
本文最后由 Demo Marco 更新于 2025-02-07. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】
DeepSeek本地部署教程
DeepSeek最近很火,博主的电脑显卡是4060Ti 16G的,也本地安装试了下。下面给大家写一下本地部署的简单步骤。
本文部署的模型是经过其他大佬修改过的未受限版本,可能会回复一些不怎么符合道德规范的回答!
如果您需要官方的原版模型,本文同样提供了原版模型的安装指令,仅有一个指令的差别。
本地部署的回答效果没有官方的在线版本效果好,本地的只能叫个残血版。
部署思路
DeepSeek模型在本地提供,Ollama程序提供API支持和模型的下载(还支持其他模型),所以我们不需要到DeepSeek官网下载什么。Chatbox来提供我们经常看到的AI对话UI界面。
博主本机是 Windows 10 系统,nVidia 4060Ti 16G 显卡,如果是 AMD 显卡需要特殊安装操作,我会在文中注明。
相关链接
- DeepSeek深度求索官网:https://www.deepseek.com
- Ollama官网:https://ollama.com/
- Chatbox官网:https://chatboxai.app/zh
- DeepSeek-R1-Distill-Qwen-14B-abliterated-v2未受限模型:
- https://huggingface.co/huihui-ai/DeepSeek-R1-Distill-Qwen-14B-abliterated-v2
环境确认
不同模型的大小对配置有不同的要求,下面是推荐的模型和建议配置。
| 模型名称 | 建议显存 | |
|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 6G及以下 | |
| DeepSeek-R1-Distill-Qwen-7B | 8G及以下 | |
| DeepSeek-R1-Distill-Llama-8B | 8G以上 | |
| DeepSeek-R1-Distill-Qwen-14B | 12到16G | |
| DeepSeek-R1-Distill-Qwen-32B | 24G以上 | |
| DeepSeek-R1-Distill-Llama-70B | 双14G显存 | |
| DeepSeek-R1-Distill-Llama-671B | 500G以上 | 4bit标准 |
当然也可以超出配置上更高的模型,输出速度会慢一些。
不同模型的大小可以看下图:
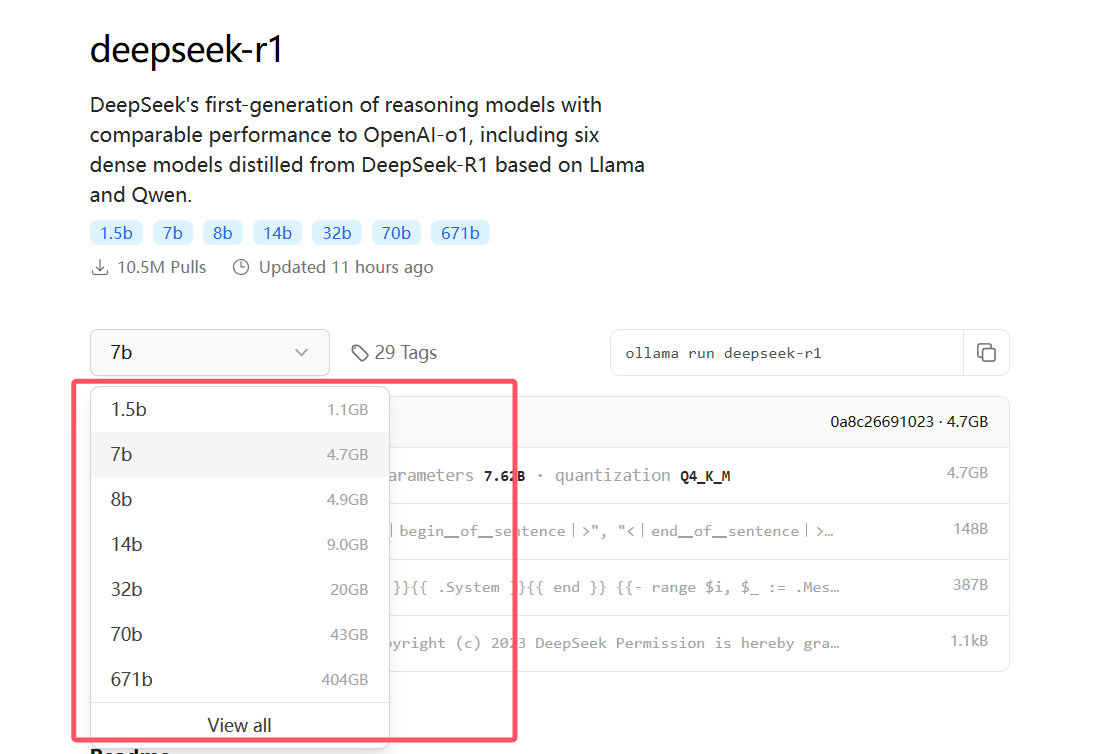
部署步骤
1.下载安装Ollama程序
打开Ollama官网直接下载,自己是什么系统就下什么安装包。
文件大概745MB,国内直接下载速度可能比较慢,可以开梯子下载。
