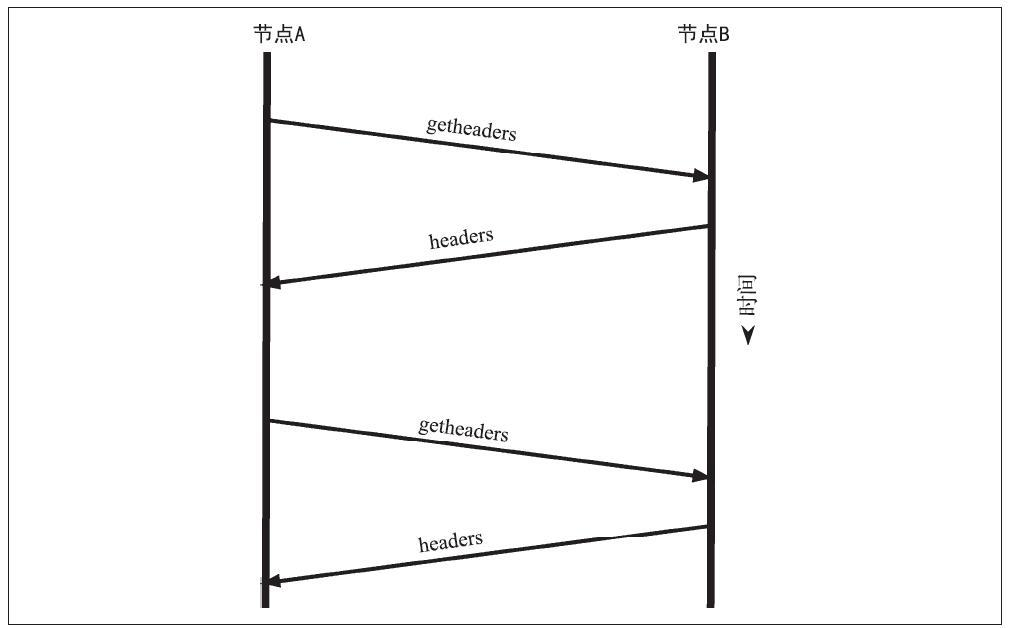
因为SPV节点需要获取特定交易以有选择地验证它们,它们还产生了一个隐私风险。不像全区块链节点收集了每个区块内的全部交易,SPV节点针对特定数据的请求可能无意间泄露了它们钱包的地址。举个例子,监控网络的第三方可以跟踪在SPV节点上的钱包所请求的全部交易,用它们来把钱包用户和这个比特币地址联系起来,从而破坏了用户隐私(本质上是因为SPV的范围缩小了,因此不再受P2P分布式的隐私保护)。
在引入了SPV轻量节点之后,比特币开发者增加了一个叫作bloom过滤器的功能来解决SPV节点的隐私风险。Bloom过滤器通过使用概率而非固定模式的过滤方法,允许SPV节点在不需要精确指定它们关心的地址的情况下接收一个交易子集。
Bloom过滤器
Bloom过滤器是一个概率搜索过滤器,它是一种通过描述所需模式而不需要精确表达的过滤方法。Bloom过滤器提供了一种有效的方法在保护隐私的同时表述一个搜索模式。SPV节点使用它们来向对等节点请求符合一定模式的交易,而不需要表露它们在搜索哪个地址、密钥或者交易。
在之前的示例中,一个没有地图的游客在询问到一个特定地址“教堂街23号”的方向。如果她向陌生人询问到这条街的方向,她无意中就暴露了她的目的地。一个Bloom过滤器就好像在问:“在这附近有没有名字拼音里按序包括R-C-H的街道?”这样提问比直接问“教堂街23号”稍微少泄露了一些关于目的地的信息。使用这种技巧,一个游客能够给出更多关于所问地址的更详细信息比如“街名以教堂结尾”,或者更少细节比如“街名拼音以H字母结束”。通过改变搜索的精度,游客可以暴露更多或者更少信息,相应的代价就是得到更准确或者更不准确的结果。如果她以一种更笼统的模式提问,她会得到更多的可能地址和更好的隐私保护,但这些地址里面的很多都是无关的。如果她以更特指的模式提问,她会得到更少的结果,但是会损失隐私性。
Bloom过滤器通过允许一个SPV节点指定一个针对交易的搜索模式。这个模式能够根据精度或者隐私的考虑被调节来实现这个功能。
- 一个更特指的bloom过滤器会产出准确的结果,但是代价就是暴露了SPV节点关注的是什么模式,从而暴露了用户钱包所拥有的地址。
- 一个更笼统的bloom过滤器会针对更多的交易产出更多的数据,很多都是和这个节点无关的,但是这样允许节点维护更好的隐私性。
Bloom过滤器如何工作
Bloom过滤器由一个可变长度的位数组(即N位二进制数,每个数组成员是一个位)和数量可变(M)的一组散列值函数构成。这些散列值函数被设计成根据位数组产生一个在1和N之间的输出。这些散列值函数是确定性的,所以任何实现了一个bloom过滤器的节点会始终使用同一个散列值函数,对于同一个特定输入会得到同样的结果。通过选择不同长度(N)的bloom过滤器和不同数字M的散列值函数集合,bloom过滤器的准确性和隐私性可以被调节。
在下图中,我们使用一个非常小的16位数组和一组3个散列值函数来展示bloom过滤器如何工作。
bloom过滤器初始化的时候位数组所有的成员都是0。要把一个模式加入bloom过滤器,该模式要被每个散列值函数依次运算一次。针对输入使用第一个散列值函数得到介于1和N之间的一个数字。数组中对应位(从1到N编号)被标记为1,从而记录下散列值函数的输出。然后下一个散列值函数被使用,标记掉另一个位,以此类推。
当所有M个散列值函数都被应用过,会有M位从0变成了1,搜索模式就这样被“记录”在bloom过滤器上的。
下图是一个增加模式“A”到上图中展示的简单bloom过滤器的例子。
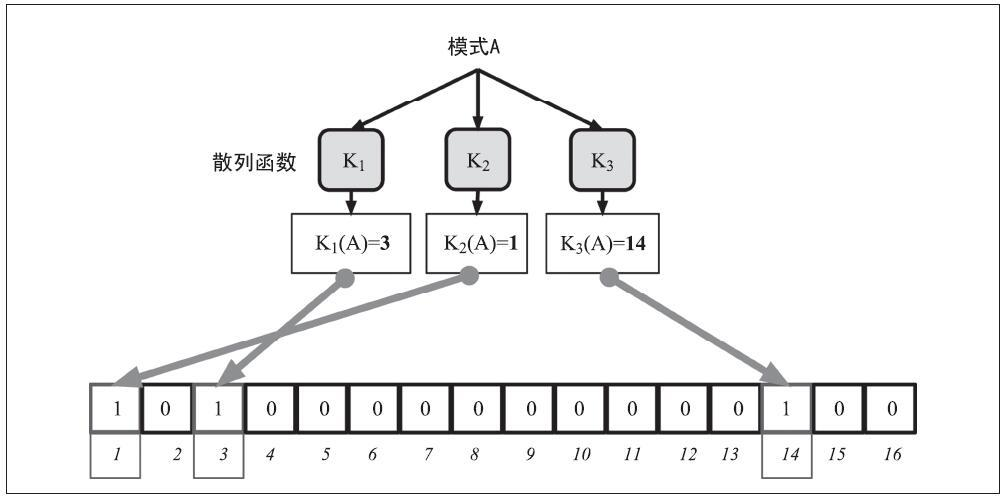
增加第二个模式只需简单重复之前的步骤即可。该模式被每个散列值函数依次计算,结果通过把位设成1进行记录。需要注意的是,随着更多的模式被填充到一个bloom过滤器,一个散列值函数的结果对应的位域可能已经被设为1了,这种情况下该位域不会再改变。
本质上,当更多的模式被记录在重叠的位域上,bloom过滤器中越来越多的位域被设为1,它开始变得饱和而过滤器的准确性也在降低。这是为什么过滤器是一个概率数据结构——当更多的模式被添加的时候,它变得更不精确。精确性取决于增加的模式数量和对应位数组的大小(N)和散列值函数的数量(M)。更大的位数组和更多的散列值函数可以以更高准确性记录更多模式。更小的位数组或者更少的散列值函数只能记录更少的模式,产生更低的准确性。
下图是一个将第二个模式“B”添加到简单bloom过滤器的例子。
为了测试一个模式是否属于bloom过滤器的一部分,模式必须被每个散列值函数计算过,结果模式基于位数组进行测试。如果所有被散列值函数计算和索引的位都被设成了1,那这个模式可能已经被记录在bloom过滤器中。但是因为位域可能被来自多个模式的叠加被设置,这个结论并不确定,而是有可能,因为这些重复可能是对其他模式的重叠。简单来说,一个bloom过滤器的正面匹配意味着“可能是”。
下图是在简单bloom过滤器中测试模式“X”的存在的一个例子。对应的位都被设成1,所以该模式可能是匹配的。
如果一个模式被拿来和bloom过滤器比较,过滤器的每一位都被设为0,就证明这个模式并没有被bloom过滤器记录。一个负面的结果不是可能,而是确定。简单地说,一个bloom过滤器的负面的匹配结果代表“肯定不是”。
下图是在简单的bloom过滤器中检验模式“Y”的存在的例子。某个对应位被设为0,所以这个模式一定不匹配。
SPV节点如何使用Bloom过滤器
Bloom过滤器被SPV节点用来过滤从它的对等节点接收到的交易(以及包含交易的区块),仅选择SPV节点感兴趣的交易而不用暴露它感兴趣的地址或者密钥。
一个SPV节点会将一个bloom过滤器初始化为“空”;该状态下bloom过滤器不匹配任何模式。之后SPV节点会列出它感兴趣的所有地址、密钥和散列值。它通过从钱包控制的任意UTXO来提取公钥散列值、脚本散列值和交易ID,进而生成这些列表。
SPV节点会把这些信息都加入bloom过滤器,这样bloom过滤器可以判断一笔交易是否与这些模式“匹配”而不用泄露模式本身。
SPV节点之后会发送一个filterload消息给对等节点,包含了要在连接上使用的bloom过滤器。在对等节点上,针对每笔传入交易检查过滤器。全节点根据bloom过滤器检查交易的几个部分来寻找匹配,包括:
- 交易ID
- 来自每个事务输出的锁定脚本的数据组件(每个密钥和脚本中的散列值)
- 每个交易输入
- 每个输入签名数据组件(或者叫见证脚本)
通过检查这些组件,bloom过滤器可以被用来匹配公钥散列值、脚本、OP_RETURN值、签名公钥,或者任何智能合约或复杂脚本中的未来组件。
当一个过滤器被建立之后,对等节点会按照bloom过滤器检验每笔交易的输出。只有匹配过滤器的交易才会被发往原节点。
作为对来自原节点getdata消息的响应,对等节点会发送一个merkleblock消息,其中仅包含匹配过滤器的区块的头和每笔匹配交易的merkle路径。之后对等节点会发送包括过滤器匹配到的所有交易的tx消息。
当全节点向SPV节点发送交易,SPV节点会丢弃所有误报交易,仅使用正确匹配上的交易来更新它的UTXO集合和钱包余额。当它更新它自己的UTXO视图的时候,它也会修改bloom过滤器来匹配引用到它刚发现的UTXO的未来交易。之后全节点使用新的bloom过滤器来匹配新交易,并重复这个流程。
设置bloom过滤器的节点可以通过发送filteradd消息交互地向过滤器添加模式。要清除bloom过滤器,节点发送filterclear消息。因为从bloom过滤器移除一个模式是不可能的,当一个模式不再被需要,节点必须彻底清除全部模式然后重新发送一个新的bloom过滤器。
SPV节点的网络协议和bloom过滤器机制在BIP-37(对等服务)(http://bit.ly/1x6qCiO)中被定义。
本质上,bloom过滤器是基于隐写的安全思想建立的,将自己希望保密的信息隐写到一种模式匹配算法中,然后将算法暴露到公网中,攻击者即使拿到了这个模式匹配算法,也无法精确识别出被隐写的内容。在公网中传递的消息是包含了被隐写内容以及无关的干扰信息。
SPV节点和隐私
实施SPV的节点比全节点的隐私性更弱。一个全节点接收全部交易,所以不会泄露它是否在其钱包中使用某个地址。一个SPV节点根据在它钱包中的地址接受过滤过的交易列表。这样会降低对所有者隐私的保护。
Bloom过滤器是降低隐私损失的方法。没有它,SPV节点必须显式地列出它感兴趣的地址,造成很严重的隐私泄露。尽管有了bloom过滤器,对手也可以监视SPV客户端的流量,或者直接作为P2P的一个节点连接到SPV节点,随着时间的推移,收集到足够的信息来了解SPV客户端的钱包中的地址。
加密与认证连接
大多数比特币的新用户都假设比特币节点的网络通信是加密的。实际上,比特币通信的原始实现是完全明晰可见的。这对全节点来说不是一个主要的隐私顾虑,但对SPV节点来说是个大问题。
作为提升比特币P2P网络隐私性和安全性的一种方法,有两种通信加密的解决方案:
- Tor传输
- BIP-150/151下的P2P认证和加密
(1)Tor传输
Tor代表了洋葱路由网络(The Onion Routing network),它是一个通过匿名、不可追溯和隐私性的随机网络路径来提供数据加密和封装的软件项目和网络。
比特币内核提供了几种配置选项允许你运行通过Tor网络传输流量的比特币节点。此外,比特币内核还提供了一个Tor隐藏服务,允许其他Tor节点直接通过Tor连接到你的节点。
截止到比特币内核版本0.12,如果一个节点能够连接到一个本地Tor服务,它会自动提供一个隐藏的Tor服务。如果你安装了Tor,并且比特币内核进程作为一个拥有足够权限的用户可以访问Tor认证cookie,它应该可以自动运行。可以使用如下方法来用debug标记开启比特币内核对Tor服务的调试:
$ bitcoind --daemon --debug=tor
你应当可以在日志中看到“tor:Add_ONION successful”,表示比特币内核已经向Tor网络添加了一个隐藏服务。
你可以在比特币内核文档(doc/tor.md)和一些在线教程中发现更多关于将比特币内核作为一个Tor隐藏服务运行的说明。
(2)P2P认证和加密
比特币提升提案BIP-150和BIP-151,在比特币P2P网络中添加了对认证和加密的支持。这两个BIP定义了兼容的比特币节点可以提供的可选服务。
- BIP-151在两个支持BIP-151的节点间的全部通信上启用协商加密。
- BIP-150提供了可选的对等认证,允许节点使用ECDSA和私钥相互认证彼此的身份。BIP-150在认证前要求两个节点已经按照BIP-151建立了加密通信。
BIP-150和BIP-151允许用户运行一个SPV客户端,连接到一个被信任的全节点,并使用加密和认证来保护SPV客户端的隐私。
此外,认证可以被用来创建受信比特币节点的网络,防止中间人攻击。最后,如果P2P加密被广泛部署,会加强比特币对流量分析和侵犯到隐私的监视的抵抗能力,尤其是在互联网使用受到严格控制和监控的极权国家。
这个标准在BIP-150(对等认证)(https://github.com/bitcoin/bips/blob/master/bip-0150.mediawiki)和BIP-151(点对点通信加密)(https://github.com/bitcoin/bips/blob/master/bip-0151.mediawiki)中定义。
交易池
几乎比特币网络上的每个节点都维护了一个叫作内存池或者交易池的未确认交易临时列表。节点用这个池子来跟踪已经被网络感知但还没有被包括到区块链的交易。
举个例子,一个钱包节点使用交易池来跟踪已经被网络接收但还没被确认的进入用户钱包的支付。当交易被接收到且验证过,它们被添加到交易池并通知附近节点,从而传播到网络上。
一些节点的实现还维护了一个单独的孤立交易的池子。如果一笔交易的输入指向一笔尚未被感知的交易,这笔交易就好像一个没有父母的孤儿一样,叫作孤儿交易。孤儿交易会被保存在这个池子里直到指向的交易到来。
当一笔交易被加入交易池,会首先检查孤儿交易池来判断里面是不是有引用到这笔交易输出的交易(它的孩子)。任何匹配的孤儿交易会跟着被检验。如果有效,则从孤儿交易池中移除,加入交易池,使以父交易开始的链变得完整。对于新近被加入的不再是一个孤儿的交易,这个过程会重复递归地寻找下一步的后代,直到所有的后代都被发现。通过这个过程,父交易的到达触发了一整条相互依赖交易的链的级联重建,沿着整条链将孤儿交易和它们的父交易组合在一起。
交易池和孤儿池(如果被实现)都存储在本地内存而非持久化存储中;更准确地说,它们是由流入的网络消息动态填充的。当一个节点启动,两个池子都是空的,之后逐渐被网络接收到的新交易填充。
比特币客户端的一些实现还维护了一个UTXO的数据库或者池子,其中存储了区块链上所有未被花费的输出的集合。尽管“UTXO池”这个名字听起来像是交易池,但它代表的是一类不同的数据。与交易池和孤儿池不同,UTXO池初始化时不为空,而是包含了上百万未被花费的交易输出条目,是一直追溯到创世区块的每条未被花费的交易输出。UTXO池可以位于本地内存,或者是在持久化存储中的一个带索引的数据库。
交易池和孤儿池代表了单个节点的本地视角,不同节点取决于各自启动或重启时间的不同可能有很大差别。UTXO池代表的是网络的浮现共识,因此节点之间的差异很小。此外,交易池和孤儿池仅包含未确认交易,而UTXO池仅包含确认交易。
六、区块链
简介
区块链数据结构是一个有序的,反向链接的交易块列表。区块链可以作为平面文件(Flat File)存储,也可以存储在简单的数据库中。比特币核心客户端使用Google的LevelDB数据库存储区块链元数据。
区块“向前”链接,每个块都指向链中的前一个块。区块链通常被显示为一个垂直栈,其中区块彼此堆叠,最底下的第一个区块作为栈的基础。人们根据这一个摞一个的区块形象设计了一些相关的术语,诸如“高度”指离开第一个区块的距离,而“顶部”或“顶端”指的是最近添加的区块。
区块链中的每个区块都由一个散列值来标识,这个散列值是对区块头(block header)使用SHA256加密散列算法得到的。每个区块都可以通过其区块头中包含的其父区块的散列值来找到其前一个区块(父区块)。换句话说,每个区块的区块头中都包含它的父区块的散列值。这样环环相扣把每个区块链接到各自父区块的散列值序列就是一条可以一直追溯到第一个区块(创世区块)的链条。
尽管一个区块只有一个父区块,但它可以暂时拥有多个子区块。每个子区块都将指向同一父区块,并且在“父区块散列值”字段中具有相同的(父区块)散列值。在区块链“分叉”期间出现了多个孩子,这是一种临时情况,当不同的区块几乎同时被不同的矿工发现时会发生这种情况。最终,只有一个子区块成为区块链的一部分,“分叉”问题就解决了。即使一个区块可能有多个子区块,每个区块只能有一个父区块。这是因为一个区块只有一个“父区块散列值”字段可以指向它的唯一父区块。
“父区块散列值”字段储存在区块头里面,因此会影响区块本身的散列值。如果父区块的身份标识发生变化,子区块的身份标识也会跟着变化。当父区块有任何改动时,父区块的散列值会发生变化。这将使子区块的“父区块散列值”字段发生改变,从而将使得子区块的散列值发生改变。而子区块的散列值发生改变将使孙区块的“父区块散列值”字段发生改变,因此又会改变孙区块的散列值,以此类推。这种级联效应可以确保一旦一个区块在其之后有许多后代,它就不能在不强制重新计算所有后续区块的情况下进行更改。由于重新计算需要大量的算力(需要耗费大量的能源),长链块的存在使得区块链的纵深历史变得不可篡改,这是比特币安全性的一个关键特征(基于等同于时间的CPU算法保证分布式共识安全性)。
你可以把区块链想象成地质构造中的地质层或冰川岩芯样本。表层可能随着季节变化,甚至在乘积之前被风吹走。但一旦深入几英寸,地质层就变得越来越稳定。到深入几百英尺时,你会看到几百万年来一直没有受到干扰的历史原貌。在区块链中,如果由于分叉导致链重新计算,则可能会修改最近的几个区块。前六个区块就像是几英寸的表土。但一旦深入区块链超过六个区块,区块被修改的可能性就越来越小。100个区块以后,区块链的稳定性非常之高,coinbase交易(包含新开采的比特币的交易)可以被用来花费。几千个区块之后(一个月),区块链已成为确定的历史,在实际情况下完全不可能再被改变。
尽管协议总是允许一条链被一条更长的链取代,所以任何区块被反转的可能性总是存在的,但是这种事件发生的可能性会随着时间流逝而减少,直至永不可能。
区块结构
区块是一种容器型的数据结构,聚合了被记录在公开账簿(区块链)里的交易信息。区块由一个包含元数据的区块头和紧跟其后的构成区块主体的一长串交易组成。区块头为80个字节,而平均每个交易至少为250个字节,平均每个区块包含超过500个交易。因此,一个包含所有交易的完整区块比区块头大1000倍。
下表描述了一个区块的结构。

区块头
区块头包含三组区块元数据。
- 第一组原数据,引用父区块散列值的数据,这组元数据用于将该区块与区块链中前一区块相连接。
- 第二组元数据,即难度、时间戳和随机数,与挖矿竞争相关。
- 第三块元数据是默克尔树根(merkle tree root),一种数据结构,用于有效地汇总块中的所有交易。
下表描述了区块头的结构。

区块标识符:区块头散列值和区块高度
区块主要标识符是它的加密散列值,一个通过对区块头进行二次SHA256散列计算而得到的数字指纹。产生的32字节散列值被称为区块散列值,或更准确地称作“区块头散列值”,因为只有区块头被用于计算这个散列值。
例如,000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f是有史以来创建的第一个比特币区块的散列值。区块散列唯一且明确地标识一个区块,并且可以由任何节点通过简单地对区块头进行散列运算来独立地导出。
请注意,不管是区块在网络上传输时,还是作为区块链的一部分存储在节点的持久性存储中时,区块散列实际上并未包含在区块的数据结构中。相反,区块的散列是当区块从网络被接收时由每个节点计算出来的。区块散列可以作为区块元数据的一部分存储在单独的数据库表中,以便于从磁盘索引和更快地检索区块。
识别区块的第二种方法是根据其在区块链中的位置,称为区块高度(block height)。第一个区块的区块高度为0,就是之前散列值000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f所引用的同一区块。因此可以通过两种方式来标识区块:
- 通过引用区块散列值
- 通过引用区块高度
在第一个区块的“顶部”添加的每个后续区块在区块链中都比前面的区块高出一个区块高度,就像一个堆叠在另一个顶上的箱子一样。2017年1月1日的区块高度约为446000,这意味着在2009年1月创建的第一区块之上堆砌了446000个区块。
与区块散列值不同,区块高度不是唯一标识符。尽管单个区块总是具有特定且不变的区块高度,但反过来并不正确。区块高度并不总是标识单个区块。两个或更多区块可能具有相同的区块高度,争夺区块链中的相同位置。区块高度也不是区块数据结构的一部分;它不存储在区块中。当从比特币网络收到区块时,每个节点都会动态识别区块在区块链中的位置(区块高度)。区块高度也可以作为元数据存储在索引数据库表中以加快检索速度。
区块的区块散列值总能唯一标识一个区块。区块也总有一个特定的区块高度。但是,特定区块高度并不总是能够识别某个特定区块。相反,两个或多个区块可能会在区块链中争夺一个位置。
创世区块
区块链中的第一个区块被称为创世区块,产生于2009年。它是区块链中所有区块的共同祖先,这意味着如果你从任何区块开始并按时序回溯区块链的话,最终都将到达创世区块。
每个节点总是以至少一个区块的区块链开始,因为这个区块是在比特币客户端软件中静态编码的,它不能被改变。每个节点总是“知道”起始区块的散列值和结构,它创建的固定时间,甚至是其中的单个交易。因此,每个节点都有区块链的起点,这是一个安全的“根”,从中可以构建可信的区块链。
请参阅chainparams.cpp(http://bit.ly/1x6rcwP)中在Bitcoin Core客户端内静态编码的创世区块。
创世区块的散列值为:000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
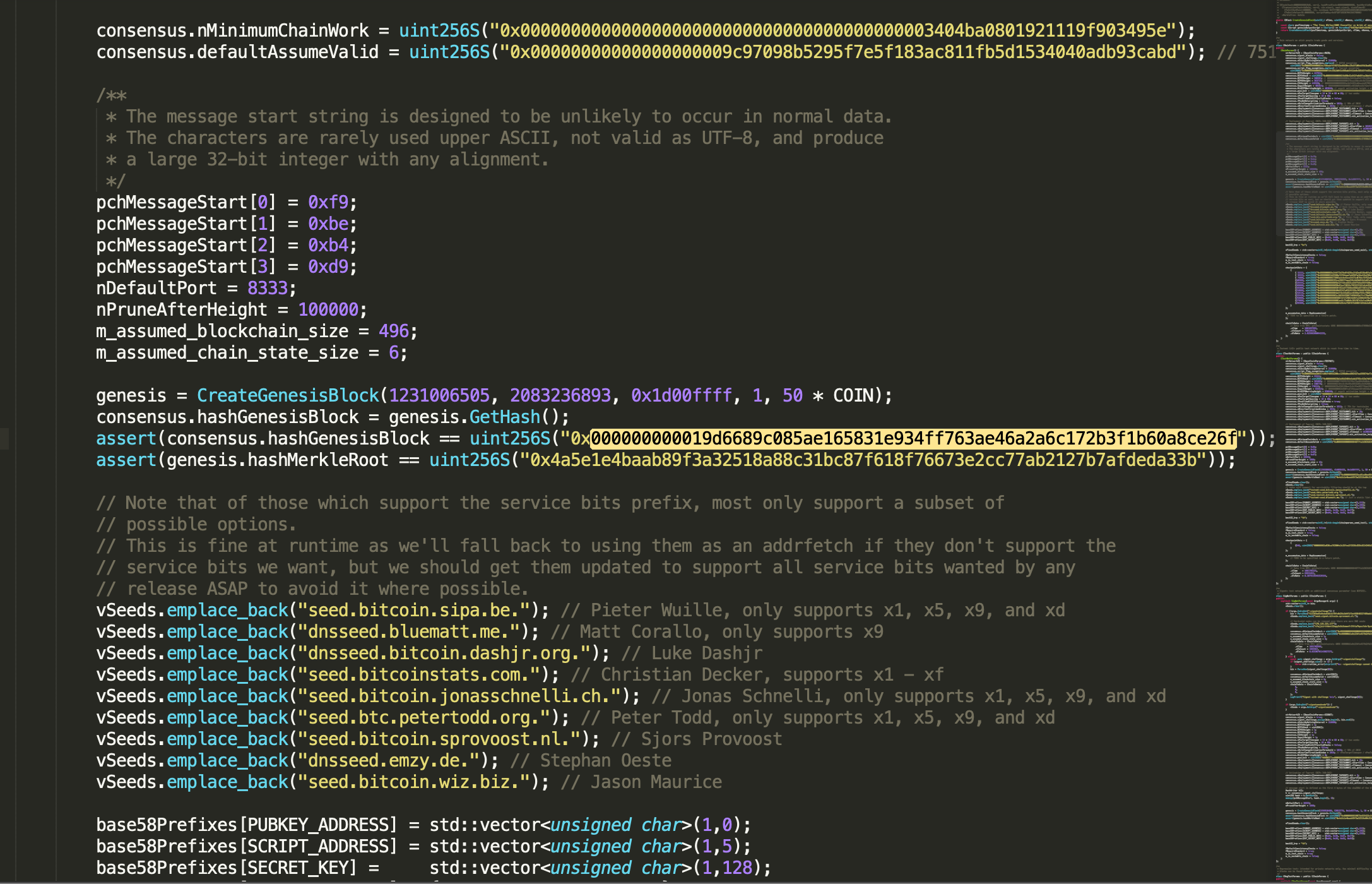
你可以在任何区块链浏览器网站(例如blockchain.info)中搜索该区块散列值,你将找到一个描述此区块内容的页面,其中包含该散列值的链接:
https://blockchain.info/block/000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f https://blockexplorer.com/block/000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
在命令行上使用Bitcoin Core参考客户端:
./bitcoin-cli getblock 000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f
{
"hash": "000000000019d6689c085ae165831e934ff763ae46a2a6c172b3f1b60a8ce26f",
"confirmations": 235496,
"height": 0,
"version": 1,
"versionHex": "00000001",
"merkleroot": "4a5e1e4baab89f3a32518a88c31bc87f618f76673e2cc77ab2127b7afdeda33b",
"time": 1231006505,
"mediantime": 1231006505,
"nonce": 2083236893,
"bits": "1d00ffff",
"difficulty": 1,
"chainwork": "0000000000000000000000000000000000000000000000000000000100010001",
"nTx": 1,
"nextblockhash": "00000000839a8e6886ab5951d76f411475428afc90947ee320161bbf18eb6048",
"strippedsize": 285,
"size": 285,
"weight": 1140,
"tx": [
"4a5e1e4baab89f3a32518a88c31bc87f618f76673e2cc77ab2127b7afdeda33b"
]
}创世区块包含一个隐藏的信息。在其Coinbase交易的输入中包含这样一句话“TheTimes 03/Jan/2009 Chancellor on brink of second bailout for banks.”这句话是《泰晤士报》当天的文章标题,引用这句话,既是对该区块产生时间的说明,也可视为半开玩笑地提醒人们一个独立的货币体系的重要性,同时告诉人们随着比特币的发展,一场前所未有的世界性货币危机将要发生。该消息是由比特币的创造者中本聪嵌入创世区块中的。
链接区块链中的区块
比特币的全节点在本地保存了区块链从创世区块起的完整副本。区块链的本地副本会随着新区块的发现并用于扩展区块链而不断更新。当一个节点从网络接收传入的区块时,它会验证这些区块,然后将它们链接到现有的区块链。为建立一个连接,一个节点将检查传入的区块头并寻找该区块的“父区块散列值”。
例如,假设一个节点在区块链的本地副本中有277,314个区块。该节点知道最后一个区块为第277,314个区块,这个区块的区块头散列值为:
00000000000000027e7ba6fe7bad39faf3b5a83daed765f05f7d1b71a1632249
然后该比特币节点从网络上接收到一个新的区块,该区块描述如下:
{
"size" : 43560,
"version" : 2,
"previousblockhash" : "00000000000000027e7ba6fe7bad39faf3b5a83daed765f05f7d1b71a1632249",
"merkleroot" : "5e049f4030e0ab2debb92378f53c0a6e09548aea083f3ab25e1d94ea1155e29d",
"time" : 1388185038,
"difficulty" : 1180923195.25802612,
"nonce" : 4215469401,
"tx" : [
"257e7497fb8bc68421eb2c7b699dbab234831600e7352f0d9e6522c7cf3f6c77",
#[... many more transactions omitted ...]