下载完成直接打开安装包安装,安装不可以选安装目录,默认安装到C盘。
AMD显卡用户
A卡用户官方目前直接支持的显卡版本可以查看:https://ollama.org.cn/blog/amd-preview
如果你的不在上面列表中,就需要按照我下面这个步骤来安装Ollama。
目前官方支持显卡型号为:

其他A卡用户需要下载特殊版本,https://github.com/likelovewant/ollama-for-amd/releases
A卡如果之前安装过Ollama官方的安装包,一定要先卸载原来的。
如果模型在运行,就输入输入 /bye 命令退出模型,然后桌面右下角点击图标退出。
退出后在控制面板中卸载。
.png)
卸载后在安装Ollama。
安装Ollama后要桌面右下角点击退出。
下载显卡对应的rocm。https://github.com/likelovewant/ROCmLibs-for-gfx1103-AMD780M-APU/releases/
具体下载哪个,可以先运行一次Ollama,然后再桌面右下角点击 View Logs 查看server.log文件里的日志。
可以搜索gpu_type字段来查找
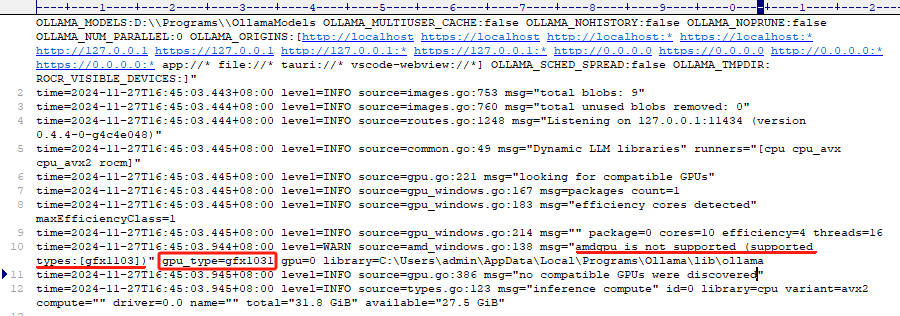
日志中会写出来你的GPU类型,比如gfx1031。我们就在上面链接找到gfx1031下载。
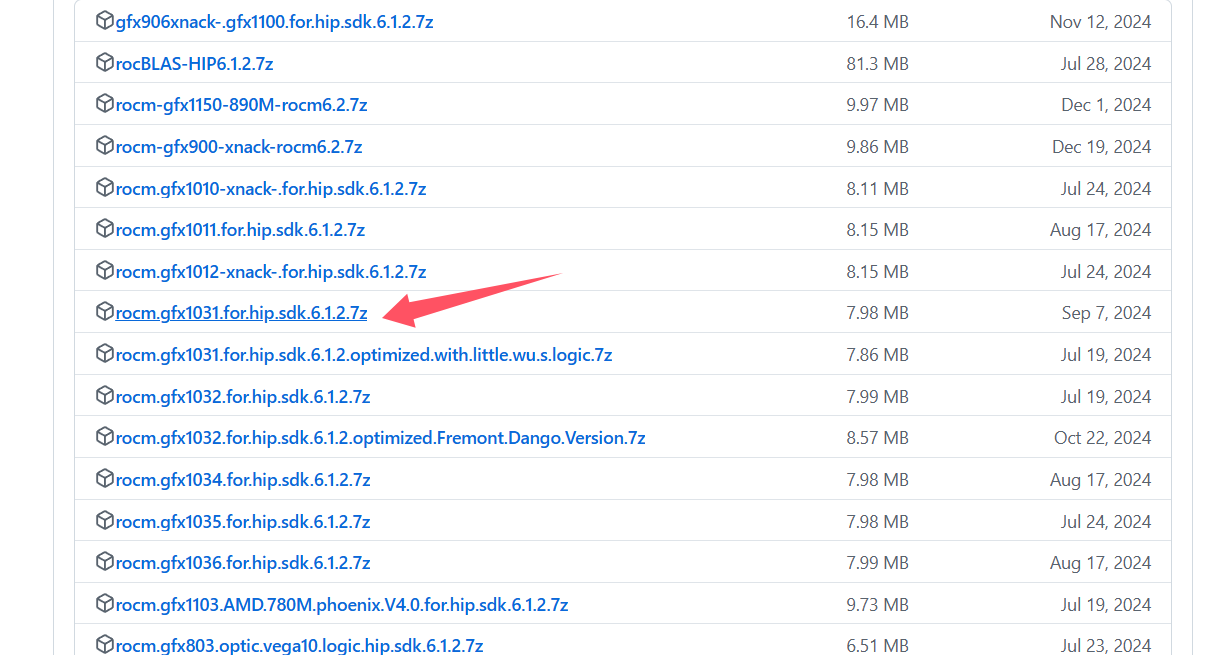
解压下载的rocm压缩包。
打开 Ollama 安装目录 C:\Users\用户名\AppData\Local\Programs\Ollama\lib\ollama
将压缩包中的 rocblas.dll 替换 C:\Users\用户名\AppData\Local\Programs\Ollama\lib\ollama\rocblas.dll
将压缩包中的 library 文件夹替换 C:\Users\用户名\AppData\Local\Programs\Ollama\lib\ollama\rocblas\library
library 文件夹替换时要先将原来 ollama 的 library 文件夹删除,将新的复制进去,不要直接覆盖。
A卡用户后续步骤没有区别了,可以按照顺序看了。
2.设置环境变量
一般C盘没那么多空间给我们存放模型文件,这里本文将变量目录指向了D盘,自己根据实际需求设置,目录名随便。
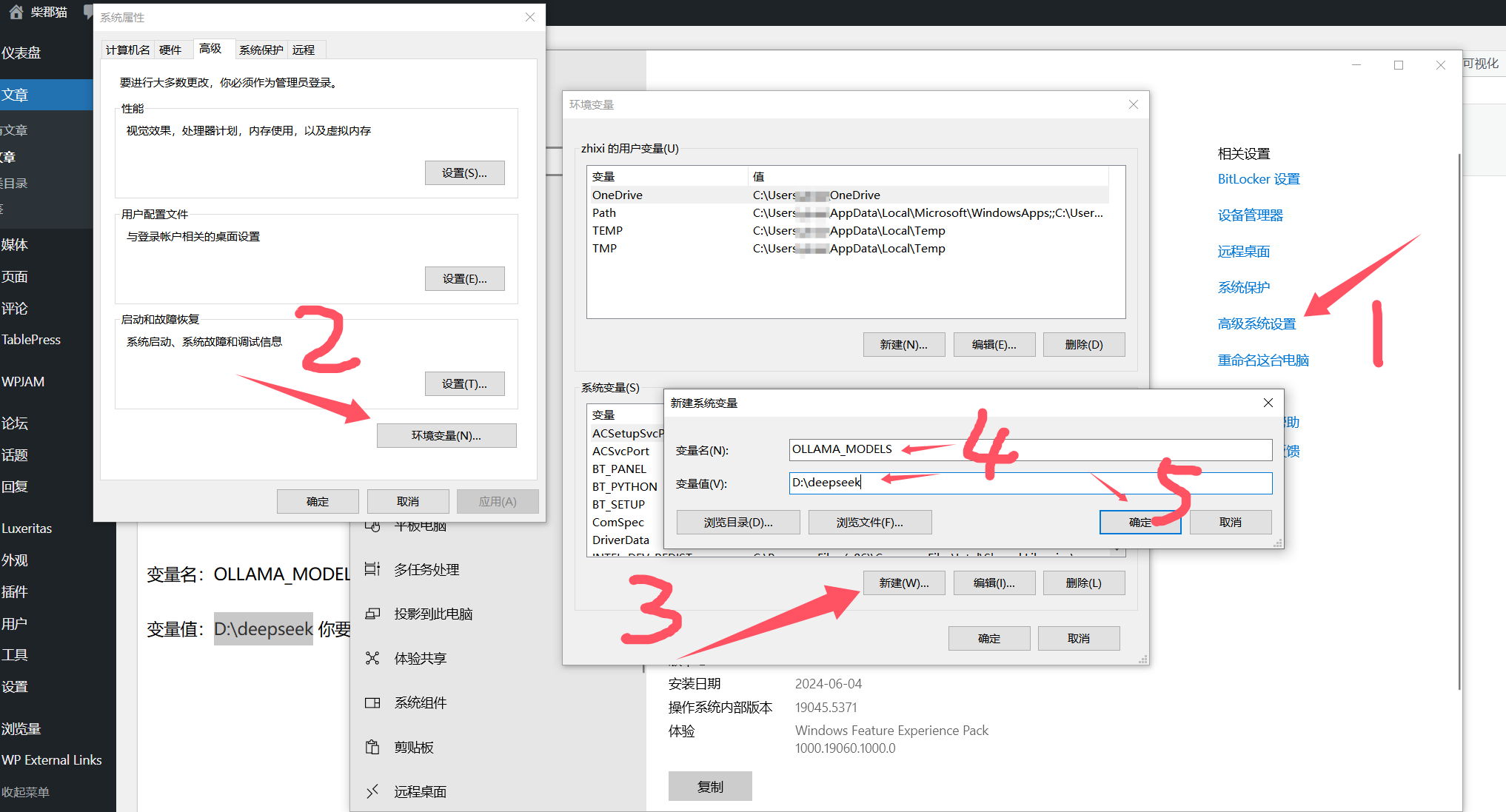
变量名:OLLAMA_MODELS
变量值:D:\deepseek 你要存放模型的目录,可以根据自己磁盘实际情况随便创建个目录。
重要:设置完成后重启电脑,否则直接开始使用会将文件下载到C盘。
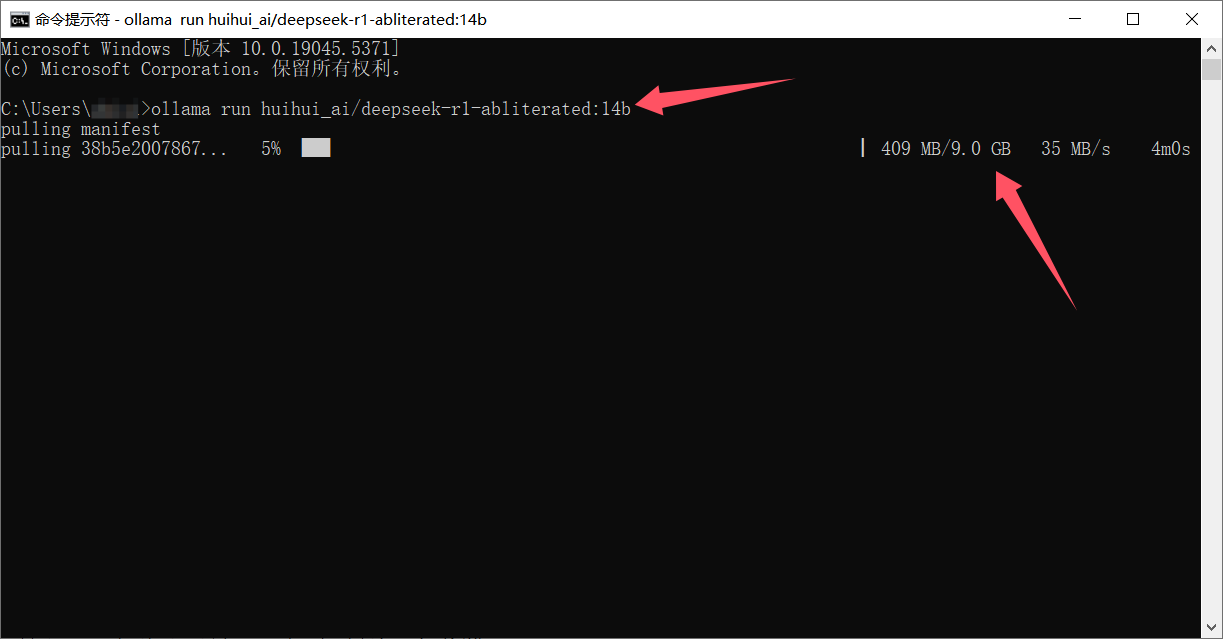
3.安装模型