"05cfd38f6ae6aa83674cc99e4d75a1458c165b7ab84725eda41d018a09176634"
]
}看一个新的区块,节点会在previousblockhash(父区块哈希值)字段里找出包含其父区块的哈希值。这是节点已知的哈希值,也就是第277314个区块的哈希值。这个新区块是这个链条里的最后一个区块的子区块,因此扩展了现有的区块链。节点将新的区块添加到链的末尾,使区块链增加一个新的区块高度277315。
下图显示了通过“父区块哈希值”字段连接三个区块的链。
默克尔树
比特币区块链中的每个区块都包含该区块中所有的交易,以默克尔树(merkle tree)来表示。
默克尔树,也称为哈希二叉树,是一种用于有效地汇总和验证大型数据集完整性的数据结构。默克尔树是包含密码哈希的二叉树。术语“树”在计算机科学中被用来描述分支数据结构,但是这些树通常是颠倒显示的,“根”在顶上,“叶子”在底下。
在比特币中使用默克尔树来汇总区块中的所有交易,为整个交易集提供全面的数字指纹,提供非常高效的流程来验证交易是否包含在区块中。生成一棵完整的默克尔树需要递归地将一对节点进行哈希,并将新生成的哈希节点插入默克尔树中,直到只剩一个哈希节点,该节点就是默克尔树的根。在比特币的默克尔树中两次使用到了SHA256算法,因此其加密哈希算法也被称为double-SHA256。
当N个数据元素经过加密后插入默克尔树时,你最多计算2*log2(N)次就能检查出任意某数据元素是否在该树中,这使得该数据结构非常高效。
默克尔树是自下而上构建的。在如下的例子中,我们从A、B、C、D四个构成默克尔树树叶的交易开始,如下图所示。所有的交易并不存储在默克尔树上,而是将数据进行哈希运算,然后将哈希值存储到相应的叶子节点上。这些叶子节点分别是
- HA
- HB
- HC
- HD
HA = SHA256(SHA256(Transaction A))
将相邻一对叶子节点的哈希值串联在一起进行哈希运算,这对叶子节点随后被归纳为父节点。例如,为了创建父节点HAB,子节点A和子节点B的两个32字节的哈希值将被串联成64字节的字符串。随后将字符串进行两次哈希运算来产生父节点的哈希值:
HAB= SHA256(SHA256(HA+ HB))
继续类似的操作直到只剩下顶部的一个节点,即默克尔树根。产生的32字节哈希值存储在区块头,同时归纳了四个交易的所有数据。
下图展示了如何通过成对节点的哈希值计算默克尔树的树根。
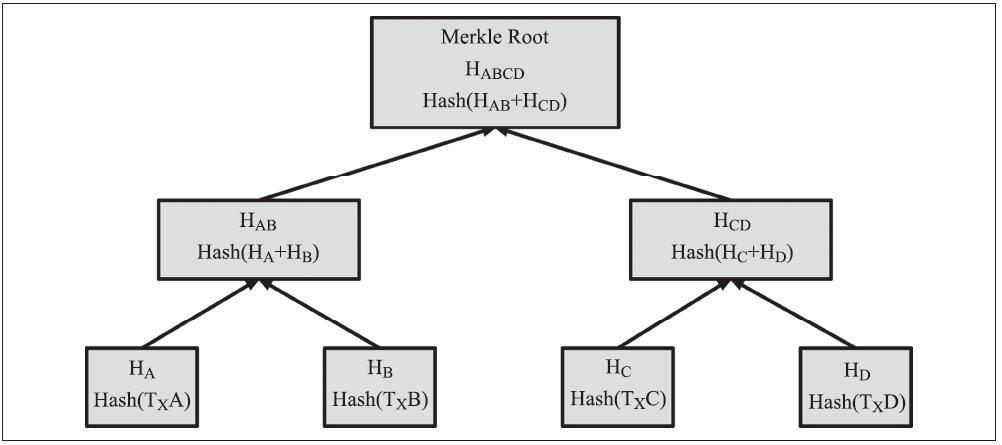
因为默克尔树是二叉树,所以它需要偶数个叶子节点。如果仅有奇数个交易需要归纳,那最后的交易就会被复制一份以构成偶数个叶子节点,这种偶数个叶子节点的树也被称为平衡树。如下图所示,C节点被复制了一份。
由四个交易构造树的方法可以推广到构造任意大小的树。在比特币中,通常一个区块中有几百到几千个交易,这些交易都会采用同样的方法来归纳,产生一个仅32字节的数据作为默克尔树的根。在下图中,你会看见一个从16个交易形成的树。需注意的是,尽管图中的根看上去比所有叶子节点都大,但其实它们都是32字节,大小相同。无论区块中有一个交易或者有成千上万个交易,默克尔树的根总会把所有交易归纳为32字节。
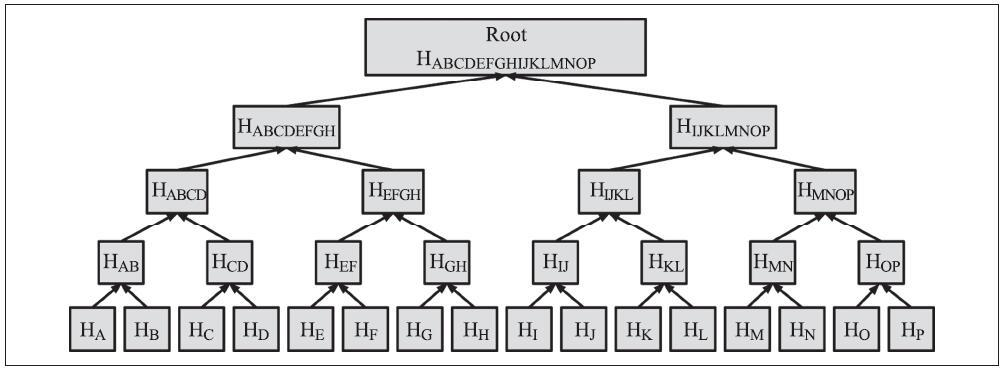
为了证明一个块中包含了一个特定的交易,一个节点只要计算log2(N)32字节的哈希值,形成一条从特定交易到树根的认证路径或者默克尔路径。随着交易数量的增加,这样的计算量就显得尤为重要,因为相对于交易数量的增长,以基数为2的交易数量的对数的增长速度会慢得多。这使比特币节点能够高效地产生10或者12个哈希值(320~384字节)的路径,来证明在一个很大字节数的区块中上千笔交易中的具体某一笔交易的存在。
在下图中,一个节点可以通过生成一条仅有4个32字节哈希值长度(总共128字节)的默克尔路径来证明区块中存在某一笔交易K。
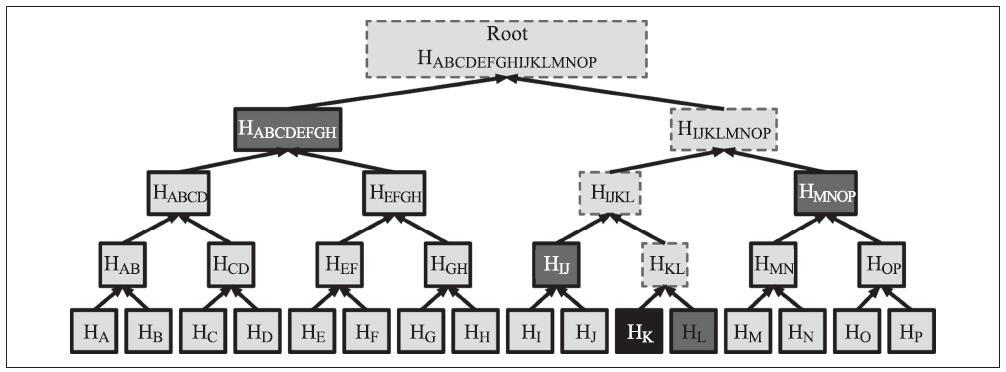
该路径有4个哈希值(在上图中由灰色背景标注)
- HL
- HIJ
- HMNOP
- HABCDEFGH
组成,通过这4个哈希值产生的认证路径,任何节点都可以通过计算另外四对哈希值
- HKL
- HIJKL
- HIJKLMNOP
- 默克尔树根(图中虚线标注部分)
来证明HK(图中底部的黑色背景数据元素)包含在默克尔根中。
默克尔树的高效率随着交易规模的增加而变得明显。下表展示了为了证明区块中存在某交易而所需转化为默克尔路径的数据量。

从表中可以看出,当区块大小由16笔交易(4KB)快速增加到65,535笔交易(16MB)时,证明交易存在的默克尔路径长度增长极其缓慢,仅仅从128字节增长到512字节。有了默克尔树,一个节点能够仅下载区块头(80字节/区块),然后通过从一个全节点回溯一条小的默克尔路径就能认证一笔交易的存在,而不需要存储或者传输大量区块链中大多数的内容,那些也许有几个GB的大小。
这种不需要维护一条完整的区块链的节点,被称作简单支付验证(SPV)节点,它通过默克尔路径去验证交易的存在,而不需要下载整个区块。
默克尔树和简单支付验证
默克尔树被SPV节点广泛使用。SPV节点不保存所有交易也不下载整个区块,仅保存区块头。它们使用认证路径或者默克尔路径来验证交易存在于区块中,而不必下载区块中所有的交易。
例如,一个SPV节点对它钱包中某个比特币地址即将收到的付款感兴趣。该节点会在节点间的通信链接上建立起bloom过滤器,限制只接受含有目标比特币地址的交易。当同伴探测到某交易符合bloom过滤器要求,它将以merkleblock消息的形式发送该区块。merkleblock消息包含区块头以及将感兴趣的交易链接到区块中的根的默克尔路径。SPV节点能够使用该路径找到与该交易相关的区块,进而验证对应区块中该交易的存在。
SPV节点同时也使用区块头去关联区块和区块链中的其余区块。这两种关联(交易与区块、区块和区块链)可以证明交易存在于区块链。总而言之,SPV节点会收到少于1KB的有关区块头和默克尔路径的数据,其数据量约为一个完整区块(目前大约有1MB)的千分之一。
比特币的测试链
你可能会惊讶地发现,有不止一个比特币区块链的存在。2009年1月3日由中本聪Satoshi Nakamoto创建的“主要”的比特币区块链,即含有创世区块的网络,称为主干网。另外还有其他用于测试的比特币区块链:现存的有testnet、segnet和regtest。下文将依次介绍。
(1)testnet——比特币的试验场
testnet是测试区块链、网络和货币的总称。testnet是一个功能齐全的在线P2P网络,包括钱包,测试比特币(testnet币),挖矿以及类似主干网的所有其他功能。实际上它和主干网只有两个区别:testnet币是毫无价值的,挖掘难度足够低,任何人都可以相对容易地挖到testnet币。
任何打算在比特币主干网上用于生产运行的软件开发都应该首先在testnet上用测试币进行测试。这样可以保护开发人员免受由于软件错误而导致的金钱损失,也可以保护网络免受由于软件错误导致的异常行为影响。
然而,保持测试币的无价值和易挖掘并不容易。尽管有来自开发者的呼吁,但还是有人使用先进的挖矿设备(GPU和ASIC)在testnet上挖矿。这就增加了挖矿难度,使得拿CPU来挖矿不现实,导致获取测试币非常困难,以至于人们开始赋予其一定价值,所以测试币并不是毫无价值的。作为结果,testnet需要时不时地被废弃重来,重新从创始区块启动,重新进行难度设置。
目前的testnet被称为testnet3,是testnet的第三次迭代,于2011年2月重启,重置了之前的testnet网络的难度。
请记住,testnet3是一个大区块链,在2017年年初其大小超过20GB。完全同步需要一天左右的时间,并占用你的计算机资源。它虽然不像主干网这么重,但也不是“轻量级”的。运行testnet节点的一个好方法就是将其运行为一个专用的虚拟机镜像(例如,VirtualBox、Docker、Cloud Server等)。
Bitcoin Core像几乎所有其他比特币软件一样,完全支持在testnet网络运行而不是只能在主干网上运行,还允许你进行测试币挖矿,并运行一个testnet全节点。
如果要在testnet上启动Bitcoin Core,而不是在主干网启动,你需要使用testnet开关:
./bitcoind -testnet -daemon
在日志中,你应该会看到,bitcoind正在默认bitcoind目录的testnet3子目录中构建一个新的区块链:
bitcoind: Using data directory /home/username/.bitcoin/testnet3
要连接bitcoind,可以使用bitcoin-cli命令行工具,但是需要切换到testnet模式:
./bitcoin-cli -testnet getinfo
{ "version": 130200, "protocolversion": 70015, "walletversion": 130000, "balance": 0.00000000, "blocks": 416, "timeoffset": 0, "connections": 3, "proxy": "", "difficulty": 1, "testnet": true, "keypoololdest": 1484801486,
"keypoolsize": 100, "paytxfee": 0.00000000, "relayfee": 0.00001000, "errors": ""}
你还可以使用getblockchaininfo命令来确认testnet3区块链的详细信息和同步进度:
./bitcoin-cli -testnet getblockchaininfo
{
"chain": "test",
"blocks": 0,
"headers": 0,
"bestblockhash": "000000000933ea01ad0ee984209779baaec3ced90fa3f408719526f8d77f4943",
"difficulty": 1,
"time": 1296688602,
"mediantime": 1296688602,
"verificationprogress": 1.555441715009351e-08,
"initialblockdownload": true,
"chainwork": "0000000000000000000000000000000000000000000000000000000100010001",
"size_on_disk": 293,
"pruned": false,
"warnings": "This is a pre-release test build - use at your own risk - do not use for mining or merchant applications"
}你也可以运行使用其他语言和框架实现的全节点来在testnet3上实验和学习,例如btcd(用Go编写)和bcoin(用JavaScript编写)。
在2017年年初,testnet3支持主网的所有功能,也包括在主干网络上尚未激活的隔离见证(Segregated Witness)。因此,testnet3也可用于测试隔离见证功能。
(2)segnet——隔离见证测试网
在2016年,启动了一个特殊用途的测试网络,以帮助开发和测试隔离见证(Segregated Witness)(也称为segwit)。该测试区块链称为segnet,可以通过运行Bitcoin Core的特殊版本(分支)来连接。
自从segwit添加到testnet3中,就不再需要使用segnet来测试隔离见证功能。
(3)regtest——本地区块链
regtest代表“回归测试”(Regression Testing),是一种比特币核心功能,允许你创建本地区块链以进行测试。与testnet3(它是一个公共和共享的测试区块链)不同,regtest区块链旨在作为本地测试的封闭系统运行。你从头开始启动regtest区块链,创建一个本地的创世区块。你可以将其他节点添加到网络中,或者使用单个节点运行它来测试Bitcoin Core软件。
要在regtest模式下启动Bitcoin Core,可以使用regtest标识:
./bitcoind -regtest -daemon
就像使用testnet一样,Bitcoin Core将在bitcoind默认目录的regtest子目录下初始化一个新的区块链:
bitcoind: Using data directory /home/username/.bitcoin/regtest
要使用命令行工具,还需要指定regtest标识。我们来试试用getblockchaininfo命令来检查regtest区块链:
./bitcoin-cli -regtest getblockchaininfo
{
"chain": "regtest",
"blocks": 0,
"headers": 0,
"bestblockhash": "0f9188f13cb7b2c71f2a335e3a4fc328bf5beb436012afca590b1a11466e2206",
"difficulty": 4.656542373906925e-10,
"time": 1296688602,
"mediantime": 1296688602,
"verificationprogress": 1,
"initialblockdownload": true,
"chainwork": "0000000000000000000000000000000000000000000000000000000000000002",
"size_on_disk": 293,
"pruned": false,
"warnings": "This is a pre-release test build - use at your own risk - do not use for mining or merchant applications"
}你可以看到,还没有任何区块。我们开始挖一些(500个区块),并赚取奖励:
./bitcoin-cli -regtest generate 500
使用测试区块链进行开发
比特币的各种区块链(regtest、segnet、testnet3、mainnet)为比特币开发提供了一系列测试环境。无论你是为Bitcoin Core开发,还是为另一个完整节点共识客户端开发(如一个应用程序,如钱包、交换所、电子商务网站、甚至开发新颖的智能合约和复杂的脚本)都可以使用测试区块链。
你可以使用测试区块链建立开发管道。在你开发它的时候在本地测试你的代码。一旦准备好在公共网络上尝试它,切换到testnet将代码暴露给更具动态性的环境,并提供更多不同的代码和应用程序。最后,一旦你确信自己的代码能够按预期工作,请切换到mainnet以在生产环境中进行部署。当你进行更改、改进、错误修复等操作时,请重新启动管道,首先在regtest,然后在testnet上,最后在生产环境中部署每个变更。
七、挖矿和共识
简介
“挖矿”这个词有点误导。一般意义的挖矿类似贵金属的提取,于是人们将更多的注意力集中到创造每个区块后获得的奖励。虽然挖矿行为会被这种奖励所激励,但挖矿的主要目的不是这个奖励或者产生的新币。挖矿过程中会创建新币,但是挖矿不是最终目的,更多的是一种激励手段。
挖矿是一种去中心化的交易清算机制,通过这种机制,交易得到验证和清算。挖矿是使得比特币与众不同的发明,它实现去中心化的安全机制,是P2P数字货币的基础。
挖矿确保了比特币系统安全,并且在没有中央权力机构的情况下实现了全网络范围的共识。新币发行和交易费的奖励是将矿工的行动与网络安全保持一致的激励方案,并同时实现了货币发行。
挖矿的目的不是创造新的比特币,这是激励机制,能够实现去中心化的安全。
矿工们验证每笔新的交易并把它们记录在总账簿上。平均每10分钟就会有一个新的区块被“挖掘”出来,每个区块里包含着从上一个区块产生到目前这段时间内发生的所有交易,这些交易被依次添加到区块链中。我们把包含在区块内并且被添加到区块链上的交易称为“确认”(confirmed)交易,交易经过“确认”之后,新的拥有者才能够花费他在交易中得到的比特币。
挖矿保证了系统的安全,矿工们在挖矿过程中会得到两种类型的奖励:
- 创建新区块的新币奖励
- 该区块中所有交易的交易费
为了得到这些奖励,矿工们争相完成一种基于加密散列算法的数学难题。这些被称为“工作量证明”的难题的答案会放在新区块中,作为矿工付出大量计算工作的证据。在工作量证明的竞争中,获胜者会得到奖励并且拥有在区块链上的记账权,这是比特币安全模型的基础。
挖矿之所以被称为挖矿,是因为它的奖励机制被设计为收益递减模式,这类似于贵重金属的挖矿过程。比特币的货币是通过挖矿发行的,类似于中央银行通过印刷银行纸币来发行货币。矿工通过创造一个新区块得到的比特币数量大约每四年(或准确说是每210000个块)减少一半。开始时间为2009年1月,每个区块奖励50个比特币,然后到2012年11月减半为每个区块奖励25个比特币。之后在2016年7月再次减半为每个新区块奖励12.5个比特币。基于这个公式,比特币挖矿奖励以指数方式递减,直到2140年。届时所有的比特币(20,999,999,980)全部发行完毕。换句话说在2140年之后,不会再有新的比特币产生。
矿工们同时也会获取交易费。每笔交易都可能包含一笔交易费,交易费是每笔交易记录的输入和输出的差额。在挖矿过程中成功“挖出”新区块的矿工可以得到该区块中包含的所有交易“小费”。目前,这笔费用占矿工收入的0.5%或更少,大部分收益仍来自挖矿所得的比特币奖励。然而随着挖矿奖励的递减,以及每个区块中包含的交易数量的增加,交易费在矿工收益中所占的比重将会逐渐增加。在2140年之后,矿工的所有收益都将由交易费构成。
在本章中,我们先来审视比特币的货币发行机制,然后再来了解挖矿最重要的功能:支撑比特币安全的去中心化的共识机制。为了了解挖矿和共识,我们将跟随Alice的交易,以及上海的矿工Jing如何利用挖矿设备收到Alice的交易并将其加入区块。然后,我们将继续跟踪区块被挖出后加入区块链,并通过共识被比特币网络接收的全过程。
比特币经济学和货币创造
通过一个个新区块的产生,比特币以一个确定的但不断减慢的速率被“铸造”出来。大约每十分钟产生一个新区块,每一个新区块都伴随着一定数量从无到有的全新比特币。每开采210,000个块,大约耗时4年,货币发行速率会降低50%。在比特币运行的第一个四年中,每个区块创造出50个新比特币。
2012年11月,比特币的新发行速度降低到每区块25个比特币。2016年7月,降低到12.5比特币/区块。2020年的某个时候,也就是区块630,000,它将再次下降至6.25比特币。新币的发行速度会以指数级进行32次“等分”,直到第6,720,000块(大约在2137年开采),达到比特币的最小货币单位1 satoshi(聪)。最终,在经过693万个区块之后,所有的共2,099,999,997,690,000聪比特币将全部发行完毕。也就是说,到2140年左右,会存在接近2,100万比特币。在那之后,新的区块不再包含比特币奖励,矿工的收益全部来自交易费。
下图展示了在发行速度不断降低的情况下,比特币总流通量与时间的关系。
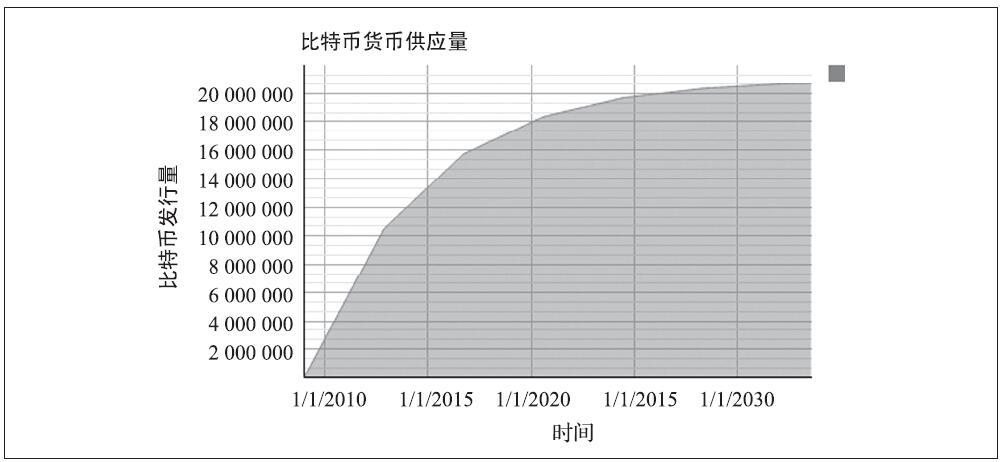
比特币挖矿奖励的上限是挖矿允许发行的最大数量。在实际情况中,矿工可能故意挖出一个低于全额奖励的区块。已经有类似的区块被挖出来了,未来可能会有更多这样的区块被挖出来,而这会导致货币总发行量的减少。
在下例的代码展示中,我们计算了比特币的总发行量。
# -*- coding: utf-8 -*-
if __name__ == '__main__':
# Original block reward for miners was 50 BTC = 50 0000 0000 Satoshis
start_block_reward = 50 * 10 ** 8
# 210000 is around every 4 years with a 10 minute block interval
reward_interval = 210000
def max_money():
current_reward = start_block_reward
total = 0
while current_reward > 0:
total += reward_interval * current_reward
current_reward /= 2
return total
print("Total BTC to ever be created:", max_money(), "Satoshis")
总量有限并且发行速率递减创造了一种抗通胀的货币供应模式。法币可被中央银行无限制地印刷出来,而比特币永远不会因超额印发而出现通胀。
去中心化共识
我们可以将区块链看作一本记录所有交易的公开总账簿(列表),比特币网络中的每个参与者都把它看作一本证明所有权的权威记录。
但在不考虑相信任何人的情况下,比特币网络中的所有参与者如何达成对所有权的共识呢?所有的传统支付系统都依赖于一个中心认证机构,依靠中心机构提供的清算服务来验证并处理所有的交易。比特币没有中心机构,几乎所有的完整节点都有一份公共总账的备份,这份总账可以被视为权威记录。区块链并不是由一个中心机构创造的,它是由比特币网络中各个独立的节点组成的。换句话说比特币网络中的所有节点,依靠着节点间的不稳定的网络连接所传输的信息,最终达成了共识并维护同一本公共总账。
中本聪的主要发明就是这种去中心化的自发共识(emergent consensus)机制。这种自发是指共识没有明确的完成点,因为共识达成时,没有明确的选举和固定时刻。换句话说,共识是数以千计的独立节点遵守了简单的规则通过异步交互自发形成的产物。所有的比特币属性,包括货币、交易、支付以及不依靠中心机构和信任的安全模型等都依赖于这个发明。
比特币的去中心化共识由所有网络节点的4种独立过程相互作用而产生:
- 每个全节点依据规范清单对每个交易进行独立验证。
- 通过完成工作量证明算法的验算,挖矿节点将交易记录独立打包进新区块。
- 每个节点独立对新区块进行校验并组装进区块链。
- 每个节点对区块链进行独立选择,在工作量证明机制下选择累计工作量最大的区块链。
在接下来的几节中,我们将审视这些过程,了解它们之间如何相互作用并达成全网的自发共识,从而使任意节点可以组装出它自己的权威、可信、公开的总账副本。
交易的独立校验
在前面的章节中,我们讨论了钱包软件如何通过收集UTXO、提供正确的解锁脚本、构造一个新的支出(支付)给接收者这一系列的动作来创建交易。产生的交易随后将被发送到比特币网络邻近的节点,从而使得该交易能够在整个比特币网络中传播。
然而,在交易传递到邻近的节点前,每一个收到交易的比特币节点会先验证该交易。这将确保只有有效的交易才会在网络中传播,而无效的交易将会在第一个收到它的节点处被废弃。
每一个节点在校验每一笔交易时,都需要对照一个长长的规范清单:
- 交易的语法和数据结构必须正确。
- 输入与输出列表都不能为空。
- 交易的字节大小要小于MAX_BLOCK_SIZE的值。
- 每一个输出值以及总量,必须在规定值的范围内(小于2100万个币,大于粉尘阈值。
- 散列等于0,或者N等于-1的输入是非法的(创币交易不应当被传递)。
- nLockTime是小于或等于INT_MAX的,或者nLocktime和nSequence的值满足MedianTimePast。
- 交易的字节大小是大于或等于100的。
- 交易中的签名数量(SIGOPS)应小于签名操作数量上限。
- 解锁脚本(scriptSig)只能够将数字压入栈中,并且锁定脚本(scriptPubkey)必须要符合isStandard的格式(该格式将会拒绝非标准交易)。
- 与此交易匹配的交易必须在主链的区块或者池中存在。
- 对于每一个输入,如果引用的输出存在于池中任何别的交易中,该交易将被拒绝。
- 对于每一个输入,在主链和交易池中寻找其引用的输出交易。如果输出不存在,该交易将成为一个孤立的交易。如果与其匹配的交易还没有出现在池中,那么将被加入到孤立交易池中。
- 对于每一个输入,如果引用的输出交易是创币输出,该输入必须至少获得COINBASE_MATURITY(100)个确认。
- 对于每一个输入,引用的输出是必须存在的,并且没有被花费。
- 使用引用的输出交易获得输入值,并检查每一个输入值和总值是否在规定值的范围内(小于2100万个币,大于0)。
- 如果输入值的总和小于输出值的总和,交易将被中止。
- 如果交易费用太低(minRelayTxFee)以至于无法进入空的区块,交易将被拒绝。
- 每一个输入的解锁脚本必须依据相应输出的锁定脚本来验证。
这些条件能够在比特币核心客户端下的AcceptToMemoryPool、CheckTransaction和CheckInputs函数中获得更详细的阐述。
请注意,有时候为了处理新型拒绝服务攻击,或者有时候为了交易类型多样化,这些条件会随着时间发生变化。
在收到交易后,每一个节点都会在全网广播前先对这些交易进行独立校验,并以接收时的相应顺序,为这些有效的新交易(还未确认)建立一个池,这个池可以叫作交易池,也称为内存池。
挖矿节点
在比特币网络中,一些节点被称为专业节点“矿工”,运行这些节点的机器被称为矿机,矿机是专门设计用于挖比特币的计算机硬件系统。
与完整节点不同,一些矿工是在没有完整节点的条件下进行挖矿的,这些节点在比特币网络中接收和传播未确认交易,也能够把这些交易打包进入一个新区块。
同其他节点一样,矿工的节点时刻监听着传播到比特币网络的新区块。而这些新加入的区块对挖矿节点有着特殊的意义。矿工间的竞争以新区块的传播而结束,如同宣布谁是最后的赢家。对于矿工们来说,收到一个新区块进行验证意味着别人已经赢了,而自己则输了这场竞争。然而,一轮竞争的结束也代表着下一轮竞争的开始。新区块并不仅仅是象征着竞赛结束的方格旗,它也是下一个区块竞赛的发令枪。
打包交易至区块
验证交易后,比特币节点会将这些交易添加到自己的内存池中。内存池也称作交易池,用来暂存尚未被加入到区块的交易记录。与其他节点一样,节点会收集、验证并传递新的交易,同时,节点会把这些交易整合到一个候选区块中。
让我们继续跟进,看下Alice从Bob咖啡店购买咖啡时产生的那个区块。Alice的交易在区块277,316。为了演示本章中提到的概念,我们假设这个区块是由Jing的挖矿系统挖出的,并且继续跟进Alice的这个已经被加入到新区块的交易。
Jing的挖矿节点维护了一个区块链的本地副本。当Alice买咖啡的时候,Jing节点的区块链已经收集到了区块277,314,并继续监听着网络上的交易,在尝试挖掘新区块的同时,也监听着由其他节点发现的区块。当Jing的节点在挖矿时,它从比特币网络收到了区块277,315。这个区块的到来标志着产出区块277,315竞赛的终结,与此同时也是产出区块277,316竞赛的开始。
在上一个10分钟内,当Jing的节点在寻找区块277,315的解的同时,它也在为下一个区块收集交易记录。目前它已经收集到了几百笔交易记录,并将它们放进了内存池。直到接收并验证区块277,315后,Jing的节点会检查内存池中的全部交易,并移除已经在区块277,315中出现过的交易记录,确保任何留在内存池中的交易都是未确认的,都是需要被记录到新区块中的。
Jing的节点立刻构建一个新的空区块,作为区块277,316的候选区块。此区块被称作候选区块是因为它还没有包含有效的工作量证明,不是一个有效的区块。只有在矿工成功找到一个工作量证明解之后,这个区块才生效。
现在,Jing的节点从内存池中整合到了全部的交易,新的候选区块包含了418笔交易,总的矿工费为0.09094928个比特币。你可以通过比特币核心客户端命令行来查看这个区块,如下例所示。
$ bitcoin-cli getblockhash 277316
0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
$ bitcoin-cli getblock 0000000000000001b6b9a13b095e96db41c4a928b97ef2d9\44a9b31b2cc7bdc4
{
"hash" : "0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4",
"confirmations" : 35561,
"size" : 218629,
"height" : 277316,
"version" : 2,
"merkleroot" :"c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e",
"tx" : [
"d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f",
"b268b45c59b39d759614757718b9918caf0ba9d97c56f3b91956ff877c503fbe",
... 417 more transactions...
],
"time" : 1388185914,
"nonce" : 924591752,
"bits" : "1903a30c",
"difficulty" : 1180923195.25802612,
"chainwork" :"000000000000000000000000000000000000000000000934695e92aaf53afa1a",
"previousblockhash" :"0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569"
}构造区块头
为了构造区块头,挖矿节点需要填充六个字段,如下表所示。

在区块277,316被挖出的时候,区块结构中用来表示版本号的字段值为2,长度为4字节,以小端格式编码值为0x02000000。
接着,挖矿节点需要填充“前区块散列”(prevhash)。在本例中,这个值为Jing的节点从网络上接收到的区块277,315的区块头散列值,它是候选区块277,316的父区块。区块277,315的区块头散列值为:
0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569
通过选择特定区块作为候选区块头中的父区块散列值字段来源,Jing贡献他的挖矿算力,扩展了区块链。从本质上讲,这是用他的挖矿算力为最长的有效链进行的“投票”。
为了向区块头填充默克尔树根字段,要将全部的交易组成一个默克尔树。创币交易作为区块中的首个交易,然后将余下的418笔交易添至其后,这样区块中的交易一共有419笔。之前我们已经见到过“默克尔树”,树中必须有偶数个叶子节点,所以需要复制最后一个交易作为第420个叶子节点,每个叶子节点的内容是对应交易的散列值。这些交易的散列值成对地、逐层地合并,直到最终合并成一个根节点。默克尔树的根节点将全部交易数据摘要成一个32字节的值,上例中默克尔树根的值如下:
c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e
Jing的挖矿节点会继续添加一个4字节的时间戳,以Unix纪元时间编码,即自1970年1月1日0点UTC/GMT到当下总共流逝的秒数。本例中的1388185914对应的时间是2013年12月27日,星期五,23:11:54,UTC/GMT。
接下来,Jing的节点需要填充“目标值”字段,为了使得该区块有效,这个字段定义了所需满足的工作量证明的难度。目标值在区块中以“尾数-指数”的格式编码并存储,这种格式称作目标位(target bits)。这种编码的首字节表示指数,后面的3字节表示尾数(系数)。以区块277316为例,目标位的值为0x1903a30c,0x19是十六进制格式的指数,后半部0x03a30c是系数。
最后一个字段是随机数,初始值为0。
完成区块头的全部字段填充后,挖矿就可以开始了。挖矿的目标是找到一个使区块头散列值小于难度目标的随机数。挖矿节点通常需要尝试数十亿甚至数万亿个不同的随机数取值,才会找到一个满足条件的随机数值。
挖掘区块
既然Jing的节点已经构建了一个候选区块,那么就轮到Jing的矿机对这个区块进行“挖掘”,对工作量证明算法求解以使这个区块有效。事实上,大部分节点都会根据自己接受到的交易创造自己的候选区块,然后展开挖掘,直到某个节点挖掘成功并广播出去,整个区块链网络才能重新达成一个新的共识。
简单来说,挖矿就是不断修改区块头中的参数,并计算区块头的散列值,直到其散列值与目标难度相匹配的过程。散列函数的结果无法提前得知,也没有能得到一个特定散列值的模式。散列函数的这个特性意味着:得到散列值的唯一方法是不断地尝试,每次随机修改输入,直到出现适当的散列值。
#!/usr/bin/env python
# example of proof-of-work algorithm
import hashlib
import time
try:
long # Python 2
xrange
except NameError:
long = int # Python 3
xrange = range
max_nonce = 2 ** 32 # 4 billion
def proof_of_work(header, difficulty_bits):
# calculate the difficulty target
target = 2 ** (256 - difficulty_bits)
for nonce in xrange(max_nonce):
hash_result = hashlib.sha256((str(header) + str(nonce)).encode()).hexdigest()
# check if this is a valid result, equal to or below the target
if long(hash_result, 16) <= target:
print("Success with nonce %d" % nonce)
print("Hash is %s" % hash_result)
return (hash_result, nonce)
print("Failed after %d (max_nonce) tries" % nonce)
return nonce
if __name__ == '__main__':
nonce = 0
hash_result = ''
# difficulty from 0 to 31 bits
for difficulty_bits in xrange(32):
difficulty = 2 ** difficulty_bits
print("Difficulty: %ld (%d bits)" % (difficulty, difficulty_bits))
print("Starting search...")
# checkpoint the current time
start_time = time.time()
# make a new block which includes the hash from the previous block
# we fake a block of transactions - just a string
new_block = 'test block with transactions' + hash_result
# find a valid nonce for the new block
(hash_result, nonce) = proof_of_work(new_block, difficulty_bits)
# checkpoint how long it took to find a result
end_time = time.time()
elapsed_time = end_time - start_time
print("Elapsed Time: %.4f seconds" % elapsed_time)
if elapsed_time > 0:
# estimate the hashes per second
hash_power = float(long(nonce) / elapsed_time)
print("Hashing Power: %ld hashes per second" % hash_power)你可以看出,随着难度位一位一位地增加,找到正确结果的时间会呈指数级增长。如果你考虑整个256位数字空间,每次要求多一个0,你就把散列查找空间缩减了一半。
zhenghan@zhenghans-MacBook-Pro code % python3 proof-of-work-example.py Difficulty: 1 (0 bits) Starting search... Success with nonce 0 Hash is ff8253ed10b5f719d52a709a66af8cd5e2054f702e675af4ca0cae70f0988634 Elapsed Time: 0.0001 seconds Hashing Power: 0 hashes per second Difficulty: 2 (1 bits) Starting search... Success with nonce 0 Hash is 22c608547e239faf5c353e7ebd204042760b93891d1d0be9ab488d36c73c077b Elapsed Time: 0.0000 seconds Hashing Power: 0 hashes per second Difficulty: 4 (2 bits) Starting search... Success with nonce 2 Hash is 0635f41cdb98c6e73516f84fc88da19a13a3bac6298dbfc0df5170bac93ba4dd Elapsed Time: 0.0000 seconds Hashing Power: 152520 hashes per second Difficulty: 8 (3 bits) Starting search... Success with nonce 9 Hash is 1c1c105e65b47142f028a8f93ddf3dabb9260491bc64474738133ce5256cb3c1 Elapsed Time: 0.0000 seconds Hashing Power: 428962 hashes per second Difficulty: 16 (4 bits) Starting search... Success with nonce 25 Hash is 0f7becfd3bcd1a82e06663c97176add89e7cae0268de46f94e7e11bc3863e148 Elapsed Time: 0.0000 seconds Hashing Power: 569878 hashes per second Difficulty: 32 (5 bits) Starting search... Success with nonce 36 Hash is 029ae6e5004302a120630adcbb808452346ab1cf0b94c5189ba8bac1d47e7903 Elapsed Time: 0.0001 seconds Hashing Power: 601573 hashes per second Difficulty: 64 (6 bits) Starting search... Success with nonce 0 Hash is 0083214fa878cea749bd07bd77e92b311be876dd72f3d4924d5ae4ead54febe5 Elapsed Time: 0.0000 seconds Hashing Power: 0 hashes per second Difficulty: 128 (7 bits) Starting search... Success with nonce 26 Hash is 00f7abab177613afc42270e3f5f79ffddd694093030663b32fe26ce2a377a993 Elapsed Time: 0.0000 seconds Hashing Power: 576994 hashes per second Difficulty: 256 (8 bits) Starting search... Success with nonce 33 Hash is 0055c56d412e6ab765048f1b8e7fce3b2553435c765c2899ee1bd3124d056098 Elapsed Time: 0.0001 seconds Hashing Power: 609744 hashes per second Difficulty: 512 (9 bits) Starting search... Success with nonce 2 Hash is 0025a3e3e764ad05f7945eb65d2a21445eded2209a2cd0e26fa8571bd886b0da Elapsed Time: 0.0000 seconds Hashing Power: 182361 hashes per second Difficulty: 1024 (10 bits) Starting search... Success with nonce 1514 Hash is 002a67dc2d861c93843e6dfdb0402f4fed2e87c8c30408f016ac83521e8f091b Elapsed Time: 0.0024 seconds Hashing Power: 635081 hashes per second Difficulty: 2048 (11 bits) Starting search... Success with nonce 856 Hash is 0014739d631bf69324d51dfa4ebcd28b03d09e6285d76fc9dc8b7c1e8ad1bf47 Elapsed Time: 0.0013 seconds Hashing Power: 680243 hashes per second Difficulty: 4096 (12 bits) Starting search... Success with nonce 2933 Hash is 00034d0888fb1cc74a4ee823eae4b71d8949e453da89f24caf3088b557f241c2 Elapsed Time: 0.0042 seconds Hashing Power: 690458 hashes per second Difficulty: 8192 (13 bits) Starting search... Success with nonce 2142 Hash is 00014006170118b30d97b81e4a824357d416866b469dfc56d16db31e5486f5a0 Elapsed Time: 0.0033 seconds Hashing Power: 655446 hashes per second Difficulty: 16384 (14 bits) Starting search... Success with nonce 8955 Hash is 0003295d9c3908df0275e074cd820af49a3e5975c487014a23fd7ba5fb98635b Elapsed Time: 0.0134 seconds Hashing Power: 670139 hashes per second Difficulty: 32768 (15 bits) Starting search... Success with nonce 32930 Hash is 00009a09fa6f72af0861650e655cf8901b33cf37614ddc0fcfa230294ee22988 Elapsed Time: 0.0510 seconds Hashing Power: 645458 hashes per second Difficulty: 65536 (16 bits) Starting search... Success with nonce 285299 Hash is 00009d85ce6e17b625bc50caafc7a42eab41d108a177cbfce39c4045bee69fd8 Elapsed Time: 0.4310 seconds Hashing Power: 661930 hashes per second Difficulty: 131072 (17 bits) Starting search... Success with nonce 10460 Hash is 000012726c26b999bb05e81322379a9ed9ecf08bd85347c752a913ec5e6942e6 Elapsed Time: 0.0158 seconds Hashing Power: 663617 hashes per second Difficulty: 262144 (18 bits) Starting search... Success with nonce 11980 Hash is 000020b111acbfe28ac4e68aa267154b12cb224bbf49f2c56db346f039b21395 Elapsed Time: 0.0180 seconds Hashing Power: 663941 hashes per second Difficulty: 524288 (19 bits) Starting search... Success with nonce 573192 Hash is 00001cce66856179a3feed94420d126a9dbddfa8830fc41b7fc5d36fdbf03ba0 Elapsed Time: 0.8649 seconds Hashing Power: 662750 hashes per second Difficulty: 1048576 (20 bits) Starting search... Success with nonce 237723 Hash is 000005720acd8c7207cbf495e85733f196feb1e3692405bea0ee864104039350 Elapsed Time: 0.3739 seconds Hashing Power: 635872 hashes per second Difficulty: 2097152 (21 bits) Starting search... Success with nonce 687438 Hash is 000003a6eeee97491a9183e4c57458172edb6f9466377bf44afbd74e410f6eef Elapsed Time: 1.1479 seconds Hashing Power: 598854 hashes per second Difficulty: 4194304 (22 bits) Starting search... Success with nonce 1759164 Hash is 0000008bb8f0e731f0496b8e530da984e85fb3cd2bd81882fe8ba3610b6cefc3 Elapsed Time: 2.8779 seconds Hashing Power: 611257 hashes per second Difficulty: 8388608 (23 bits) Starting search... Success with nonce 14214729 Hash is 000001408cf12dbd20fcba6372a223e098d58786c6ff93488a9f74f5df4df0a3 Elapsed Time: 23.0187 seconds Hashing Power: 617529 hashes per second Difficulty: 16777216 (24 bits) Starting search... Success with nonce 24586379 Hash is 0000002c3d6b370fccd699708d1b7cb4a94388595171366b944d68b2acce8b95 Elapsed Time: 39.7160 seconds Hashing Power: 619054 hashes per second Difficulty: 33554432 (25 bits) Starting search... Success with nonce 8570323 Hash is 00000009ecccb8289d6f94b3e861804e41c4530b0f879534597ff4d09aaa446d Elapsed Time: 12.9731 seconds Hashing Power: 660623 hashes per second Difficulty: 67108864 (26 bits)
如前所述,目标决定了难度,进而影响求解工作量证明算法所需要的时间。那么问题来了:为什么这个难度值是可调整的?由谁来调整?如何调整?
比特币的区块平均每10分钟生成一个。这是比特币的心跳,也是货币发行速率和交易结算速度的基础。不仅是在短期内,而且在几十年内它都必须要保持恒定。在此期间,计算机性能将飞速提升。此外,参与挖矿的人和计算机也会不断变化。为了保持10分钟产生一个新区块的周期,挖矿的难度必须根据这些变化进行调整。事实上,难度是一个动态的参数,会定期调整以达到每10分钟一个新区块的目标。简单地说,难度会根据当前全网的挖矿能力进行调整,从而保证10分钟产生一个新区块的周期。
那么,在一个完全去中心化的网络中,这样的调整是如何做到的呢?难度的调整是在每个节点中独立自动发生的。每2016个区块被产生后,所有节点都会调整难度。难度的调整是由最近2016个区块的花费时长与20,160分钟(即以标准10分钟一个区块的产生周期所花费的时长)比较得出的。难度是根据实际时长与期望时长的比值进行相应调整的(或变难或变易)。简单来说,如果网络发现区块产生周期比10分钟要快时会增加难度(目标值降低)。如果发现比10分钟慢时则降低难度(目标值提高)。
这个公式可以总结为如下形式:
新目标值 = 旧目标值 ×(最近2016个区块的真正时间/20160分钟)
值得注意的是目标难度与交易的数量、金额无关。这意味着散列算力的强弱以及让比特币更安全的电力投入量,与交易的数量完全无关。
换句话说,当比特币的规模变得更大,使用它的人数更多时,即使散列算力保持当前的水平,比特币的安全性也不会受到影响。散列算力的增加表明更多的人为得到比特币回报而加入了挖矿队伍。只要为了回报,公平正当地从事挖矿的矿工群体保持足够的散列算力,“接管”攻击就不会得逞,这让比特币的安全无虞。
挖矿的电力成本以及比特币与现金(用来支付电费)的兑换比率,这些因素和目标难度密切相关。高性能挖矿系统就是用当前硅芯片以最高效的方式将电力转化为散列算力。挖矿市场的关键因素就是每度电转换为比特币的价格,因为这决定着挖矿活动的营利能力,也因此刺激着人们选择进入或退出挖矿市场。
成功挖出区块
像我们之前看到的,Jing的节点已经构造了一个候选区块,准备用它来挖矿。Jing有几台安装了ASIC芯片的矿机,上面有成千上万个集成电路可以超高速地并行运行SHA256算法。还有许多类似的定制硬件通过USB或者局域网连接到他的挖矿节点。
接下来,运行在Jing的台式机上的挖矿节点将区块头传送给这些挖矿硬件,让它们以每秒亿万次的速度进行随机数测试。
在对区块277,316的挖矿工作开始大概11分钟后,这些硬件里的其中一个得到解并发回挖矿节点。当把这个结果放进区块头时,随机数4,215,469,401就会产生一个区块散列值:
0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569
而这个值小于难度目标值:
0000000000000003A30C00000000000000000000000000000000000000000000
Jing的挖矿节点立刻将这个区块发给所有相邻节点。这些节点在接收并验证这个新区块后,也会继续传播它。当这个新区块在网络中扩散时,每个节点都把这个新区块加入到自身的区块链副本中,并把区块链扩展到高度277,316。当挖矿节点收到并验证了这个新区块后,它们会放弃对这个相同高度区块的计算,将Jing的区块作为父区块,立即开始计算区块链中下一个区块。
矿工们在Jing新发现的区块之上构建新区块,这实际上是使用自己的挖矿算力进行投票,支持Jing的区块以及被该区块扩展的区块链。
验证新区块
比特币共识机制的第三步是网络中的每个节点独立验证每个新区块。当新区块在网络中传播时,每一个节点在将它转发到其节点之前,会进行一系列的测试去验证它。这确保了只有有效的区块才会在网络中传播。独立校验还确保了诚实的矿工生成的区块才可以被纳入到区块链中,从而获得奖励。行为不诚实的矿工所产生的区块将被拒绝,这不但使他们失去了奖励,而且也浪费了本来可以去寻找工作量证明解的机会,因而导致电费损失。
当一个节点接收到一个新的区块,它将对照一个长长的规范清单对该区块进行验证,若没有通过验证,这个区块将被拒绝。这些规范可以在比特币核心客户端的CheckBlock函数和CheckBlockHead函数中获得,包括:
- 区块的数据结构语法有效
- 区块头散列值小于难度目标(工作量证明要求)
- 区块时间戳早于验证时刻未来两个小时(允许时间误差)
- 区块大小在限制范围之内
- 第一个交易(且只有第一个)是创币交易
- 使用规范清单验证区块内的所有交易并确保它们有效
每一个节点对每一个新区块的独立校验,确保了矿工无法欺诈。
在前面的章节中,我们看到了矿工们如何去记录一笔交易,从而创造区块以获得新比特币和交易费。为什么矿工不为他们自己记录一笔交易去获得数以千计的比特币?这是因为每一个节点都会根据相同的规则对区块进行验证。一个无效的创币交易将使整个区块无效,还会导致该区块被拒绝,因此,该交易不会成为总账的一部分。矿工必须根据所有节点遵循的共同规则构建一个完美的区块,并通过正确的工作量证明方案来挖掘它。为此,他们在采矿中耗费大量的电力,如果他们作弊,所有的电力和努力都会浪费。
这就是为什么独立验证是去中心化共识的重要组成部分。
区块链的组装与选择
比特币去中心化共识机制的最后一步是将区块组装入链,并选择最大工作量证明的链。一旦一个节点验证了一个新的区块,它会尝试将新的区块连接到现存的区块链,将它们组装起来。
节点维护三种区块:
- 第一种是连接到主链上的
- 第二种是从主链上产生分支的(备用链)
- 最后一种是在已知链中找不到父区块的(孤块)
在验证过程中,一旦发现有任何一条不符合规范,验证就会失败,这个区块就会被节点拒绝,所以也不会被加入到任何一条链中。
任何时候,主链都是所有有效链中累计了最多工作量证明的那条区块链。在一般情况下,主链也是包含最多区块的那个链,也存在有两个等长的链,但是必定其中有一个有更多的工作量证明。主链也会有一些分支,这些分支中的区块与主链上的区块互为“兄弟”区块。这些区块是有效的,但不是主链的一部分。保留这些分支的目的是如果在未来的某个时刻它们中的一个延长了并在累积工作量证明上超过了主链,那么后续的区块就会引用它们。
当节点接收到新区块,它会尝试将这个区块插入现有区块链中。节点会看一下这个区块的“父区块散列”字段,这个字段引用该区块的父区块。然后,这个节点将尝试在已存在的区块链中找出这个父区块。大多数情况下,父区块位于主链的“顶点”,这就意味着这个新的区块延长了主链。举个例子,一个新的区块277,316引用了它的父区块277,315的散列值。大部分节点都已经将277,315作为主链的顶端,因此它们收到277,316区块后,就可以将区块链延长。
有时,新区块所延长的区块链并不是主链,这一点我们将在“区块链分叉”一节中看到。在这种情况下,节点将新的区块添加到备用链,同时比较备用链与主链的工作量。如果备用链比主链积累了更多的工作量,节点将收敛于备用链,意味着节点将选择备用链作为其新的主链,而之前那个老的主链则成为备用链。如果节点是一个矿工,它将开始构造新的区块,来延长这个更新更长的区块链。
如果节点收到了一个有效的区块,而在现有的区块链中却未找到它的父区块,那么这个区块被认为是“孤块”。孤块会被保存在孤块池中,直到节点收到它们的父区块。一旦收到了父区块并且将其连接到现有区块链上,节点就会将孤块从孤块池中取出,并且连接到它的父区块,让它作为区块链的一部分。当两个区块在很短的时间间隔内被挖出来,节点有可能会以相反的顺序(子在父之前)接收到它们,此时孤块现象就会出现。
通过选择有效的最大累计工作量区块链,所有的节点最终在全网范围内达成共识。随着更多的工作量证明被添加到链中,扩展了可能的链中的一条,链的暂时性差异最终会得到解决。挖矿节点通过选择它们想要延长的区块链进行“投票”。当它们挖出一个新块并且延长了一个链,新块本身就代表它们的投票。
区块链的分叉
因为区块链是去中心化的数据结构,所以不同副本之间不可能总是保持一致。区块有可能在不同时间到达不同节点,导致节点有不同的区块链全貌。解决的办法是,每一个节点总是选择并尝试延长累计了最大工作量证明的区块链,也就是最长的或最大累计工作量链。节点通过累加链上的每个区块的工作量,得到这个链的工作量证明的总量。只要所有的节点选择最大累计工作量链,整个比特币网络最终会收敛到一致的状态。区块链版本的临时差异会导致分叉,随着更多的区块添加到了某个分叉中,这个问题便会迎刃而解。
由于全球网络中的传输延迟,本节中描述的区块链分叉会自然发生。我们也将在本章稍后再看看故意引起的分叉。
在接下来的几个图表中,我们将通过网络跟踪“分叉”事件的进展,该图是比特币网络的简化表示。为了便于描述,不同的区块被显示为不同的形状(星形、三角形、倒三角形、菱形)遍布在网络中。网络中的每个圆表示一个节点。
每个节点都有自己的全局区块链视角。当每个节点从其邻居接收区块时,它会更新其自己的区块链副本,并选择最大累积工作量链。为便于描述,每个节点包含一个图形形状,表示它相信的区块处于主链的顶端。因此,如果在节点里面看到星形,那就意味着该节点认为星形区块处于主链的顶端。
在下图中,网络有一个统一的区块链视角,以星形区块为主链的“顶点”。
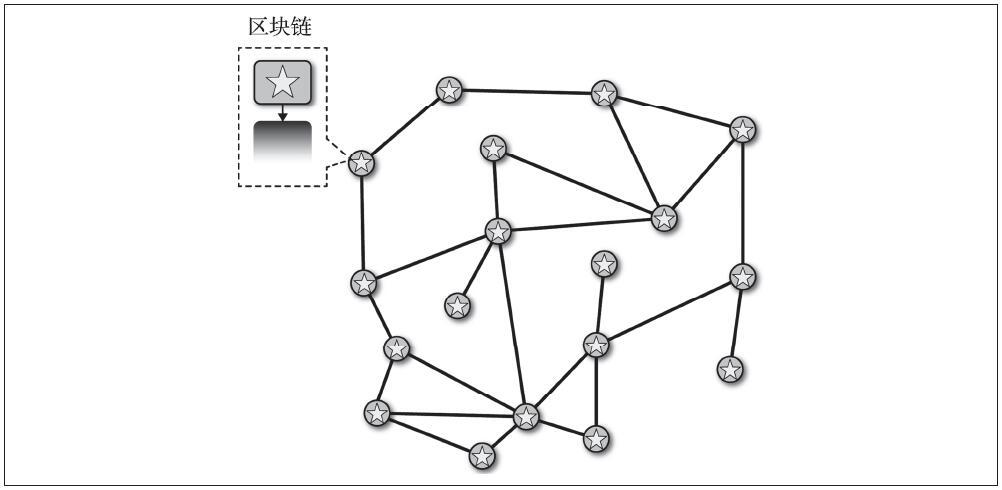
有两个候选区块同时想要延长最长区块链时,分叉事件就会发生。
正常情况下,当两名矿工几乎同时计算出工作量证明解时,分叉就会发生。两个矿工在各自的候选区块发现解后,便立即传播自己的“获胜”区块到网络中,先是传播给邻近的节点而后传播到整个网络。收到有效区块的每个节点都会将其并入副本并延长区块链。如果该节点在随后又收到了另一个候选区块,而这个区块又拥有同一父区块,那么节点会将这个区块连接到备用链上。其结果是,一些节点“看到”了一个候选区块,而另一些节点“看到”了另一个候选区块,这时就出现了两个竞争版本的区块链。
在下图中,我们看到两个矿工(节点X和节点Y)几乎同时挖到了两个不同的区块。这两个区块是星形区块的子区块,可以延长这个区块链。为了便于查看,我们把节点X产生的区块标记为三角形,把节点Y产生的区块标记为倒三角形。
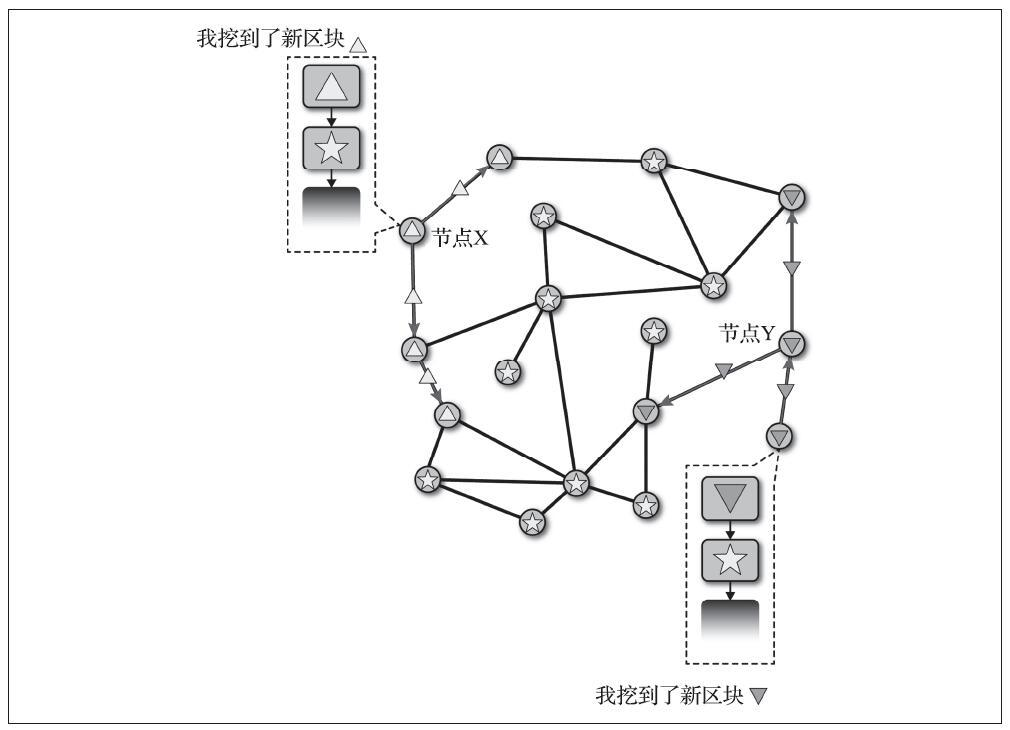
如果我们假设矿工节点X找到三角形区块工作量证明的解,将它构建在星形父区块的顶端。与此同时,同样进行星形区块扩展的节点Y也找到了倒三角形区块工作量证明的解并以此扩展区块链。
现在有两个可能的块,节点X的三角形区块和节点Y的倒三角形区块,这两个区块都是有效的,均包含有效的工作量证明解并延长同一个父区块(星形区块)。这两个区块可能包含了几乎相同的交易,只是在交易的排序上有些许不同。
当两个区块开始在网络传播时,一些节点首先接收到三角形区块,另外一些节点首先接收倒三角形区块。如下图所示,比特币网络上的节点对于区块链的顶点产生了分歧,一派以三角形区块为顶点,而另一派以倒三角形区块为顶点。
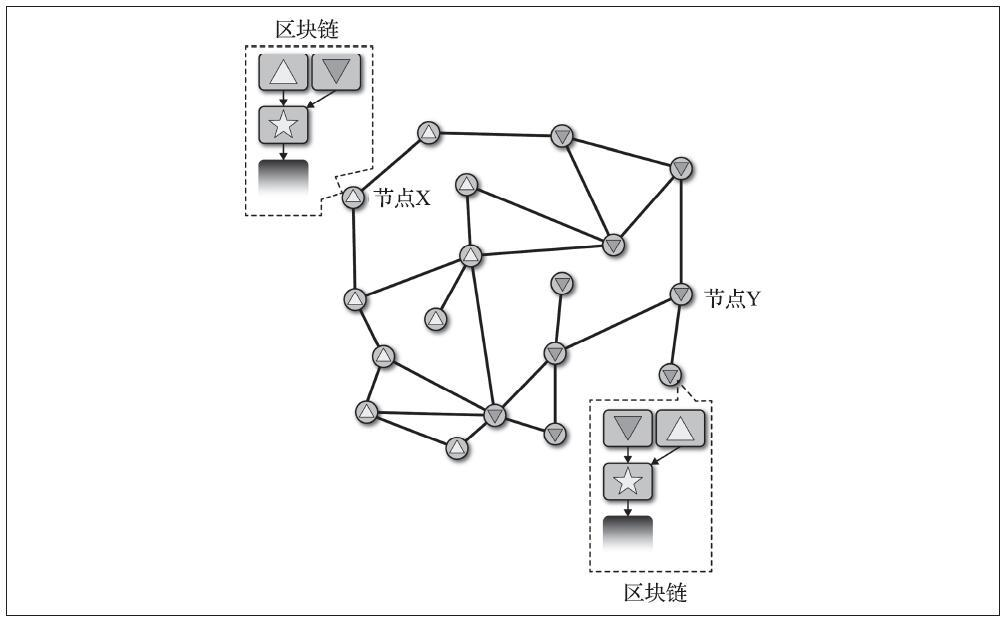
在上图中,假设节点X首先接收到三角形块,并用它扩展星形链。节点X选择三角形区块为主链。之后,节点X收到了倒三角区块。由于是第二次收到,因此它判定这个倒三角形区块是竞争失败的产物。然而,倒三角形的区块不会被丢弃。它被链接到星形链的父区块,并形成备用链。虽然节点X认为自己已经正确选择了获胜链,但是它还会保存“失败”链,如果“失败”链最终“获胜”,它还具有重新打包的所需的信息。
在网络的另一端,节点Y根据自己的视角构建一个区块链。首先获得倒三角形区块,并选择这条链作为“赢家”。当它稍后收到三角形区块时,它也将三角形区块连接到星形链的父区块作为备用链。
双方都是“正确的”或“不正确的”。两者都是自己对于区块链的有效立场。只有事后才能理解这两个竞争链如何通过额外的工作得到延伸。
节点X阵营的其他节点将立即开始挖掘候选区块,以“三角形”作为扩展区块链的顶端。通过将“三角形”作为候选区块的父区块,它们用自己的散列算力进行投票。它们的投票表明支持自己选择的链为主链。
同样,节点Y阵营的其他节点,将开始构建一个以“倒三角形”作为其父节点的候选节点,扩展它们认为是主链的链,竞争再次开始。
分叉问题几乎总是在一个区块的数量级别内就被解决了。网络中的一部分算力专注于“三角形”区块为父区块,在其之上建立新的区块;另一部分算力则专注在“倒三角形”区块上。即便算力在这两个阵营中平均分配,也总有一个阵营抢在另一个阵营前发现工作量证明解并将其传播出去。在这个例子中我们可以打个比方,假如工作在“三角形”区块上的矿工找到了一个“菱形”区块,延长了区块链(星形-三角形-菱形),他们会立刻传播这个新区块,整个网络会都会认为这个区块是有效的,如下图所示。
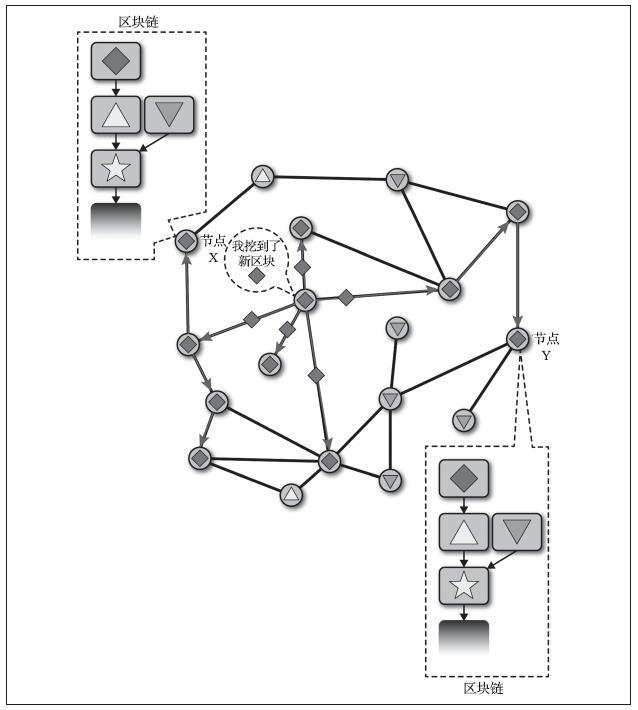
选择“三角形”作为上一轮中胜出者的所有节点会简单地将区块链扩展一个区块。然而,选择“倒三角”的节点现在将看到两个链:星形-三角形-菱形和星型-倒三角形。星形-三角形-菱形这条链现在比其他链条更长(累积更多工作量)。因此,这些节点将星形-三角形-菱形设置为主链,并将星型-倒三角形链变为备用链,如下图所示。
这是一个链的重新共识,因为这些节点被迫修改它们对区块链的立场,将更长的链当成主链。任何从事延伸星形-倒三角形的矿工现在都将停止这项工作,因为他们打包的候选区块是“孤块”,这个孤块的父区块——“倒三角形”不再是最长的链。“倒三角形”内的交易重新插入到内存池中用来包含在下一个块中,因为它们所在的区块不再位于主链中。整个网络重新回到单一链状态——星形-三角形-菱形,“菱形”成为链中的最后一个块。所有矿工立即开始构建以“菱形”为父区块的候选区块,以扩展这条星形-三角形-菱形链。
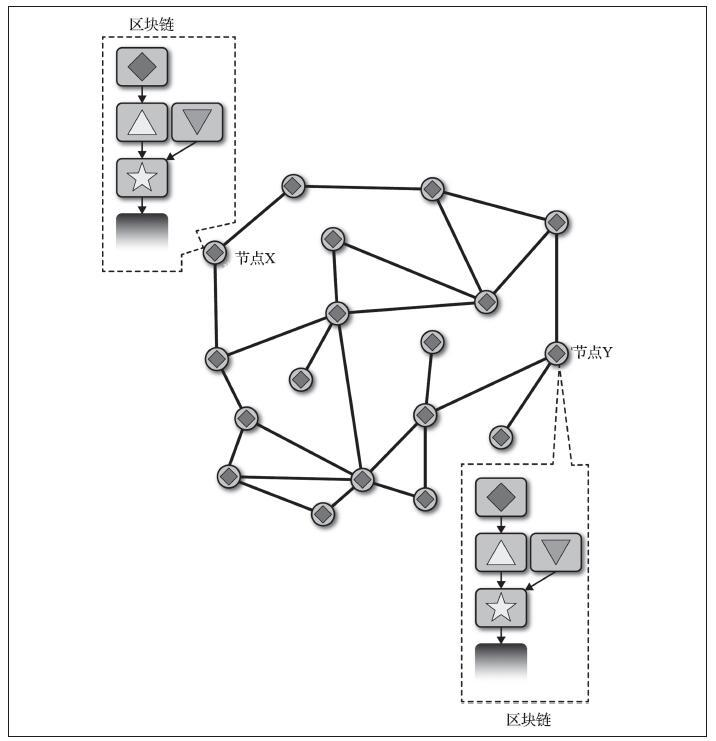
理论上来说,两个区块的分叉是有可能的,这种情况发生在因先前分叉而相互对立起来的矿工,又几乎同时发现了两个不同区块的解。然而,这种情况发生的概率是很低的。单区块分叉每天都会发生,而双区块分叉最多每隔几周才会发生一次。
比特币将区块间隔设计为10分钟,是在更快速的交易确认(交易结算)和更低的分叉概率间做出的妥协。
- 更短的区块产生间隔会让交易清算更快完成,也会导致更加频繁的区块链分叉。
- 更长的间隔会减少分叉数量,却会导致更长的结算时间。
挖矿和算力竞争
比特币挖矿是一个极富竞争性的行业。自从比特币诞生开始,每年比特币算力都呈指数增长。一些年份的增长还反映出技术的变革,比如在2010年和2011年,很多矿工开始从使用CPU升级到使用GPU,进而使用现场可编程门阵列(FieldProgrammable Gate Array,FPGA)进行挖矿。在2013年,ASIC挖矿的引入,把SHA256算法直接固化在挖矿专用的硅芯片上,导致了算力的另一次巨大飞跃。第一台采用这种芯片的矿机可以提供的算力,比2010年比特币网络的整体算力还要大。
下面列出了比特币网络开始运行后最初5年的总算力:
- 2009:0.5MH/sec-8 MH/sec(16倍增长)
- 2010:8 MH/sec-116 GH/sec(14,500倍增长)
- 2011:16 GH/sec-9 TH/sec(562倍增长)
- 2012:9 TH/sec-23 TH/sec(2.5倍增长)
- 2013:23 TH/sec-10 PH/sec(450倍增长)
- 2014:10 PH/sec-300 PH/sec(3000倍增长)
- 2015:300 PH/sec-800 PH/sec(266倍增长)
- 2016:800 PH/sec-2.5 EH/sec(312倍增长)
在下图中,我们可以看到近两年里,比特币网络算力的增长。正如你所看到的,矿工之间的竞争和比特币的发展导致算力(网络中每秒的总散列值)呈指数级增长。
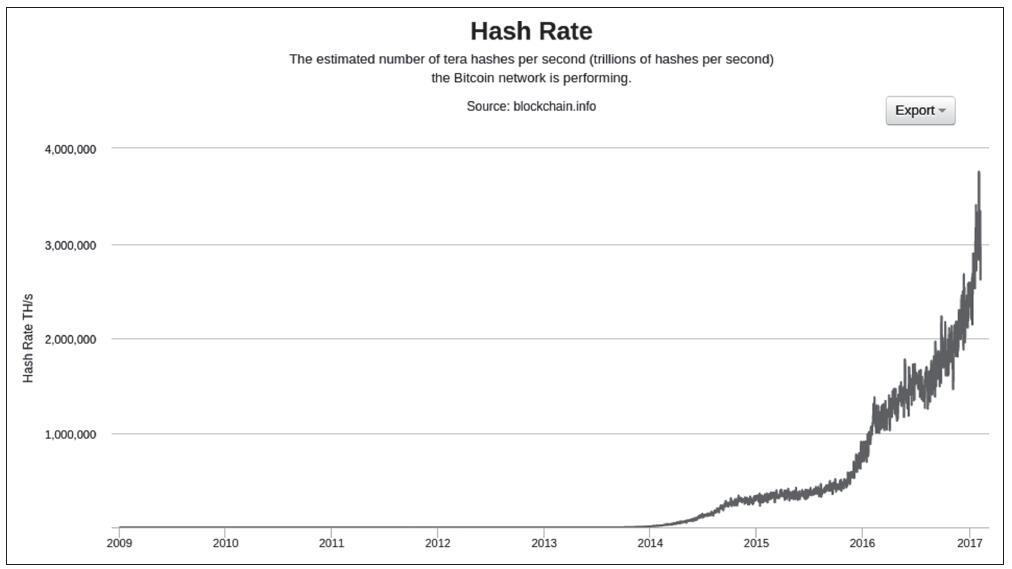
随着比特币挖矿算力的爆炸性增长,与之匹配的难度也相应增长。下图中的难度指标显示了当前难度与最小难度(第一个区块的难度)的比率。
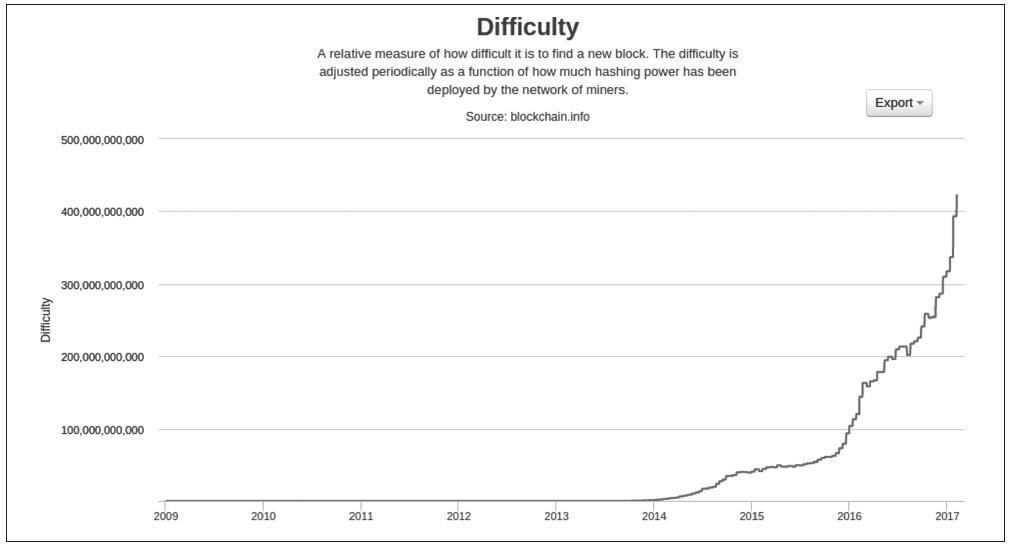
近两年,ASIC芯片变得更加密集,已经接近芯片制造业前沿的16纳米特征尺寸。目前,由于挖矿的利润率驱动这个行业以比通用计算更快的速度发展,ASIC制造商的目标是超越通用CPU芯片制造商,设计特征尺寸为14纳米的芯片。对比特币挖矿而言,已经没有更多飞跃的空间,因为这个行业已经触及了摩尔定律的最前沿,摩尔定律指出计算密度每18个月翻一番。尽管如此,随着更高密度的芯片和高密度数据中心的部署竞争,网络算力继续保持指数级增长,数据中心可以部署数千个这样的芯片。现在的竞争已经不再是比较单一芯片的能力,而是一个矿场能塞进多少芯片,并处理好散热和供电问题。
(1)随机数升位方案
2012年以来,比特币挖矿发展出一个解决区块头基本结构限制的方案。在比特币的早期,矿工可以通过遍历随机数来找到一个块,直到产生的散列值低于目标值。难度增长后,矿工经常在尝试了40亿个值后仍然没有出块。然而,这很容易通过更新区块的时间戳并计算经过的时间来解决。因为时间戳是区块头的一部分,它的变化可以让矿工用不同的随机数再次遍历。但是当挖矿硬件的速度达到了4GH/s,这种方法变得越来越困难,因为随机数的取值在一秒内就被用尽了。当出现ASIC矿机并很快达到了TH/s的散列速率后,挖矿软件为了找到有效的块,需要更多的空间来储存随机数值。可以把时间戳延后一点,但将来如果把它移动得太远,会导致区块变为无效。
区块头需要一个新的随机数值的来源。解决方案是使用创币交易作为额外的随机数值来源,因为创币脚本可以储存2~100字节的数据,矿工们开始使用这个空间作为额外随机数的来源,允许他们去探索一个大得多的区块头值范围来找到有效的区块。这个创币交易也包含在默克尔树中,这意味着任何创币脚本的变化将导致默克尔树根的变化。8个字节的额外随机数,加上4个字节的“标准”随机数,允许矿工每秒尝试296(8后面跟28个零)种可能性而无须修改时间戳。如果未来矿工用尽了以上所有的可能性,他们还可以通过修改时间戳来解决。同样,创币脚本中也有更多额外的空间可以为将来随机数的扩展做准备。
(2)矿池
在这个激烈竞争的环境中,个体矿工独立工作(也就是solo挖矿)没有一点机会。他们找到一个区块以抵消电力和硬件成本的可能性非常小,以至于可以称得上是赌博,或是买彩票。就算是最快的消费型ASIC矿机也不能和那些在巨大机房里拥有数万芯片并靠近水电站的商业矿场竞争。现在矿工们合作组成矿池,汇集数以千计参与者们的算力并分享奖励。通过参加矿池,矿工们虽然只能得到整体奖励的一小部分,但几乎每天都能得到,因而减少了不确定性。
让我们来看一个具体的例子。假设一名矿工已经购买了算力共计14,000GH/s,或14TH/s的设备,在2017年,它的价值大约是2500美元。该设备运行功率为1375W(1.3kW),每日耗电32度,电价比较低的情况下每日成本为1美元或2美元。以目前的比特币难度,该矿工独立挖矿方式挖出一个区块平均需要4年。如果这个矿工确实在这个时限内挖出一个区块,奖励12.5个比特币,若每个比特币价格约为1000美元,他可以得到12,500美元的收入。这甚至不能覆盖整个硬件投入和整个时间段的电力消耗,净亏损约为1000美元。而且,在4年的时间周期内能否挖出一个区块还要靠矿工的运气。他有可能在4年中得到两个块从而赚到非常大的利润。或者,5年都找不到一个块,从而遭受经济损失。更糟的是,比特币的工作量证明算法的难度可能在这段时间内显著上升,按照目前算力增长的速度,意味着矿工在设备过时而必须被下一代更有效率的矿机取代之前,最多有1年的时间取得成果。如果这个矿工加入矿池,而不是等待4年内可能出现一次的暴利,他每周能赚取50~60美元。矿池的常规收入能帮他随时间摊销硬件和电力的成本,并且不用承担巨大的风险。在一两年后,硬件仍然会过时,风险仍然很高,但在此期间的收入至少是定期的和可靠的。从财务数据分析,这只有非常低的电力成本(每千瓦不到1美分),规模非常大时才有意义。
矿池通过专用挖矿协议协调成百上千的矿工。个人矿工在建立矿池账号后,设置他们的矿机连接到矿池服务器。他们的挖矿设备在挖矿时保持和矿池服务器的连接,与其他矿工同步各自的工作。这样,矿池中的矿工分享挖矿任务,之后分享奖励。
成功出块的奖励支付到矿池的比特币地址,而不是单个矿工的。一旦奖励达到一个特定的阈值,矿池服务器便会定期支付奖励到矿工的比特币地址。通常情况下,矿池服务器会为提供矿池服务收取一定百分比的费用。
参加矿池的矿工把搜寻候选区块的工作量分割,并根据他们挖矿的贡献赚取“份额”。矿池为赚取“份额”设置了一个较高的目标值(较低难度),通常比比特币网络的难度低1000倍以上。当矿池中有人成功挖出一个区块,矿池获得奖励,并按照矿工们做出算力贡献的份额的比例给他们分配奖励。
矿池对任何矿工开放,无论大小、专业或业余。一个矿池的参与者中,有人只有一台小矿机,而有些人有一车库高端挖矿硬件。有人只用几十度电挖矿,也有人会用一个数据中心消耗兆瓦级的电量。矿池如何衡量每个人的贡献,既能公平分配奖励,又避免作弊的可能?答案是使用比特币的工作量证明算法来衡量每个矿池矿工的贡献,但设置的难度较小,以至于即使是矿池中最小的矿工也经常能分得奖励,这足以激励他们为矿池做出贡献。通过设置一个较低的取得份额的难度,矿池可以计量出每个矿工完成的工作量。每当矿工发现一个小于矿池难度的区块头散列值,就证明了它已经完成了分配给自己的寻找结果所需的散列计算。更重要的是,这些为取得份额贡献而做的工作,能以一个统计学的方法,通过寻找一个比比特币网络的目标更低的散列值来衡量。成千上万试图寻找低散列值的矿工最终会找到一个足以满足比特币网络难度目标的结果。
让我们回到骰子游戏的比喻。如果骰子玩家的目标是扔骰子结果都小于4(整体网络难度),矿池可以设置一个更容易的目标,统计有多少次池中的玩家扔出的结果小于8。当池中的玩家扔出的结果小于8(矿池份额目标),他们得到份额,但他们没有赢得游戏,因为没有完成游戏目标(小于4)。但池中的玩家会经常达到较容易的矿池份额目标,规律地赚取他们的份额,尽管他们没有完成更难的赢得比赛的目标。时不时地,池中的一个成员有可能会扔出一个小于4的结果,矿池获胜。然后,收益可以在池中玩家获得的份额基础上分配。尽管目标设置为8或更小并没有赢得游戏,但是这是一个衡量玩家们扔出的点数的公平方法,同时偶尔也会产生一个小于4的结果。
同样地,一个矿池也会设置(更高、更容易)矿池难度目标,保证一个单独的矿工能够频繁找到一个小于矿池难度目标的区块头散列值来赢取份额。某次尝试时不时地会产生一个符合比特币网络难度目标值的区块头散列值,产生一个有效块,然后整个矿池获胜。
1、托管矿池
大部分矿池是“托管的”,意思是有一个公司或者个人经营一个矿池服务器。矿池服务器的所有者叫矿池管理员,同时他从矿工的收入中收取一定百分比的费用。
矿池服务器运行专业软件以及协调池中矿工们活动的矿池采矿协议。矿池服务器同时也连接到一个或更多比特币全节点,并直接访问一个区块链数据库的完整副本。这使得矿池服务器可以代替矿池中的矿工验证区块和交易,缓解他们运行一个完整节点的负担。对于矿池中的矿工,这是一个重要的考虑因素,因为一个全节点要求是一个拥有最少100~150GB的永久储存空间(磁盘)和最少2~4GB内存(RAM)的专用计算机。此外,运行一个全节点的比特币软件需要监控、维护和频繁升级。由于缺乏维护或资源导致的任何宕机都会伤害到矿工的利润。对于很多矿工来说,不需要运行一个完整节点就能采矿,也是加入托管矿池的一大好处。
矿工连接到矿池服务器使用一个采矿协议,比如Stratum(STM)或者GetBlockTemplate(GBT)。旧标准GetWork(GWK)从2012年年底基本过时了,因为它不支持在算力超过4GH/s时挖矿。STM协议和GBT协议都创建包含候选区块头模板的区块模板。矿池服务器通过打包交易、添加创币交易(及额外的随机数空间)、计算默克尔树根,并链接到父区块散列,来建立一个候选区块。这个候选区块的头部作为模板分发给每个矿工。矿工用这个区块模板以比比特币网络的难度目标更高(更容易)为目标进行采矿,并发送成功的结果给矿池服务器以赚取份额。
2、P2P矿池(P2Pool)
托管矿池存在管理员作弊的可能,管理员可以利用矿池进行双重支付或使区块无效。此外,中心化的矿池服务器代表着单点故障。如果因为拒绝服务攻击导致服务器宕机或者反应减慢,池中所有矿工就不能采矿。在2011年,为了解决由中心化造成的这些问题,提出和实施了一个新的矿池挖矿方法:P2Pool,它是一个点对点的矿池,没有中心管理员。
P2Pool通过将矿池服务器的功能去中心化,实现一个并行的类区块链系统,名叫份额链(share chain)。份额链是一个难度低于比特币区块链的区块链系统。份额链允许池中矿工在一个去中心化的池中合作,以每30秒一个份额区块的速度在份额链上采矿,获得份额。份额链上的区块记录了贡献工作的矿工的份额,并且继承了之前份额区块上的份额记录。当其中一个份额区块达到了比特币网络的难度目标时,它将被广播并包含到比特币的区块链上,同时奖励所有已经在份额链区块中取得份额的池中矿工。本质上说,比起用一个矿池服务器记录矿工的份额和奖励,份额链允许所有矿工通过类似比特币区块链系统的去中心化的共识机制跟踪所有份额。
P2P矿池挖矿方式比在中心化矿池中采矿要复杂得多,因为它要求矿工运行空间、内存、带宽充足的专用计算机来支持一个比特币的全节点和P2P矿池节点软件。P2P矿池矿工连接他们的采矿硬件到本地P2P矿池节点,节点通过发送区块模板到矿机来模拟矿池服务器的功能。在P2P矿池中,单独的矿工创建自己的候选区块,打包交易,非常类似于独立矿工,但是他们在份额链上合作采矿。与单独挖矿相比,P2P矿池是一种混合方式,有更灵活的收入优势,但是不会像托管矿池那样给管理人太多权力。
即使P2P矿池减少了矿池运营商的中心化程度,但也可能容易受到份额链本身的51%的攻击问题。相反,作为多样化挖矿生态系统的一部分,P2P矿池使得比特币整体更加强大。
共识攻击
至少理论上,比特币的共识机制是容易被矿工(或矿池)试图使用自己的算力实行欺骗破坏进行攻击的。就像我们前面讲的,比特币的共识机制依赖于这样一个前提,那就是绝大多数的矿工,出于自己利益最大化的考虑,都会通过诚实地挖矿来维持整个比特币系统。然而,当一个或者一群矿工拥有了整个系统中大量算力之后,他们就可以通过攻击比特币的共识机制来达到破坏比特币网络的安全性和可靠性的目的。
值得注意的是,共识攻击只能影响整个区块链未来的共识,或者说,最多能影响最近的区块的共识(最多影响过去几十个块)。而且随着时间的推移,整个比特币区块链被篡改的可能性越来越低。理论上,一个区块链分叉可以是任意深度,但实际上,要想实现一定深度的区块链分叉需要的算力非常大,这使得旧的区块几乎根本无法改变。同时,共识攻击也不会影响用户的私钥以及签名算法(ECDSA)。共识攻击也不能从其他的钱包那里偷到比特币、不签名地支付比特币、重新分配比特币、改变过去的交易或者改变比特币持有记录。共识攻击只能影响最近的区块,通过拒绝服务来破坏未来区块的生成。
共识攻击的一个典型场景就是“51%攻击”。想象这么一个场景,一群矿工控制了整个比特币网络51%的算力,他们联合起来打算攻击整个比特币系统。由于这群矿工可以生成绝大多数的区块,他们就可以通过故意制造区块链分叉来实现“双重支付”或者通过拒绝服务的方式来阻止特定的交易或者攻击特定的钱包地址。区块链分叉/双重支付攻击指的是攻击者通过从指定区块之前的区块开始分叉,导致其后的已经确认的区块无效,然后重新收敛这些区块到一个替代的区块链。有了充足算力的保证,一个攻击者可以一次性篡改最近的6个或者更多的区块,从而使得这些区块包含的本应无法篡改的交易无效。值得注意的是,双重支付只能在攻击者拥有的钱包所发生的交易上进行,因为只有钱包的拥有者才能生成一个合法的签名用于双重支付交易。攻击者在自己的交易上进行双重支付攻击,如果可以通过使交易无效而实现一种不可逆转的且不用付款的购买行为,这种攻击就是有利可图的。
让我们看一个“51%攻击”的实际案例。Alice和Bob之间使用比特币完成了一杯咖啡的交易。咖啡店老板Bob愿意在Alice给自己的转账交易未经确认(区块挖矿)的时候就向其提供咖啡,这是因为与顾客购物的即时性、便利性相比,一杯咖啡的双重消费风险更低。这就和大部分的咖啡店对低于25美元的信用卡消费不会费时费力地向顾客索要签名是一样的,因为和信用卡退款的风险比起来,向用户索要信用卡签名的成本更高。相比之下,使用比特币支付的大额交易被双重支付的风险就高得多了,因为买家(攻击者)可以通过在全网广播一个和真实交易的UTXO一样的伪造交易,以达到取消真实交易的目的。双重支付可以有两种方式:要么是在交易被确认之前,要么攻击者通过区块链分叉来撤销几个区块。进行51%攻击的人,可以取消在旧链上的交易记录,然后在新分叉链上重新生成一个同样金额的交易,从而实现双重支付。
再举个例子:攻击者Mallory在Carol的画廊购买了将中本聪描绘为普罗米修斯的三联组画(The Great Fire),Mallory通过转账价值25万美元的比特币与Carol进行交易。在等到一个而不是六个交易确认之后,Carol将这幅组画包好,交给了Mallory。这时,Mallory的一个同伙,一个拥有大量算力的矿池的人Paul,在这笔交易写进区块链的时候,开始了51%攻击。首先,Paul指示矿池使用同样的区块高度重新对包含这笔交易的区块进行挖矿,并且在新区块里将原来的交易替换成了支付给Mallory的另外一笔交易,从而实现了双重支付。这笔双重支付交易使用了跟原有交易一致的UTXO,但收款人被替换成了Mallory的钱包地址而不是Carol的,实际上就是Mallory继续持有自己的比特币。然后,Paul指示矿池在伪造区块的基础上,又计算出一个更新的块,这样,包含这笔双重支付交易的区块链比原有的区块链高出了一个区块(导致从包含Mallory交易之前的区块开始分叉)。到此,高度更高的分叉区块链取代了原有的区块链,双重支付交易取代了原来给Carol的交易,Carol既没有收到价值25万美金的比特币,原本拥有的三幅价值连城的画也被Mallory白白拿走了。在整个过程中,Paul矿池里的其他矿工可能自始至终都没有觉察到这笔双重支付交易有什么异样,因为挖矿程序都是自动在运行,并且不会时时监控每一个区块中的每一笔交易。
为了避免这类攻击,售卖大宗商品的商家应该在交易得到全网的6个确认之后再交付商品。或者,商家应该使用第三方的多方签名的账户进行交易,并且也要等到交易账户获得全网多个确认之后再交付商品。一条交易的确认数越多,越难被攻击者通过51%攻击篡改。对于大宗商品的交易,即使在付款24小时之后再发货,对买卖双方来说使用比特币支付也是方便并且有效率的。而24小时之后,这笔交易的全网确认数将达到至少144个(能有效降低被51%攻击的可能性)。
共识攻击中除了“双重支付”攻击,还有一种攻击场景就是拒绝为某个特定参与者(特定比特币地址)提供服务。一个拥有了系统中绝大多数算力的攻击者,可以轻易地忽略某一笔特定的交易。如果这笔交易存在于另一个矿工所产生的区块中,该攻击者可以故意分叉,然后重新产生这个区块,并且把想忽略的交易从这个区块中移除。这种攻击造成的结果就是,只要这名攻击者拥有系统中的绝大多数算力,那么他就可以持续地干预某一个或某一批特定钱包地址产生的所有交易,从而达到拒绝为这些地址服务的目的。
需要注意的是,51%攻击并不是像它的命名说的那样,攻击者需要至少51%的算力才能发起,实际上,即使其拥有不到51%的系统算力,依然可以尝试发起这种攻击。之所以命名为51%攻击,只是因为在攻击者的算力达到51%这个阈值的时候,其发起的攻击尝试几乎肯定会成功。从本质上来看,共识攻击就像是针对下一个区块的拔河比赛,强壮的组最可能赢。随着算力的降低,成功的可能性降低,因为其他矿工以“诚实”的挖矿能力控制着一些区块的产生。从另一个角度讲,一个攻击者拥有的算力越多,其故意创造的分叉区块链就可能越长,可能被篡改的最近的区块或者受其控制的未来的区块就会越多。一些安全研究组织利用统计模型得出的结论是,算力达到全网的30%就足以发动51%攻击了。
全网算力的急剧增长已经使得比特币系统不再可能被某一个矿工攻击。独立矿工不可能控制总算力的哪怕是很小的一部分。但是中心化控制的矿池则带来了矿池操作者出于利益而施行攻击的风险。矿池操作者控制了候选区块的生成,同时也控制哪些交易会被放到新生成的区块中。这样一来,矿池操作者就拥有了剔除特定交易或者双重支付的权力。如果这种权力被矿池操作者以微妙而有节制的方式滥用,那么矿池操作者就可以在不为人知的情况下发动共识攻击并获益。
但是,并不是所有的攻击者都是为了利益。一个可能的场景就是,攻击者仅仅是为了破坏整个比特币系统而发动攻击,而不是为了利益。这种意在破坏比特币系统的攻击者需要巨大的投入和精心的计划。同样地,这类资金充足的攻击者或许也会购买矿机,运营矿池,对其他矿池施行拒绝服务等共识攻击。但是随着比特币网络的算力呈指数级快速增长,上述这些理论上可行的攻击场景,实际操作起来已经越来越困难了。
毫无疑问,一次严重的共识攻击事件势必会降低人们对比特币系统的信心,进而可能导致比特币价格的跳水。然而,比特币系统和相关软件也一直在持续改进,所以比特币社区也势必会对任何一次共识攻击快速做出响应,以使整个比特币系统比以往更加稳健和可靠。
改变共识规则
共识规则决定交易和区块的有效性。这些规则是所有比特币节点之间协作的基础,并负责将整个网络中所有不同角色的本地观点融合为一条一致的区块链。
虽然共识规则在短期内是不变的,并且在所有节点之间必须一致,但长期来看它们并不总是不变的。为了演进和开发比特币系统,规则必须随时改变以适应新功能、改进或修复错误。然而,与传统软件开发不同,升级共识系统要困难得多,需要所有参与者之间的协调。
(1)硬分叉
在“区块链分叉”一节中,我们研究了比特币网络如何短暂地分叉,网络中的两个部分在短时间内处于区块链的两个不同分支。我们看到这个过程是如何自然发生的,作为网络的正常运行的一部分,以及如何在一个或多个区块被挖掘之后,网络在一个统一的区块链上重新收敛。
另一种情况是,网络也可能会分叉到两条链,这是由于共识规则的变化。这种分叉称为硬分叉,因为这种分叉后,网络不会重新收敛到单个区块链上。相反,这两条区块链独立发展。当比特币网络的一部分节点按照与网络的其余部分节点不同的共识规则运行时,硬分叉就会发生。这可能是由于错误或者故意实施对共识规则的改变而发生的。
硬分叉可用于改变共识规则,但需要在系统中所有参与者之间进行协调。没有升级到新的共识规则的任何节点都不能参与共识机制,并且被强制保留在硬分叉时刻单独的区块链上。因此,硬分叉引入的变化可以被认为不是“向前兼容”,因为未升级的系统不能再处理新的共识规则。
让我们通过一个特定例子来检查下硬分叉的机制。
下图显示区块链出现两个分叉。在区块高度4处,发生单一区块分叉。这是我们在“区块链分叉”一节中看到的自发分叉的类型。经过区块5的挖掘,网络在一条链上重新收敛,分叉被解决。
然而,后来在区块高度6处发生了硬分叉。我们假设原因是新共识规则的变化出现新的客户端版本。从区块高度7开始,矿工运行新的版本,需要接受新类型的数字签名,我们称之为“Smores”签名,它不是基于ECDSA的签名。紧接着,运行新版本的节点创建了一笔包含Smores签名的交易,一个更新了软件的矿工挖出了包含此交易的区块7b。
任何尚未升级验证Smores签名的软件的节点或矿工现在都无法处理区块7b。从他们的角度来看,包含Smores签名的交易和包含该交易的区块7b都是无效的,因为它们是根据旧的共识规则进行评估的。这些节点将拒绝该笔交易和区块,并且不会传播它们。正在使用旧规则的任何矿工都不接受区块7b,并且将继续挖掘其父区块6的候选区块。实际上,如果遵守旧规则的矿工连接的所有节点都遵守旧的规则,那么他们甚至可能接收不到区块7b,因此也不会传播这个区块。最终,他们将会开采区块7a,这个在旧规则是有效的,其中不包含使用Smores签名的任何交易。
这两个链条从这一点继续分裂。“b”链的矿工将继续接受并开采含有Smores签名的交易,而“a”链上的矿工将继续忽视这些交易。即使区块8b不包含任何Smores签名的交易,“a”链上的矿工也无法处理。对他们来说,它似乎是一个孤立的区块,因为它的父区块“7b”不被识别为一个有效的区块。
(2)硬分叉:软件、网络、挖矿和链
对于软件开发人员来说,术语“分叉”具有另一个含义,对“硬分叉”一词增加了混淆。在开源软件中,当一组开发人员选择遵循不同的软件路线图并启动开源项目的竞争实施时,会发生分叉。我们已经讨论了导致硬分叉的两种情况:
- 共识规则中的错误
- 对共识规则的故意修改
在故意改变共识规则的情况下,软件分叉要比硬分叉先发生。但是对于这种类型的硬分叉,新的共识规则必须通过开发、采用和启动新的软件实现。
试图改变共识规则的软件分叉的例子包括Bitcoin XT,Bitcoin Classic和最近的BitcoinUnlimited。但是,这些软件分叉都没有产生硬分叉。虽然软件分叉是一个必要的前提条件,但它本身不足以发生硬分叉。硬分叉发生必须是由于采取相互竞争的实施方案,并且规则需要由矿工、钱包和中间节点激活。相反,有许多比特币核心的替代实现方案,甚至还有软件分叉,这些没有改变共识规则,只是去除错误,也可以在网络上共存并交互操作,最终并未导致硬分叉。
共识规则会在交易或区块的验证中表现出明确清晰的不同之处。比如共识规则适用于比特币脚本或加密原语(如数字签名)时,这种差别可能以微妙的方式表现。最后,共识规则的差别还可能会由于意料之外的方式,比如由于系统限制或实现细节所产生的隐含共识约束。在将Bitcoin Core 0.7升级到0.8时,从意料之外的硬分叉中看到了后者的一个例子,这是由于用于存储区块的Berkley DB实现的限制引起的。
从概念上讲,我们可以将硬分叉看成四个阶段:
- 软件分叉
- 网络分叉
- 挖矿分叉
- 区块链分叉
该过程开始于开发人员创建的客户端,这个客户端对共识规则进行了修改。
当这种新版本的客户端部署在网络中时,一定百分比的矿工、钱包用户和中间节点可以采用并运行该版本客户端。产生的分叉将取决于新的共识规则是否适用于区块、交易或系统其他方面。如果新的共识规则与交易有关,那么根据新规则创建交易的钱包可能会导致网络分叉,随后在交易被挖掘到区块中时发生硬分叉。如果新规则与区块有关,那么当一个区块根据新规则被挖掘时,硬分叉进程将开始。
首先是网络分叉。基于旧的共识规则的节点将拒绝根据新规则创建的任何交易和区块。此外,遵循旧的共识规则的节点将暂时禁止和断开与发送这些无效交易和区块的任何节点的联系。因此,网络将分为两部分:旧节点将只保留连接到旧节点,新节点只能连接到新节点。基于新规则的单个交易或区块将通过网络传播,结果是网络被分裂成了两个分区。
一旦使用新规则的矿工开采了一个块,挖矿能力和区块链也将分叉。新的矿工将在新区块之上挖掘,而老矿工将根据旧的规则挖掘一个单独的链条。分裂的网络使得按照各自共识规则运行的矿工不会接收彼此的块,因为它们连接到两个单独的网络。
(3)分离矿工和难度
随着分离的矿工们开始开采两条不同的链,链上的算力也被分裂。两个链之间的挖矿能力可以分成任意比例。新的规则可能只有少数矿工跟随,也可能是绝大多数矿工。
我们假设,例如按照80%和20%的比例分割,大多数挖矿算力使用新的共识规则。我们还假设分叉在重定目标(retarget)后立即出现。
这两条链将从重定目标之后各自接受自己的难度。新的共识规则得到了以前可用的挖矿权中80%部分的承诺。从这个链的角度来看,与上一周期相比,挖矿能力突然下降了20%。区块将会平均每12分钟发现一次,这意味着可以扩展这条链的挖矿能力下降了20%。这个区块发行速度将持续下去(除非有任何改变算力的因素出现),直到挖到第2016个区块,大约需要24,192分钟(每个区块需要12分钟)或16.8天。16.8天后,基于此链中算力的减少,重定目标将再次发生,并将难度调整(减少20%)到每10分钟产生一个区块。
少数人认可的那条链,根据旧规则继续挖矿,现在只有20%的散列算力,将面临更加艰巨的任务。在这条链上,平均每隔50分钟开采一次。这个难度将不会在2016个区块之前进行调整,这将需要100,800分钟,或大约10周的时间。假设每个区块具有固定容量,这也将导致交易容量减少5倍,因为每小时可用于记录交易的区块大幅减少了。
(4)有争议的硬分叉
这是共识软件开发的黎明。正如开源开发改变了软件的方法和产品,创造了新的方法论、新工具和新社区,共识软件开发也代表了计算机科学的新前沿。在比特币发展路线图的辩论、实验和困难中,我们将看到新的开发工具、实践、方法和社区的出现。
硬分叉被视为有风险,因为它们迫使少数人选择升级或是必须保留在少数派链条上。将整个系统分为两个竞争系统被许多人认为是不可接受的风险。结果,许多开发人员不愿使用硬分叉机制来实现对共识规则的升级,除非整个网络都能达成一致。任何没有被所有人支持的硬分叉建议也被认为是“有争议”的,否则有分裂系统风险。
硬分叉的问题在比特币开发社区也是非常有争议的,尤其是与控制区块大小限制的共识规则的任何相关提议。一些开发人员反对任何形式的硬分叉,认为它太冒险了。另一些人认为硬分叉机制是提升共识规则的重要工具,避免了“技术债务”,并与过去进行了一个干净的了断。最后,有些开发人员认为硬分叉应该作为一种很少使用的机制,只有经过认真的计划,并且在近乎一致的共识下才建议使用。
于是出现了新的方法论来解决硬分叉的危险。在下一节中,我们将看一下软分叉,以及BIP-34和BIP-9针对共识修改的信令和激活方法。
(5)软分叉
并非所有共识规则的变化都会导致硬分叉。只有向前不兼容的共识规则的变化才会导致分叉。如果共识规则的改变也能够让未修改的客户端仍然按照先前的规则对待交易或者区块,那么就可以在不进行分叉的情况下实现共识修改。
这就是软分叉用来区分之前的硬分叉。实际上软分叉不是分叉。软分叉是对共识规则的向前兼容的升级,允许未升级的客户端程序继续在新的共识规则下工作。
软分叉的一个不是很明显的方面就是,软分叉升级只能用于增加共识规则约束,而不能扩展它们。为了向前兼容,根据新规则创建的交易和区块也必须在旧规则下有效,但是反之亦然。新规则只能增加约束条件,如果放宽了约束条件,那么新规则所产生的区块(或者交易)在旧规则下可能是无效的,这还是会触发硬分叉。
软分叉可以通过多种方式实现,所谓软分叉并不特指某种单一的方法,而是很多种方法,它们都有一个共同点:它们不要求所有节点升级,或者强制非升级节点脱离共识。
1、软分叉重新定义NOP操作码
基于NOP操作码的重新解释,让比特币的一些软分叉得以实现。比特币脚本有10个操作码保留供将来使用,NOP1到NOP10。根据共识规则,这些操作码在脚本中的存在被解释为不起作用的运算符,这意味着它们不会产生任何影响。在NOP操作码之后继续执行,就好像它不存在一样。
因此,软分叉可以修改NOP代码的语义给它新的含义。例如,BIP-65(CHECKLOC-KTIMEVERIFY)重新解释了NOP2操作码。实施BIP-65的客户端将NOP2解释为OP_CHECKLOCKTIMEVERIFY,这是一条新的共识规则,其要求在锁定脚本里包含该操作码的UTXO中,添加绝对锁定时间。这种变化是一个软分叉,因为在BIP-65下有效的交易在任何没有实现(不识别)BIP-65的客户端上也是有效的。对于旧的客户端,该脚本包含一个NOP代码,这被忽略。
2、其他方式软分叉升级
NOP操作码的重新解释是意料之中的事情,它也是显而易见的用于共识升级的机制。然而最近引入了另一种软分叉机制,其不依赖于NOP操作码来进行特定类型的共识改变。
隔离见证是一个交易结构的体系架构变化,它将解锁脚本(见证)从交易内部移动到外部数据结构(将其隔离)。隔离见证最初被设想为硬分叉升级,因为它修改了一个基本的结构(交易)。在2015年11月,一位从事比特币核心工作的开发人员提出了一种机制,通过这种机制,可以将隔离见证作为软分叉引入。此机制是在隔离见证规则下对于UTXO的锁定脚本的修正,使得未升级的客户端将锁定脚本视为可用任何解锁脚本进行兑换。因此,可以不需要每个节点必须升级或从链中脱离就可以引入隔离见证:这就是软分叉。
有可能还有其他尚未被发现的机制,通过这种机制可以用向前兼容的方式作为软分叉进行升级。
(6)对软分叉的批评
基于NOP操作码的软分叉是相对无争议的。NOP操作码被放置在比特币脚本中,明确的目标是减少升级中的混乱。
然而,许多开发人员担心软分叉升级的其他方法会产生不可接受的折中。对软分叉更改的常见批评包括:
- 技术性债务。由于软分叉在技术上比硬分叉升级更复杂,所以引入了技术性债务,这是指由于过去的设计权衡而增加未来代码维护的成本。代码复杂性又增加了错误和安全漏洞的可能性。
- 验证放松。未经修改的客户端将交易视为有效,而不根据已经变更的共识规则对交易进行评估。实际上,未经修改的客户端不会使用全面的共识规则来验证,因为它们对新规则视而不见。这适用于基于NOP的升级,以及其他软分叉升级。
- 不可逆转升级。因为软分叉产生额外的共识约束的交易,所以它们在实践中成为不可逆转的升级。如果软分叉升级在激活后被回退,那么任何根据新规则创建的交易都可能导致在旧规则下的资金损失。例如,如果根据旧规则对CLTV交易进行评估,则不存在任何时间锁定约束,并且可以随时花费。因此批评人士认为,由于错误而不得不回退的失败的软分叉几乎肯定会导致资金的流失。
使用区块版本发出区块软分叉信令
由于软分叉允许未经修改的客户在共识内运作,软分叉的“激活”是基于矿工发出的准备信号:大多数矿工必须同意,准备并愿意执行新的共识规则。为了协调他们的行动,有一个信令机制,使他们能够表达对共识规则改变的支持。该机制是在2013年3月激活BIP-34后引入的,并在2016年7月被BIP-9激活取代。
共识软件开发
共识软件开发不断发展,对于改变共识规则的各种机制进行了很多讨论。就其本质而言,比特币在协调和共识变化方面树立了非常高的标杆。作为一个去中心化的系统,不存在凌驾于网络参与者之上的“权威”。权力分散在多个支持者,如矿工、核心开发者、钱包开发者、交易所、商家和最终用户之间。这些支持者不能单方面做出决定。
例如,尽管矿工在理论上可以使用过半数(51%)来改变规则,但受到其他支持者准许的限制。如果他们单方面行事,其他参与者可能会拒绝遵从,将经济活动保持在少数链上。没有经济活动(交易、商人、钱包、交易所),矿工们将用空的区块开采一个毫无价值的货币。这种权力的扩散意味着所有参与者必须协作,否则任何改变都不能实现。这个系统的现状是稳定的,只有大多数人在很大程度上达成一致的情况下,才会有一些变化的可能。软分叉中的95%阈值就反映了这一现实。
重要的是要认识到,对于共识发展没有完美的解决办法。硬分叉和软分叉都涉及权衡。对于某些类型的更改,软分叉可能是一个更好的选择;对于另外一些情况,硬分叉又可能是一个更好的选择。没有完美的选择,它们都带有风险。共识软件开发的一个不变特征是变革是困难的,共识促成了妥协。
有些人认为这是共识制度的弱点。总有一天,你会像我一样把它当作这个系统最大的优势。
八、比特币的安全
保障比特币的安全很有挑战性,因为比特币不是像银行账户的资产负债表一样的一个抽象价值引用。比特币本身非常像数字现金或者黄金。你可能已经听过这样的表达:“所有权占到了法律的十分之九。”那么,在比特币中,所有权是规则的全部。能够解锁比特币的密钥的所有权就等于拥有现金或者一大块贵金属。你可能丢失它,错放它,被偷走或者不小心转给别人不正确的金额。在所有这些情况下,用户都没有办法追索,就好像他们在公共人行道上丢了钱一样。
但是比特币有现金、黄金和银行账户所不具有的能力。一个包含你密钥的比特币钱包,可以像任何文件一样被备份。它可以有多个副本,甚至打印到纸上作为硬副本。你没有办法“备份”现金、黄金或者银行账户。比特币和之前的任何东西都不同,我们需要以一种新颖的方法来思考比特币安全。
安全原则
比特币的核心原则是去中心化,这对安全性有重要的影响。像传统银行或者支付网络一样的中心化模型依赖于访问控制和审批来将坏人挡在系统之外。相比之下,像比特币这样的去中心化系统将这种责任和控制推给了用户。因为网络的安全性基于工作量证明而非访问控制,网络可以是开放的,比特币传输不需要加密。
在一个像信用卡系统这样的传统支付网络中,支付是终端开放的,因为它包含了用户的个人标识(信用卡号)。在初次支付之后,任何可以访问该标识的人都可以从所有者那里反复“抽取”资金。这样,支付网络必须通过加密对端到端进行安全保护,并且必须确保没有窃听者或者中间人能够危害到支付通信,无论是传输过程中还是被保存后(休息时)。如果一个坏人获得了系统访问权限,他可以危害到当前的交易和支付令牌,并用它们来创建新的交易。更糟糕的是,当客户数据被泄露,客户的个人身份信息被暴露给身份窃贼,必须采取行动来防止失窃账户被用于欺诈。
比特币则截然不同。一笔比特币交易仅仅授权一个特定的值到一个特定的接收方,并且不能够被伪造或者修改。它没有泄露任何像当事人身份的隐私信息,也不能被用于授权额外的支付。因此,一个比特币支付网络不需要被加密或者防止窃听。实际上,你可以通过开放的公共频道(像不安全的WiFi或者蓝牙)广播比特币交易,同时不会降低安全性。
比特币的去中心化安全模型把很大的权力交到了用户的手中。随着权力而来的是保管好安全密钥的责任。对大多数用户来说这并不容易,特别是在使用能时刻连接在互联网上的智能手机或者笔记本电脑这种通用计算设备时。尽管比特币的去中心化模型避免了常见的信用卡盗用的问题,但是很多用户没能安全地保管好他们的密钥,并一个接一个地被黑客入侵。
(1)安全地开发比特币系统
比特币开发者的最重要原则是去中心化。大多数开发者对中心化安全模型都是熟悉的,可能会试着把这些模型应用到他们的比特币应用中,这会造成惨重后果。
比特币的安全依赖于通过密钥的去中心化控制,以及来自矿工的独立交易验证。如果你想要利用比特币的安全性,你需要保证你始终在比特币的安全模型内。简单地说,不要从用户那里拿走对密钥的控制,也不要把交易放到链下。
举个例子,许多早期的比特币交易所把所有的用户资金放到一个“热”钱包里,它的密钥保存在一个单点的服务器上。这样的设计夺走了用户的控制权,并且把对密钥的控制集中在一个单一系统。许多这样的系统都已经被入侵过,给它们的客户带来了惨重后果。
另一个常见的错误是接受“离链”交易,这种情况出自一种错误的引导,为了降低交易费用或者加速交易处理。一个“离链”交易系统会把交易记录到一个内部的中心化账本,然后偶尔把它们同步到比特币区块链上去。再强调一下,这种做法用一种专有和中心化的方式替换了去中心化的比特币安全模型。当交易是“离链”的,保护不当的中心化账本可能在没被注意到的情况下被伪造、转移资金、消耗储备金。
除非你准备在运营安全、多层访问控制和审计上做大量投资(像传统银行做的那样),否则在把资金从比特币的去中心化环境中拿走之前你需要慎重考虑。哪怕你有足够资金和几率来实现一个健壮的安全模型,这种设计仅仅是复制了传统金融网络的脆弱模型,其一直被身份盗用、腐败和贪污所困扰。为了利用比特币独一无二的去中心化安全模型,你必须抵制使用熟悉的中心化体系架构的诱惑,因为它最终会颠覆比特币的安全性。
(2)信任根
传统的安全体系架构是基于信任根的,它是一个被作为整个系统或者应用安全基础的受信核心。安全体系架构围绕着信任根发展,形成一系列同心圆,就像洋葱的层次一样把信任从中心向外扩展。每一层都基于更受信任的内层构建,使用访问控制、数字签名、加密和其他安全基元。随着软件系统变得更加复杂,它们也更可能包含缺陷,使得它们更脆弱、更容易受到安全威胁。软件系统越复杂,它的安全越难保证。
信任根的概念保证了最大的信任被放到系统最简单从而也是最坚固的部分,更复杂的系统则堆建在它之上。安全体系架构在不同的规模上重复,首先在一个单一系统的硬件里建立一个信任根,然后该信任根通过操作系统扩展到更高层的系统服务,最终到以同心圆方式层叠但信任递减的众多服务器上。
比特币的安全体系架构是不一样的。在比特币中,共识系统创建了一个完全去中心化的受信的公共账本。一个正确被验证的区块链使用创世区块作为信任根,构建一个直到当前块的信任链条。比特币系统可以也应该使用区块链作为它们的信任根。当设计一个复杂的、包含多个运行在不同系统上的服务的区块链应用时,你应该仔细检查安全架构以确定信任的位置。最终唯一应该明确信任的是完全验证的区块链。如果你的应用显式地或者隐式地将信任赋予区块连之外的东西,那应该引起关注,因为这会引入漏洞。
评估你的应用安全架构的一个好办法是分别考虑每一个模块,评估一个假设的场景——该模块被彻底攻陷,处于恶意行为者控制之下。依次考察你应用的每个模块,评估模块被危害时对整体安全性的影响。如果当模块被危害时你的应用不再安全,那就表示你把信任错误地放在了那些模块中。一个没有漏洞的比特币应用程序应该只会在比特币共识机制受损时出现漏洞,这意味着它的信任根位于比特币安全架构中最强大的部分。
被黑客入侵的比特币交易所的众多例子有助于强调这一点,因为即使在最偶然的审查下,其安全架构和设计也会失败。这些中心化的实现明确地把信任投资在比特币区块链之外的众多模块上,比如热钱包、中心化账本数据库、易受攻击的加密密钥和其他的类似方案。
用户安全最佳实践
人类使用物理安全控制已经有几千年。作为对比,我们使用数字安全的经验还不到50年。现代通用操作系统并不十分安全,也没有为保存数字货币特别适配过。我们的电脑通过始终在线的互联网连接始终处于外部威胁之下。它们运行来自数以百计作者的数以千计的软件模块,通常都具有对用户文件的无线访问。在你的计算机上安装的数以千计的软件中只要有一个流氓软件,它就能攻陷你的键盘和文件,窃取存储在钱包应用程序中的所有比特币。维护计算机无病毒、无木马所需要的技能水平,超过了除极小一群电脑用户之外所有人的技能水平。
尽管信息安全已经有几十年的研究和发展,数字资产对于顽固的敌人来说仍然是脆弱不堪的。哪怕是受到最高级别保护和限制的系统,如金融服务公司、情报机构和国防承包商,也常常被攻陷。比特币创造了有着内在价值的数字资产,可以被偷走,并且马上不可撤销地转移到新的所有者。这给黑客创造了一个巨大的激励。到目前为止,黑客在入侵之后仍然需要将身份信息或者账号令牌(比如说信用卡和银行账号)转换成价值。尽管保护和清洗金融信息很困难,但我们发现盗窃案日渐增多。比特币加剧了这个问题,因为它不需要被围起来或者被清洗;它是数字资产的内在价值。
幸运的是,比特币也创造了提升电脑安全的动机。之前电脑被入侵的风险是模糊而间接的,比特币让这些风险清晰明了。在一台电脑上存放比特币有助于将用户的注意力集中在提高计算机安全性的需求上。作为比特币和其他数字货币的激增和使用的直接结果,我们同时看到了黑客技术和安全解决方案的升级。简单来说,黑客现在有了一个非常有油水的目标,而用户有了明确的动机来保护自己。
在过去的三年中,作为比特币使用的一个直接结果,我们看到了硬件加密、密钥存储和硬件钱包、多重签名技术和数字托管等形式在信息安全领域的巨大创新。
(1)比特币物理存储
相比于信息安全,大部分用户对物理安全更适应,所以一个非常有效的保护比特币的方法是把它们转换到物理形态。比特币密钥就是一长串数字而已。这意味着它们可以以物理的形态存储,比如打印到纸上或者蚀刻到金属硬币上。这样保护密钥安全就简单地变成了物理上保护打印出来的比特币密钥。
一组被打印到纸上的比特币密钥称为“纸钱包”,有很多免费的工具可以用来创建它们。我个人把绝大部分比特币(99%或者以上)保存在纸钱包上,以BIP-38加密,复制了多份锁在安全的地方。离线保管比特币叫作冷存储,它是最有效的安全技术之一。冷存储系统是密钥在一个离线系统(一个从来不联网的系统)生成,并离线保存在纸上或者像USB存储棒这样的数字媒介上。
(2)硬件钱包
长期来说,比特币安全越来越多地采取硬件防篡改钱包的形式。不像一台智能手机或者台式机,比特币硬件钱包只有一个目的:安全保管比特币。没有通用软件带来危害并且接口有限,硬件钱包可以为非专业用户提供几乎万无一失的安全级别。我期望看到硬件钱包成为比特币存储的主要方法。有关此类硬件钱包的示例,请参阅Trezor(https://trezor.io/)。
(3)平衡风险
尽管大多数用户对比特币失窃有正确的关注,但存在的风险更大。数据文件一直在丢失。如果丢失的文件中包含比特币,损失会更加严重。为了保证比特币钱包的安全,用户必须非常小心,不要过度保护而最终丢失比特币。2011年7月,一个著名的比特币宣传和教育项目丢失了将近7000个比特币。为了防止失窃,持有者们实施了一系列复杂的加密备份。最后他们意外丢掉了加密密钥,使得备份毫无价值并且丢失了一大笔财富。就好像把钱藏到了沙漠里,如果你保护比特币的方式太过了,你可能再也没法找到它。
(4)分散风险
你会把你的全部身家都以现金的形式放在你的钱包吗?大多数人会认为这样很鲁莽,但比特币用户经常把所有的比特币放在一个钱包里。相反,用户应该将风险分散到多种比特币钱包中。谨慎的用户仅将一小部分比特币(可能不到5%)放在一个在线或移动钱包中作为“随身零钱”。其余应该分成几种不同的存储机制存放,如桌面钱包和离线钱包(冷钱包)。
(5)多重签名和治理
每当公司或个人存储大量比特币时,他们应该考虑使用一个多重签名的比特币地址。多重签名地址通过在支付时要求多于一个签名来保护资金安全。签名密钥应当被保存在由不同人员控制的若干个不同位置。例如在公司环境中,密钥应该由多个公司管理人员独立生成并保管,以确保任何人都不能损害资金。多重签名地址也可以提供冗余,即一个人拥有多个存储在不同位置的密钥。
(6)生存能力
一个常常被忽略的安全考虑是可用性,特别是在密钥持有人无行为能力或死亡的情况下。比特币的用户被告知使用复杂密码并保证他们的密钥安全且隐秘,不与任何人分享。不幸的是,当这个用户无法解锁它们的时候,这个做法也让用户的家庭几乎不可能恢复任何资金。实际上,大多数情况下,比特币用户的家人可能完全不知道这笔比特币资金的存在。
如果你有很多比特币,你应该考虑和一个你信任的亲戚或者律师分享访问细节。你也可以通过专门作为“数字资产执行者”的律师,或通过多重签名访问和遗产规划设立更复杂的比特币生存能力方案。
九、比特币应用
现在,让我们从将比特币作为应用平台的角度来进一步加深理解。很多人使用“区块链”(blockchain)这个词来表示任何共享比特币设计原则的应用平台。该术语经常被滥用,并被应用于许多比特币区块链主要功能不能提供的事情上。
在本章中,我们将介绍比特币区块链作为应用平台所提供的功能。我们将考虑应用程序构建要素,即构成任何区块链应用程序的基础模块。我们将研究使用这些构建要素的几个重要应用程序,如染色币、付款(状态)通道和路由支付通道(闪电网络)。
简介
比特币系统被设计为一个分布式的货币及支付系统。然而,它的大部分功能源于可用于更广泛应用中的更底层的结构。比特币不是由诸如账户、用户、余额和付款等组件构建的。相反,它使用的是更底层的有加密功能的交易脚本语言。就像账户、余额和付款的更高层次的概念可以从基本要素中衍生出来一样,许多其他复杂的应用也是如此。因此,比特币区块链可以成为一个提供可信服务的应用平台(诸如智能合同等应用程序),远远超出了作为数字货币和支付的原始目的。
基础模块(要素)
为了应用程序能正常且长期运行,比特币系统提供了一系列的保证,可以作为基础模块来创建应用程序。这些包括:
- 杜绝双重支出/杜绝双重授权。比特币分布式共识算法的最基础的保证是确保UTXO不会被花费两次。
- 不可篡改性。一旦交易被记录在区块中,并且随后添加了足够多的区块,交易数据就变得不可篡改。不可篡改性是由算力进行保证的,因为重写区块链需要消耗很多算力才能产生工作量证明。所需的算力以及由此带来的不可变性的程度随着在包含交易的区块之后被提交的区块数量而增加。
- 中立。去中心化的比特币网络传播有效的交易,而不管这些交易的来源或内容如何。这意味着任何人都可以支付足够多的费用来创建有效的交易,并确信他们可以随时传输该交易并使其包含在区块链中。
- 安全时间戳。共识规则拒绝任何时间戳距离现在太远(过去和将来)的块。这可以确保块上的时间戳可以被信任。块上的时间戳意味着对所有交易包含的输入是未使用的保证。
- 授权。数字签名通过去中心化网络进行验证后,可提供授权担保。包含对数字签名要求的锁定脚本不能在未经脚本中隐含的私钥持有者授权的情况下执行。
- 可审计性。所有交易都是公开的,可以被审计。所有的交易和区块都以一个不间断的区块链链接到创世区块。
- 可核算。在任何交易中(coinbase交易除外),输入的金额等于输出的金额加上交易费用。在交易中不可能创建或销毁比特币。输出不能超过输入。
- 永不过期。有效的交易永远不会过期。如果今天有效,它将在不久的将来仍然有效,只要输入仍然没有被花费且共识规则没有改变。
- 公正性。由SIGHASH_ALL签名或者部分由SIGHASH类型签名的比特币交易,不能在签名还有效的情况下被修改,从而导致交易本身无效。
- 交易原子性。比特币交易是原子性的。它们要么是有效并且经过确认的(被打包挖矿过),要么不是。不存在确认交易的一部分,交易也不存在中间状态。在任何时间点,交易要么被打包挖矿,要么没有被打包挖矿。
- 面值固定(不可分割)。交易输出是固定面值和不可分割的价值单位。它们要么整体被花费,要么整体没有花费,不能被分割或者部分被花费。
- 法定人数。脚本中的多重签名强制了授权的法定人数(让任何预定事物有效的最低参与人数)在方案中是预先定义的。共识规则要求M-of-N必须如此执行。
- 时间锁/成熟。包含相对或绝对时间锁的任何脚本语句只能在其时间超过指定时间后执行。
- 复制性。区块链的去中心化存储确保交易在被开采(矿工打包到区块链)之后,经过充分的确认,会被复制到整个网络上,变成持久化存储,不受部分网络断电、数据丢失等的影响。
- 防伪保护。每笔交易只能花费现有经过验证的输出。不可能凭空创建或伪造比特币。
- 一致性。在没有矿工分叉的情况下,区块的深度越深,记录在区块链中的块可能会被重新分叉或者被不认可的可能性将呈指数级下降。一旦被记录在深层,改变所需的算力和能量将大到不可行的程度。
- 可记录外部状态。每个交易可以通过OP_RETURN提交一个数据,来表示外部系统的状态改变。
- 可预测发行量。总计不到2100万比特币将会以可预测的速度发行。
上述基础模块的列表并不完整,还会有新功能添加到比特币中。
源于基础模块的应用
由比特币提供的基础模块是可信平台的组成部分,可用于构成各种应用程序。以下是今天在用的应用程序及其使用的基础模块的一些示例。
- 数字公证——Proof-of-Existence(Digital Notary)。不可篡改性+时间戳+持久性。数字指纹可以通过一个交易提交给区块链,以证明文件在此存档的时间内是存在的(安全时间戳)。数字指纹不能在事后修改(不可篡改性),证据将被永久存储(持久性)。
- 众筹——Kickstarter(Lighthouse)。一致性+原子性+公正性。如果你给发起众筹活动的交易签名了一个输入和输出(公正性),别人可以参与众筹,但在目标(输出值)完成之前(一致性),这笔钱不能被花费出去(原子性)。
- 支付通道。法定人数+时间锁+杜绝双重支出+永不过期+可审计性+授权。一个带有时间锁(Timelock)的法定人数为2-2的(Quorum)多重签名被作为支付通道的“结算”交易时,可以被持有(Nonexpiration)或者可以在任何时间由任何一方授权(Authorization)的情况下(Censorship Resistance)进行花费。然后双方可以在更短的时间锁(Timelock)创建双重支出(No Double-Spend)结算的确认交易。
染色币
我们将讨论的第一个区块链应用是染色币(Colored Coins)。
染色币是指利用比特币交易来记录除比特币之外的外部资产以及外部资产的创建、所有权确认和转让的这类技术。
所谓“外部资产”,是指这些资产不直接存储在比特币区块上,与比特币本身不同,因为比特币本身就是区块链上的固有资产。
染色币用于跟踪第三方持有的数字资产和实物资产,并通过染色币所有权证书来进行交易。数字资产的染色币可以代表无形资产,如股票证书、许可证、虚拟财产(游戏装备)或大多数任何形式的在册知识产权(商标、版权等)。有形资产的染色币可以代表商品(黄金、白银、石油)、土地、汽车、船只、飞机等所有权。
该术语源于“着色”或标记某个面额的比特币的想法,例如,1聪用来表示比特币价值本身以外的东西。打个比方,我们给一美元的钞票标上一行信息说:“这是ACME的股票证书”,或者“这张钞票可以兑换1盎司的白银”,然后使用这个1美元钞票作为其他资产权益证明来进行交易。
染色币的第一个实施名为“基于订单的增强填充着色”(Enhanced Padded-Order-Based Coloring)或“EPOBC”,将外部资产标记于1聪输出上。这样,因为每个资产作为1聪输出的属性(颜色)被添加了,它就成了一个真正的“染色币”。
染色币的最新实施使用OP_RETURN脚本操作码将元数据存储在事务中,并将存储的元数据与特定资产关联的外部数据结合使用。
现今染色币的两个最主流的实现是Open Assets(http://www.openassets.org/)和Colu(http://coloredcoins.org)的染色币。这两个系统使用不同的协议来染色,并不兼容。在一个系统中创建的染色币在其他系统中无法识别或使用。
(1)使用染色币
必须使用特殊钱包去查看、创建或者转移染色币,这些钱包可以理解染色币协议元数据。必须特别注意避免在常规的比特币钱包中使用染色币相关的密钥,因为常规钱包可能会破坏元数据。同样地,染色币也不应该被发送到由常规钱包管理的地址,而只能发送到由染色币能够识别的钱包管理的地址。
Colu和Open Assets这两个系统都使用特殊的染色币地址来降低这种风险,并确保染色币不会发送到不能识别染色币的钱包。
染色币对大多数通用的区块链浏览器也是不可见的。相反,必须使用染色币浏览器来阐释染色币交易的元数据。
- Open Assets兼容的钱包应用程序和区块链浏览器可以在https://www.coinprism.info上查找。
- Colu染色币兼容的钱包应用程序和区块链浏览器可以在http://coloredcoins.org/explorer/上查找。
- Copay钱包插件可以在http://coloredcoins.org/colored-coins-copay-addon/上找到。
(2)发行染色币
每个染色币的实现都通过不同的方法创造染色币,但它们都提供类似的功能。创造染色币资产的过程称为“发行”。作为初始交易,发行交易将资产登记在比特币区块链上,并创建用于引用资产的资产ID。一旦发行,资产可以使用转账交易在地址之间转移。
作为染色币发行的资产可以有多种属性。它们可以是可分割的或不可分割的,这意味着转账中的资产量可以是整数(如5)或具有小数细分(如4.321)。资产也可以“固定发行”,意思是一定数量的资产只可以发行一次,或者可以被再次发行,后者意味着原始发行人在初始发行后可以发行新资产单位。
最后,一些染色币启用分红,即允许按照拥有权按比例分配比特币给染色币资产的所有者。
合约币
合约币(Counterparty)是在比特币之上建立的协议层。与染色币类似的合约币协议提供了创建和交易虚拟资产与代币的能力。此外,合约币提供了去中心化的资产交换。合约币还实现了基于Ethereum虚拟机(EVM)的智能合约。
像染色币协议一样,合约币使用OP_RETURN操作码或1-N多重签名的公钥地址将元数据嵌入到比特币交易中。使用这些机制,合约币实现了基于比特币交易编码之上的协议层。附加的协议层可以由能理解合约币的应用程序来解读,如相应的钱包和区块链浏览器,或使用合约币函数库构建的任何应用程序。
合约币可作为其他应用程序和服务的平台。例如,Tokenly是一个建立在合约币之上的平台,允许内容创作者、艺术家和公司发行表示数字所有权的代币,并可用于租赁、访问、交易,或购买内容、产品和服务。利用合约币的其他应用包括游戏(Spells of Genesis)和网格计算项目(Folding Coin)。
更多关于合约币的内容参见https://counterparty.io/。开源项目可以在https://github.com/CounterpartyXCP中找到。
支付通道和状态通道
支付通道是在比特币区块链之外双方之间交换的比特币交易的一种无须双方相互信任的机制。如果这些交易在比特币区块链上结算,则是有效的,然而它们却是在链外被持有的,以期票的形式等待最终批量结算。由于交易不需要打包入链,因此它们可以在没有通常的结算等待的情况下进行交换,从而可以满足极高的交易吞吐量,以及低延迟(亚毫秒)和高精细粒度(satoshi级)。
实际上,“通道”一词是一个比喻。状态通道是区块链外,由双方之间的交换状态所代表的虚拟结构。并没有实际上的“通道”,底层数据传输机制并不是通道。我们使用通道这个术语来表示链外双方之间的关系和共享状态。
为了进一步解释这个概念,想一想TCP流。从高层协议的角度来看,它是一个横跨互联网连接两个应用程序的“socket”。但是,如果查看网络流量,TCP流只是IP数据包之上的虚拟通道。TCP流的每个端点通过排序并组装IP数据包以产生字节流的错觉。实际上在背后,所有的数据包都是断开分散的。同理,支付通道也只是一系列交易。如果妥善排序和连接,即使你不信任通道的另一方,(经过排序连接后的交易)也可以创建可信任可兑现的交易。
在本节中,我们将介绍各种形式的支付通道。首先,我们将考察用于支持海量小额支付服务(如流媒体视频)的单行(单向)支付通道的机制。然后,我们将扩大这一机制,引入双向支付通道。最后,我们将看看首先在“闪电网络”中提出的,如何将路由网络中的双向通道端到端链接从而形成多跳通道。
支付通道是状态通道的引申概念之一,代表了链外状态的变化,通过区块链上的最终的结算得到保障。支付通道是一种状态通道,其中被改变的状态是虚拟货币余额。
(1)状态通道基本概念和术语
通过一个交易在区块链上所锁定的共享状态,在交易两方之间建立了一个状态通道。这称为资金交易或锚点交易。这笔交易必须传送到网络并被挖矿确认以建立通道。在支付通道的示例中,锁定的状态即为通道的初始余额(以货币计)。
随后双方交换已签名的交易,这称为承诺交易。这些承诺交易会改变初始的锁定状态。这些交易都是有效的,因为任何一方都可以提交结算到区块链上,但是会等到通道关闭时再做结算。通道状态在任何一方给对方创建、签名和发送交易时就会马上更新,这意味着实际上每秒可进行数千笔交易。
当交换承诺交易时,双方同时废止之前的状态,如此一来最新的承诺交易总是唯一可以兑换的承诺交易。这样可以防止任何一方在通道中某个先前状态比最新状态更有利于己方的时候通过单方面关闭通道来获利。我们将在本章的其余部分中研究可用于使先前状态无效的各种机制。
最后,可以通过合作方式关闭渠道,通过向区块链提交最终的结算交易,或者单方面提交最后的承诺交易到区块链。单方面能关闭通道选项是必要的,以防交易中的一方意外断开连接。结算交易代表通道的最终状态,并结算到区块链上。
在通道的整个生命周期中,只有两个交易需要提交到区块链上进行挖矿:资金交易和结算交易。在这两个状态之间,双方可以交换任何数量无须他人见证也无须提交到区块链上的承诺交易。
图12-4说明了Bob和Alice之间的支付通道,显示了资金、承诺和结算交易。
(2)简单支付通道示例
为了解释状态通道,我们必须从一个非常简单的例子开始。这里展示一个单向通道,意味着价值只向着一个方向流动。为了便于解释,我们以一个天真的假设开始,假设没有人试图欺骗他人。一旦解释了基本的通道概念,我们将会接着看看是什么使得支付通道可以不需要双方相互信任,从而让交易双方哪怕去尝试作弊都无法成功。
对于这个例子,我们假设有两个参与者:Emma和Fabian。Fabian提供由微支付通道支持以秒为单位时长计费的视频流服务。Fabian的视频每秒收费0.01毫比(millibits)(0.00001 BTC),相当于每小时视频需要36毫比(0.036 BTC)。Emma是从Fabian那里使用以秒计费的支付通道来购买流媒体视频服务的用户。
下图显示了Emma使用支付通道从Fabian处购买视频流服务。
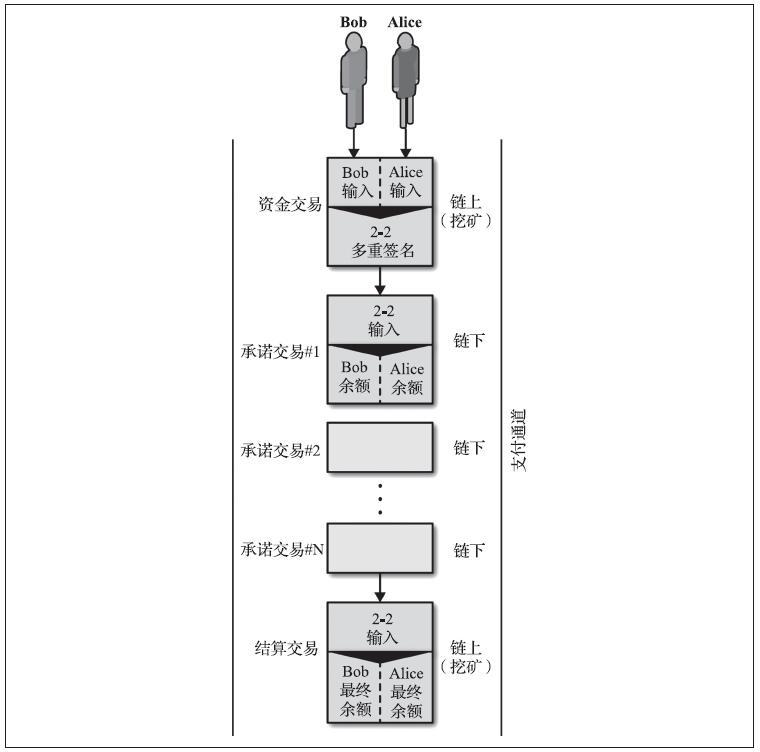
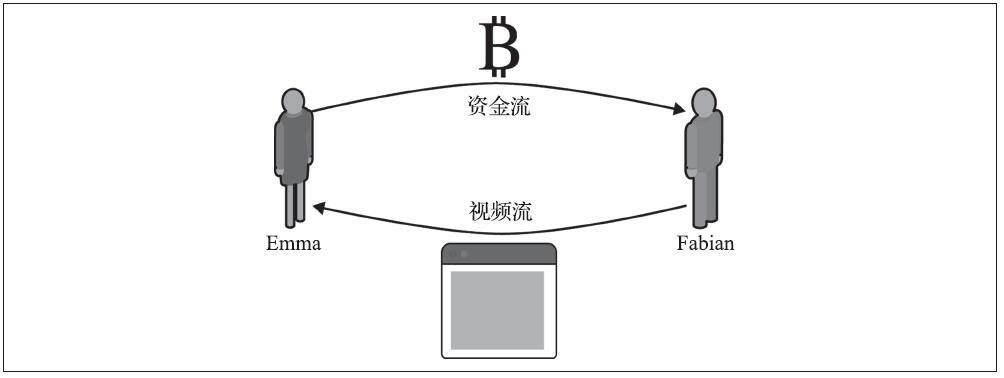
在这个例子中,Fabian和Emma正在使用的是专门的处理支付通道和视频流的软件。Emma在浏览器中运行该软件,Fabian从服务器端运行该软件。该软件包括基本的比特币钱包功能,可以创建和签署比特币交易。“支付通道”的概念和术语对于用户都是完全不可见的。他们看到的只是以秒为单位支付的视频。
为了设置支付通道,Emma和Fabian构建了一个2-2的多重签名地址,双方各持一个密钥。从Emma的角度来看,她的浏览器中的软件提供了一个带有P2SH地址的二维码(以“3”开头),并要求她提交了1小时视频的“押金”。该地址因而得到了Emma的注资。支付给该多重地址的Emma交易,就是支付通道的资金交易或锚点交易。
就这个例子而言,我们假设Emma支付了36个毫比(0.036 BTC)到通道中。这将允许Emma消费长达1小时的流媒体视频。这笔资金交易设定了可以在这个通道上发送的最大金额,即设置了通道容量。
资金交易从Emma的钱包中消耗一个或多个输入以集成资金。它创建一个价值为36毫比的输出,支付给Emma和Fabian之间共同控制的多重签名2-2地址。它也可能有另外一个作为找零到Emma钱包的输出。
一旦资金交易得到确认,Emma可以开始观看视频。Emma的软件创建并签署一笔承诺交易,改变通道余额,将0.01毫比归入Fabian的地址,并退回Emma的35.99毫比。Emma签署的交易消耗了由资金交易创造的36毫比输出,并创建了两个输出:一个用于找钱,另一个用于给Fabian付款。此时交易只是部分被签署了,它需要两个签名(2-2),但只有Emma的签名。当Fabian的服务器接收到此交易时,它会添加第二个签名(用于2-2输入),将其返回给Emma并附带时长1秒的视频。现在双方都有谁都可以兑换的完全签署的承诺交易,这个承诺交易代表着通道中的最新正确的余额。此时双方都不会将此交易广播到网络中。
在下一轮中,Emma的软件创建并签署另一个承诺交易(承诺2号),该交易从资金交易中消耗相同的2-2输出。2号承诺交易分配一个0.2毫比的输出到Fabian的地址,还有一个输出为35.98毫比,作为找零返回给Emma的地址。这个新交易支付的是连续两秒的视频内容。Fabian的软件签署并返回第二个承诺交易,再加上视频的另一秒内容。
利用上述方法,Emma的软件继续向Fabian的服务器发送承诺交易,以换取流媒体视频。因为Emma观看了更多秒数的视频,通道中属于Fabian的钱逐渐累积变多。假设Emma观看600秒(10分钟)的视频,创建和签署600笔承诺交易。最后的承诺交易(#600)将有两个输出,将通道的余额分成两部分,分别为6毫比属于Fabian和30毫比属于Emma。
最后,Emma点击“停止”停止流媒体视频。Fabian或Emma现在可以发送最终状态交易以进行结算。最后一笔交易即为结算交易,向Fabian支付所有Emma观看视频的费用,并向Emma退还资金交易中剩余的资金。
下图显示了Emma和Fabian之间的通道以及更新通道余额的承诺交易。
最后,只有两个交易记录在块上:建立通道的资金交易和在两个参与者之间正确分配最终余额的结算交易。
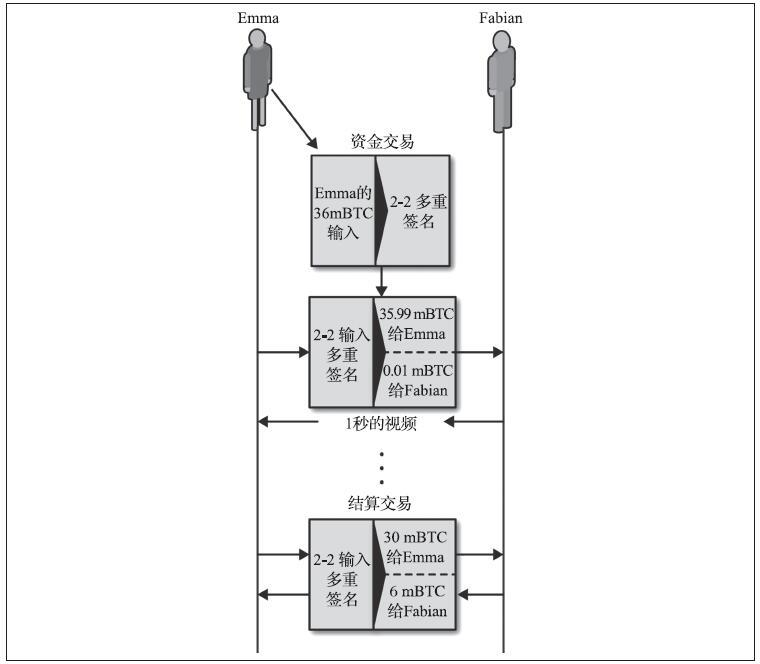
本质上,状态通道是通过链外系统,将多笔零碎的交易进行了cache,而只保留开始和结束的2笔链上比特币交易,通过这种方式完美解决了比特币网络的交易处理瓶颈以及共识安全性问题。
(3)制造无须信任的通道
我们刚刚描述的通道只有在双方合作,没有任何交易失败或企图作弊的情况下工作。我们来看看破坏这个通道的一些情况,并且看看需要什么来修复这类问题。
- 一旦资金交易发生,Emma需要Fabian的签名才能获得给自己的找零。如果Fabian消失不见了,Emma的资金将被锁定在2-2中,并彻底丢失。这个通道一旦建立,如果在双方共同签署至少一个承诺交易之前,有任何一方断开,就会导致资金的丢失。
- 当通道正在运行时,Emma可以利用Fabian已经签署的任何承诺交易,并将它发回链上。比如她可以发送承诺交易#1,只支付1秒的视频,为什么还要支付600秒的视频费用呢?通道失败是因为Emma可以通过广播对她比较有利的先前的承诺来作弊。
这两个问题都可以用时间锁来解决。我们来看看如何使用交易级别的时间锁(nLocktime)。
除非Emma有找零退款的保证,否则她不能冒险进行2-2签名。为了解决这个问题,Emma同时建立了资金和退款交易。她签署资金交易,但不传送给任何人。Emma只将退款交易传送给Fabian,并获得他的签名。
退款交易作为第一承诺交易,其时间锁确立了通道生命的上限。在这种情况下,Emma可以将nLocktime设置为30天或将来的第4320个区块。所有后续承诺交易必须具有较短的时间锁,以便在退款交易之前能兑换它们。
现在,Emma已经有一个完全签名的退款交易,她可以自信地发送签名过的资金交易,因为她知道她最终可以在时间到期后兑换退款交易,即使Fabian消失也不会有问题。
在通道生命中双方交换的每一项承诺交易都会被时间锁锁进未来的时间点。但是对于每个新产生的承诺交易,锁定时间会稍短一点,所以最新的承诺可以在它被前一承诺废止之前兑换。由于有了nLocktime,任何一方都只有等到时间锁到期后才能成功传播任何承诺交易。如果一切顺利,他们将合作并通过结算交易合理地关闭通道,这样一来发送中间的承诺交易就不必要了。实质上说,承诺交易只在一方断线而另一方不得不单方面关闭通道时才使用。
例如,如果承诺交易#1被时间锁定到将来的第4320个块,则承诺交易#2被时间锁定到将来的第4319个块。承诺交易#600则可以在承诺交易#1变为有效之前600个块的时间被兑换。
下图显示后续承诺交易设置较短的时间锁,允许它在之前的承诺变为有效前被花费。
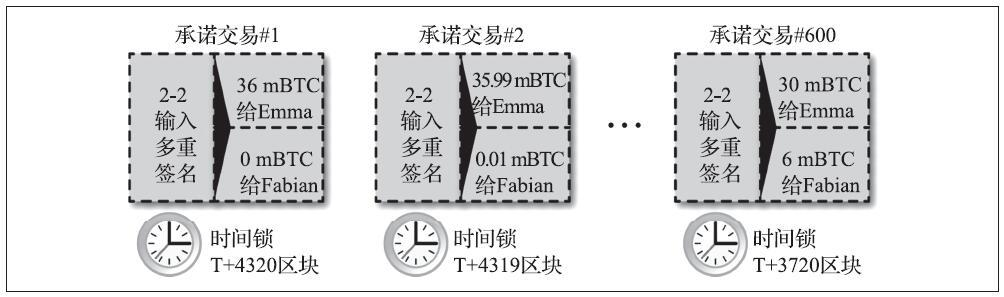
每个后续承诺交易必须具有较短的时间锁,以便可以在其前任之前和退款交易之前进行广播。能够尽早广播承诺交易的能力确保了承诺交易能够花费资金输出,并阻止任何其他承诺交易通过兑换资金输出来进行花费。比特币区块链技术提供了保证,即防止双重支出和执行时间锁,保障每个后续承诺交易可以使前任承诺交易失效。
状态通道使用时间锁来执行有时间维度的智能合约。在这个例子中,我们看到时间维度如何保证最近的承诺交易可以在任何早先的承诺生效之前变得有效。因此最近的承诺交易可以传输,消费输入和使先前的承诺交易无效。绝对时间锁定的智能合同的执行可以防止其中任何一方作弊。此实现只需要交易级别的绝对时间锁(nLocktime)。
接下来,我们将看到如何使用脚本级时间锁定CHECKLOCKTIMEVERIFY和CHECKSEQU-ENCEVERIFY来构建更灵活、有用和复杂的状态通道。
在2015年由阿根廷开发者团队演示的一个视频流应用demo中第一次出现了单向支付通道。你仍然可以在streamsium.io看到它。
时间锁并不是使先前的承诺交易无效的唯一方法。在接下来的章节中,我们将看到如何使用撤销密钥来实现相同的结果。时间锁是有效的,但其有两个明显的缺点。
- 第一个问题是,在通道首次打开时建立最大时间锁,限制了通道的使用寿命。更糟糕的是,他们迫使通道的实现在两者间实现平衡,既要允许长期存在的通道,同时在通道提前关闭的情况下,强制其中一个参与者等待非常长的时间才能获得退款。例如,如果允许通道保持开放30天,若将退款时间锁设置为30天,如果其中一方立即消失,则另一方必须等待30天才能退款。通道时效设置得越远,退款时间越长。
- 第二个问题是,由于每个后续的承诺交易必须减短时间锁,所以在双方之间可以交换的承诺交易数量有明确的限制。例如,一个30天的通道,设置了位于未来第4320个块的时间锁,只能容纳4320个中间承诺交易,在这之后必须关闭。将承诺交易时间锁的间隔设置为1个区块存在危险。通过将承诺交易之间的时间锁间隔设置为1个区块,通道开发者给通道参与者带来了非常大的负担,参与者必须时刻保持警惕,保持在线并实时监控,并随时准备传送正确的承诺交易。
现在我们了解如何使用时间锁来使先前的承诺无效,我们可以看到合作关闭通道和通过广播承诺交易单方面关闭通道之间的区别。所有承诺交易都是时间锁定的,因此广播承诺交易总是要等待时间到期。但是,如果双方就最终余额达成一致并知道他们都持有的承诺交易可最终实现这一平衡,那么他们可以构建一个没有时间锁代表相同余额的结算交易。
在合作关闭中,任意一方都可以提取最近的承诺交易,并构建一个各方面完全相同的结算交易,唯一差别就是结算交易省略了时间锁。双方都可以签署这笔结算交易,因为知道无法通过作弊以得到更多的余额。通过合作签名和发送结算交易,可以立即关闭通道并兑换余额。最差的情况下,当事人之一可能是卑鄙小人,拒绝合作,强迫另一方单方面关闭最近的承诺交易。但是如果他们这样做,他们也必须等待才能解锁资金。
(4)非对称可撤销承诺
处理先前承诺状态的更好方法是明确撤销它们。但是,这不容易实现。比特币的一个关键特征是,一旦交易有效,它会一直有效,不会过期。取消交易的唯一方法是在交易被挖矿前用另一笔交易双重支出它的输入。这就是为什么我们在上述简单支付通道示例中使用时间锁定,以确保最新的承诺交易可以在旧承诺生效之前被花费。然而,把承诺按时间排序造成了许多限制,使得支付通道难以使用。
虽说一个交易无法取消,但是它可以被构造成无法再使用的样子。我们实现它的方法是通过给予每一方一个撤销密钥,如果对方试图欺骗,可以用来惩罚对方。可撤销先前承诺交易的这种机制首先作为闪电网络的一部分被提出。
为了解释可撤销密钥,我们将在由Hitesh和Irene经营的两个交易所之间构建一个更加复杂的支付通道。Hitesh和Irene分别在印度和美国运营比特币交易所。Hitesh的印度交易所的客户经常向Irene的美国交易所的客户发送比特币,反之亦然。目前,这些交易都发生在比特币区块链上,但这意味着支付手续费用并需要等待几个块进行交易确认。在交易所之间设置支付通道将大大降低成本并加快交易流程。
Hitesh和Irene通过合作构建资金交易来启动通道,每人向通道注资5个比特币。初始余额为Hitesh有5个比特币,Irene也有5个比特币。资金交易将通道状态锁定在2-2多重签名中,就像在简单通道的例子中一样。
资金交易可能有一个或多个来自Hitesh的输入(加起来5个比特币或更多),以及Irene的一个或多个输入(加起来5个比特币或更多)。输入必须略微超过通道容量才够支付交易费用。该交易有一个将总共10个比特币锁定到由Hitesh和Irene控制的2-2多重地址的输出。如果他们的输入超过需要贡献的数值,资金交易也可能有一个或多个输出将找零返回给Hitesh和Irene。这是由双方提供和签署的多个输入形成的单一交易。在发送之前,它必须被合作构建起来并且由各方签名。
现在,与双方签名每个承诺交易不同的是(在简单通道下如此运作),Hitesh和Irene创造了两个不对称的承诺交易。
- Hitesh有一个带有两个输出的承诺交易。第一个输出立即支付Irene 5个比特币。第二个输出支付Hitesh自己5个比特币,但是有个1000个区块的时间锁。交易输出如下所示:
- Input: 2-of-2 funding output, signed by Irene Output 0 <5 bitcoin>: <Irene's Public Key> CHECKSIGOutput 1: <1000 blocks> CHECKSEQUENCEVERIFY DROP <Hitesh's Public Key> CHECKSIG
- Irene有带有两个输出的不同的承诺交易。第一个输出支付Hitesh欠他的5个比特币。第二个输出是支付给Irene自己的5个比特币,但同样带有1000个区块的时间锁。Irene持有的承诺交易(由Hitesh签署)如下:
- Input: 2-of-2 funding output, signed by Hitesh Output 0<5 bitcoin>: <Hitesh's Public Key> CHECKSIGOutput 1: <1000 blocks> CHECKSEQUENCEVERIFY DROP <Hitesh's Public Key> CHECKSIG
这样一来,双方各有一笔承诺交易,可以花费2-2的资金输出。该承诺交易的输入是由对方签署的。在任何时候,持有承诺交易的一方都可以签字(完成2-2签名)交易并进行广播。然而,如果他们广播承诺交易,承诺交易会立即支付对方,而他们自己必须等待时间锁到期。通过在其中一个输出强制执行时间锁,我们可以做到让各方在选择单方面广播承诺交易时处于轻微的不利地位。但是单靠时间延迟还不足以鼓励公平的行为。
下图显示两个不对称承诺交易,其中承诺持有人的有延迟支付。
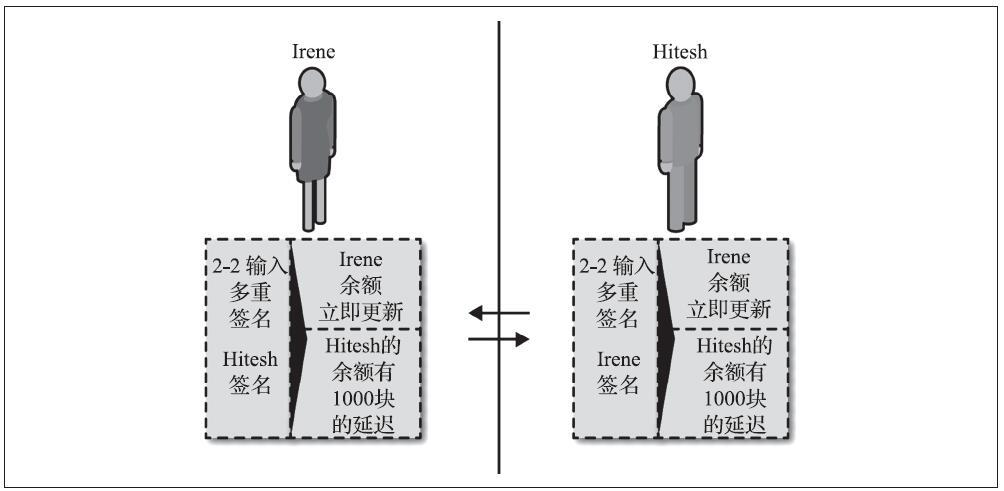
现在我们介绍这个方案的最后一个要素:一个撤销密钥,允许被欺诈的一方通过占有通道的所有余额来惩罚骗子。
每个承诺交易都有一个“延迟”的输出。该输出的兑换脚本允许一方在1000个区块后兑换它,或者另一方如果拥有撤销密钥也可兑换它。所以当Hitesh为Irene签署承诺交易时,他将把第二个输出定义为在1000块之后可输出支付给自己,或者是任何可以出示撤销密钥的人。Hitesh构建了这个交易,并创建了一个由他秘密保管的撤销密钥。当他准备转移到新的通道状态并希望撤销这一承诺时,他才会把撤销密钥透露给Irene。第二个输出脚本如下所示:
Output 0<5 bitcoin>: <Irene's Public Key> CHECKSIG Output 1<5 bitcoin>: IF # Revocation penalty output <Revocation Public Key> ELSE <1000 blocks> CHECKSEQUENCEVERIFY DROP <Hitesh's Public Key> ENDIF CHECKSIG
Irene可以自信地签署这笔交易,因为一旦被发送它将立即支付她被欠的欠款。Hitesh持有交易,但知道如果他在单方关闭通道并发送交易,他将不得不等待1000个块才能获得支付。
当通道进入下一个状态时,Hitesh必须在Irene同意签署下一个承诺交易之前撤销此承诺交易。要做到这一点,他所要做的就是将撤销密钥发送给Irene。一旦Irene拥有这一承诺交易的撤销密钥,她就可以自信地签署下一个承诺。她知道,如果Hitesh试图通过发布先前的承诺交易来作弊,她可以使用撤销密钥来兑换Hitesh的延迟输出。如果Hitesh作弊,Irene会得到所有的(两方)输出。
撤销协议是双边的,这意味着在每一轮中,随着通道状态的进一步发展,双方交换新的承诺,交换用于之前承诺的撤销密钥,并签署彼此的承诺交易。当他们接受新的状态时,他们通过给予对方必要的撤销密钥来惩罚任何作弊行为,使先前的状态不可能再被使用。
我们来看一个如何运作的例子。Irene的客户之一希望向Hitesh的客户发送2比特币。要通过通道传输2比特币,Hitesh和Irene必须更新通道状态以反映新的余额。他们将承诺一个新的状态(状态号2),通道的10个比特币分成两部分,7个比特币属于Hitesh,3个比特币属于Irene。为了更新通道的状态,他们将各自创建反映新通道余额的新承诺交易。
如上述内容所述,这些承诺交易是不对称的,所以每一方所持的承诺交易都迫使他们如要兑换必须等待。至关重要的是,在签署新的承诺交易之前,他们必须首先交换撤销密钥以使先前的承诺无效。在这种情况下,Hitesh的利益与通道的真实状态是一致的,因此他没有理由广播先前的状态。然而,对于Irene来说,状态号1中留给她的余额比状态号2中的更高。当Irene给予Hitesh她以前的承诺交易(状态号1)的撤销密钥时,实际上她废除了自己可以回滚通道状态到前一状态而从中获益的能力。
因为有了撤销密钥,Hitesh可以毫不拖延地兑换先前承诺交易的两个输出。也就是说一旦Irene广播先前的状态,Hitesh可以行使其占有所有输出的权利。
重要的是,撤销不会自动发生。虽然Hitesh有能力惩罚Irene的作弊行为,但他必须勤勉地观察区块链中作弊的迹象。如果他看到先前的承诺交易广播,他有1000个区块时间采取行动,并使用撤销密钥来阻止Irene的欺骗行为并占有所有余额也就是全部10比特币来惩罚她。
带有相对时间锁(CSV)的不对称可撤销承诺是实现支付通道的更好方法,也是区块链技术非常重要的创新。通过这种结构,通道可以无限期地保持开放,并且可以拥有数十亿的中间承诺交易。在闪电网络的原型实现中,承诺状态由48位索引识别,允许在任何单个通道中有超过281兆(2.8×1014)个状态转换!
(5)散列时间锁合约
支付通道可以通过特殊类型的智能合约进一步扩展,以允许参与者将资金用于可兑换的具有到期时间的密钥(secret)。此功能称为散列时间锁合约(Hash Time LockContracts,HTLC),并用于双向支付通道和路由支付通道。
首先我们来解释HTLC的“散列”部分。要创建一个HTLC,预期的收款人将首先创建一个密钥(secret)R。然后计算这个R的散列值H:
H = Hash(R)
这步产生可以包含在输出的锁定脚本中的散列值H。任何知道密钥的人可以用它来兑换输出。密钥R也被称为散列函数的“前图像”(preimage)。前图像就是用作散列函数输入的数据。
HTLC的第二部分是“时间锁”模块。如果没有人拿密钥来兑换,HTLC的付款人可以在一段时间后得到“退款”。这是通过使用绝对时间锁(CHECKLOCKTIMEVERIFY)来实现的。
实现HTLC的脚本可能如下所示:
IF # Payment if you have the secret R HASH160 <H> EQUALVERIFY ELSE # Refund after timeout. <locktime> CHECKLOCKTIMEVERIFY DROP <Payee Pubic Key> CHECKSIG ENDIF
任何知道可以让散列值等于H的对应密钥R的人,可以通过行使IF语句的第一个子句来兑换该输出。
如果没有人拿密钥来兑换,HTLC中写明了,在一定数量的块之后,收款人可以使用IF语句中的第二个子句申请退款。
这是HTLC的基本实现。任何拥有密钥R的人都可以兑换这种类型的HTLC。通过对脚本进行微调,HTLC可以变化成许多不同的形式。例如,在第一个子句中添加一个CHECKSIG运算符和一个公钥来限制将散列值兑换成一个指定的收款人,而且这个人必须知道密钥R。
路由支付通道(闪电网络)
闪电网络是一种端到端由双向支付通道连接的可路由网络。这样的网络可以允许任何参与者将支付从一通道发送到另一个通道,而不需要信任任何中间人。Joseph Poon和Thadeus Dryja在许多其他人提出和阐述的支付通道概念基础上,于2015年2月首次提出了闪电网络。
“闪电网络”是指路由支付通道网络的特定设计,现已由至少五个不同的开源团队实施。这些的独立实施基于“闪电技术基础”(BOLT)论文(http://bit.ly/2rBHeoL)中描述的一组互通性标准进行协调。
闪电网络是实现可路由支付通道的一种可能方式。还有其他几种旨在实现类似目标的设计,例如Teechan和Tumblebit。
(1)闪电网络示例
让我们看看它是如何工作的。
在这个例子中,我们有五个参与者:Alice、Bob、Carol、Diana和Eric。这五名参与者彼此之间已经开设了支付通道。Alice和Bob有支付通道。Bob连接Carol,Carol连接到Diana,Diana连接Eric。为了简单起见,我们假设每个通道每个参与者都注资2个比特币资金,每个通道的总容量为4个比特币。
下图显示一系列通过双向支付的通道连接在一起形成的闪电网络,以支持一笔从Alice到Eric的付款展示了闪电网络中五名参与者通过双向支付通道连接,可从Alice付款到Eric。
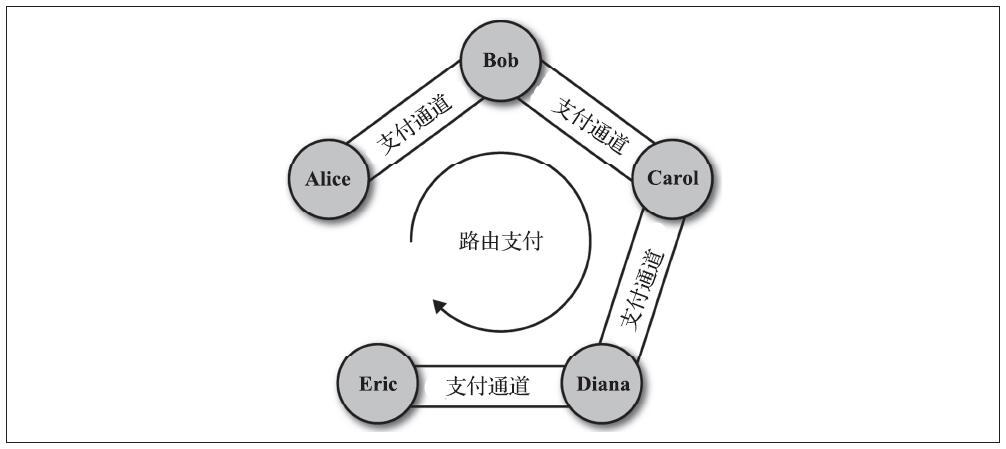
Alice想要给Eric支付1个比特币。不过,Alice并未通过支付通道直接连接到Eric。创建支付通道需要资金交易,而这笔交易必须首先提交给比特币区块链。Alice不想打开一个新的支付通道并支出更多的资金。有没有办法间接支付到Eric?
下图显示了在连接各方参与者的支付通道上通过一系列HTLC承诺将付款从Alice路由到Eric的过程。
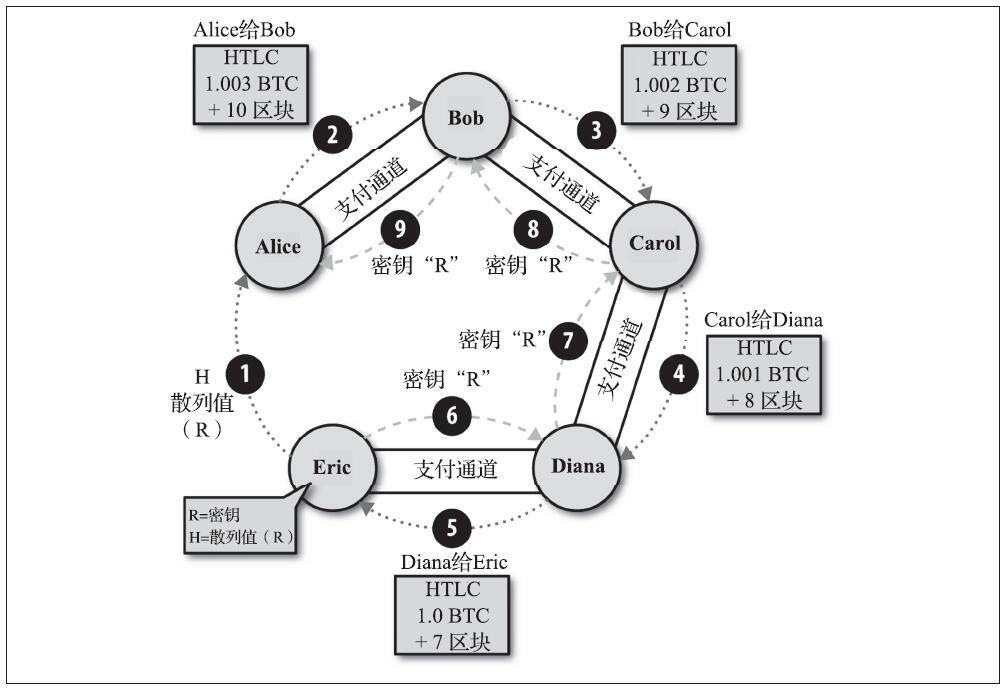
现在Alice的LN节点构建了Alice的LN节点和Eric的LN节点之间的路由。所使用的路由算法将在后面进行更详细的解释,但现在我们假设Alice节点可以找到一个高效的路由。
然后,Alice的节点构造一个HTLC,支付到散列H,并具有10个区块时间锁用于(当前块+10)退款,数量为1.003比特币(步骤2)。额外的0.003比特币将用于补偿参与此支付路由的中间节点。Alice将此HTLC提供给Bob,从和Bob之间的通道余额中扣除1.003比特币,并将其提交给HTLC。该HTLC具有以下含义:“如果Bob知道密钥,Alice将其通道余额的1.003比特币支付给Bob,或者如果超过10个区块时间后,则退还到Alice的账号”。Alice和Bob之间的通道余额现在由承诺交易表示,其中有三个输出:Bob的2比特币余额,Alice的0.997比特币余额,Alice的HTLC中承诺的1.003比特币。承诺交易再从Alice的余额中减去HTLC中的金额。
Bob现在有一个承诺交易,如果他能够在接下来的10个区块生产时间内获得密钥R,他可以获取Alice锁定的1.003。手上有了这一承诺,Bob的节点在和Carol的支付通道上构建了一个HTLC。Bob的HTLC提交一笔HTLC(1.002比特币到散列H及9个区块时间锁),如果Carol拥有密钥R,她就可以兑换这个HTLC(步骤3)。Bob知道,如果Carol要获取他的HTLC,她必须出示密钥R。如果Bob在9个区块的时间内有R,他可以用它给自己兑换Alice的HTLC。通过承诺自己的通道余额9个区块的时间,他也赚了0.001比特币。如果Carol无法获取他的HTLC,并且他也无法获取Alice的HTLC,那么一切都将恢复到之前的通道余额,没有人会亏损。Bob和Carol之间的通道余额现在是:2比特币给Carol,0.998比特币给Bob,1.002比特币由Bob承诺给HTLC。
Carol现在有一个承诺,如果她在接下来的9个区块时间内获得R,她可以获取Bob的锁定1.002比特币。现在她可以在她与Diana的通道上构建HTLC承诺。她提交了一个1.001比特币的HTLC(1.001比特币到散列H及8个区块时间锁),如果Diana有密钥R,她就可以兑换(步骤4)。从Carol的角度来看,如果能够实现,她就可以获得0.001比特币,否则也没有失去任何东西。她提交给Diana的HTLC,只有在R是已知的情况下才可行,到那时候她可以从Bob那里索取HTLC。Carol和Diana之间的通道余额现在是:2比特币给Diana,0.999比特币给Carol,1.001比特币由Carol承诺给HTLC。
最后,Diana可以提供给Eric一个HTLC,1比特币到散列H及7个区块时间锁(步骤5)。Diana与Eric之间的通道余额现在是:2比特币给Eric,1比特币给Diana,1比特币由Diana承诺给HTLC。
然而,在这个节点上,Eric拥有密钥R,他可以获取Diana提供的HTLC。他将R发送给Diana,并获取1比特币,添加到他的通道余额中(步骤6)。通道余额现在是:1比特币给Diana,3比特币给Eric。
现在,Diana有密钥R,因此,她现在可以获取来自Carol的HTLC。Diana将R发送给Carol,并将1.001比特币添加到其通道余额中(步骤7。现在Carol与Diana之间的通道余额是:0.999比特币给Carol,3.001比特币给Diana。Diana已经“赚了”参与这个付款路线0.001比特币。
通过路由回传,密钥R允许每个参与者获取未完成的HTLC。Carol从Bob那里获取1.002个比特币,将他们的通道余额设为:0.998比特币给Bob,3.002比特币给Carol(步骤8)。最后,Bob获取来自Alice的HTLC(步骤9)。他们的通道余额更新为:0.997比特币给Alice,3.003比特币给Bob。
在没有向Eric打开支付通道的情况下,Alice已经支付给Eric 1比特币。付款路线中的中间方无须互相信任。在他们的通道内做一个短时间的资金承诺,他们就可以赚取一小笔费用,唯一的风险是,如果通道关闭或路由付款失败,退款有段短的延迟时间。
(2)闪电网络传输和路由
LN节点之间的所有通信都是点对点加密的。另外,节点有一个长期公钥,它们用作标识符并且彼此认证对方(http://bit.ly/2r5TACm)。
每当节点希望向另一个节点发送支付时,它必须首先通过连接具有足够容量的支付通道来构建通过网络的路径。节点宣传路由信息,包括已经打开的通道,每个通道拥有多少容量,以及收取多少路由支付费用。路由信息可以以各种方式共享,并且随着闪电网络技术的进步,不同的路由协议可能会出现。一些闪电网络实施使用IRC协议作为节点宣布路由信息的一种方便的机制。路由发现的另一种实现方式是使用P2P模型,其中节点采用“泛洪”模型将通道公告传播给其他的节点,这类似于比特币传播交易的方法。未来的计划包括一个名为Flare(http://bit.ly/2r5TACm)的提案,它是一种具有本地节点“邻近点”(neighborhoods)和较长距离的信标节点的混合路由模型。
在前面的例子中,Alice的节点使用这些路由发现机制之一来查找将她的节点连接到Eric的节点的一个或多个路径。一旦Alice的节点构建了路径,她将通过网络初始化该路径,传播一系列加密和嵌套的指令来连接每个相邻的支付通道。
重要的是,这个路径只有Alice的节点才知道。付款路线上的所有其他参与者只能看到相邻的节点。从Carol的角度来看,这看起来像是从Bob到Diana的付款。Carol不知道Bob实际上是中继转发Alice的汇款。她也不知道Diana将会向Eric中继转发付款。
这是闪电网络的一个重要特征,因为它确保了付款的隐私,并且使得很难对其应用监控、审查以及黑名单机制。但是,Alice如何建立这种付款路径,而不向中间节点透露任何内容呢?
闪电网络实现了一种基于Sphinx(http://bit.ly/2q6ZDrP)方案的洋葱路由协议。该路由协议确保支付发送者可以通过闪电网络构建和通信路径,使得:
- 中间节点可以验证和解密其部分路由信息,并找到下一跳。
- 除了上一跳和下一跳,他们不能获取路径上任何其他节点。
- 他们无法识别支付路径的长度,或者他们自己在该路径中的位置。
- 路径的每个部分都被加密,使得网络级别的攻击者不能将来自路径的不同部分的数据包相互关联。
- 不同于Tor(互联网上的洋葱路由匿名协议),没有可以被监视的“退出节点”。付款不需要传输到比特币区块链,节点只是更新通道余额。
使用这种洋葱路由协议,Alice将路径的每个节点信息封装在一层加密中,从尾端开始倒过来运算。她用Eric的公钥加密了Eric的消息。该消息封装在加密到Diana的消息中,并将Eric标识为下一个收件人。给Diana的消息封装在加密到Carol的公钥的消息中,并将Diana识别为下一个收件人。对Carol的消息被Bob的密钥加密。这样一来,Alice已经构建了这个加密的多层“洋葱”的消息。她发送给Bob,他只能解密和解开外层。在里面,Bob发现了一封给Carol的消息,他可以转发给Carol,但不能自己破译。按照路径,消息被转发、解密、转发等,一路到Eric那里。每个参与者只知道各自这一跳的前一个和下一个节点。
路径中的每个节点都包含有关HTLC必须扩展到下一个跳的信息,HTLC中的要发送的数量,要包括的费用以及CLTV锁定到期时间(以块为单位)。随着路由信息的传播,节点将HTLC承诺转发到下一跳。
此时,你可能想知道节点如何不知道路径的长度及其在该路径中的位置。毕竟,它们收到一个消息,并将其转发到下一跳。难道它不会将路径缩短,或者允许他们推断出路径长短和位置?为了防止这种情况,路径总是固定在20跳,并用随机数据填充。每个节点都会看到下一跳和一个要转发的固定长度的加密消息。只有最终的收件人看得到没有下一跳。对于其他人来说,似乎总是有20多跳要走。
(3)闪电网络优势
闪电网络是第二层路由技术。它可以应用于任何支持一些基本功能的区块链,如多重签名交易、时间锁和基本的智能合约。
如果闪电网络搭建在比特币网络之上,则比特币网络在不牺牲无中介机构的无信任操作原则下,大幅提高交易容量、隐私性、粒度和速度。
- 隐私。通过闪电网络付款比通过比特币区块链的付款更私密,因为它们不是公开的。虽然路由中的参与者可以看到在其通道上传播的付款,但他们并不知道发件人或收件人。
- 流动性。闪电网络使得在比特币上应用监视和黑名单变得更加困难,从而增加了货币的流动性。
- 速度。使用闪电网络的比特币交易将以毫秒为单位,而不是分钟,因为HTLC在不用提交交易到区块上的情况下被结算。
- 粒度。闪电网络可以使支付至少与比特币“灰尘”(dust)限制一样小,甚至更小。一些提案允许以子聪级增量(subsatoshi increments)。
- 容量。闪电网络将比特币系统的容量提高了几个数量级。每秒可以通过闪电网络路由的付费数量没有具体上限,因为它仅取决于每个节点的容量和速度。
- 无须信任运作。闪电网络可以让对等节点在不需要互相信任的情况下使用比特币交易。因此,闪电网络保留了比特币系统的原理,同时显著扩大了其运行参数。
当然,如前所述,闪电网络协议不是实现路由支付通道的唯一方法。其他被提案的系统包括Tumblebit和Teechan。几个不同的团队已经正在竞争开发LN的实现,并且正在朝着共同的互交互标准努力(称为BOLT)。
结论
我们仅研究了几个可以使用比特币区块链作为信任平台构建的新兴应用程序。这些应用程序将比特币的范围扩大到超出付款和超越金融工具的范围,涵盖了许多信任至关重要的应用程序。通过去中性化的信任基础,各种行业将在比特币区块链平台上产生更多革命性的应用。