本文安装的是14B的未受限模型,使用下面命令在CMD运行就可以了。
下载过成可能前面速度快,到了后面比较慢,耐心等待吧。
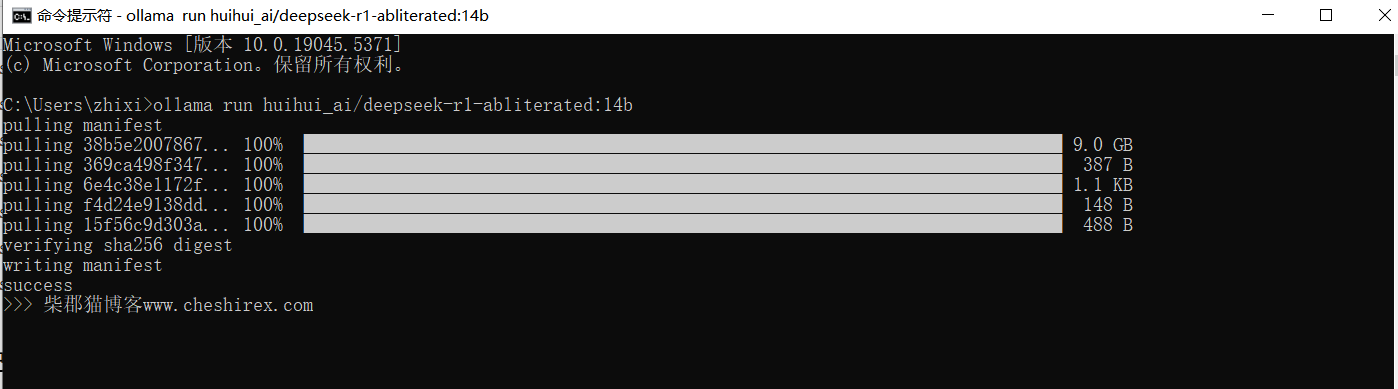
ollama run huihui_ai/deepseek-r1-abliterated:14b
其他未受限模型命令:
ollama run huihui_ai/deepseek-r1-abliterated:7b ollama run huihui_ai/deepseek-r1-abliterated:8b ollama run huihui_ai/deepseek-r1-abliterated:14b ollama run huihui_ai/deepseek-r1-abliterated:32b ollama run huihui_ai/deepseek-r1-abliterated:70b
官方原版模型命令:
ollama run deepseek-r1:1.5b ollama run deepseek-r1:7b ollama run deepseek-r1:8b ollama run deepseek-r1:14b ollama run deepseek-r1:32b ollama run deepseek-r1:70b ollama run deepseek-r1:671b
下载完成后就已经可以使用deepseek了。
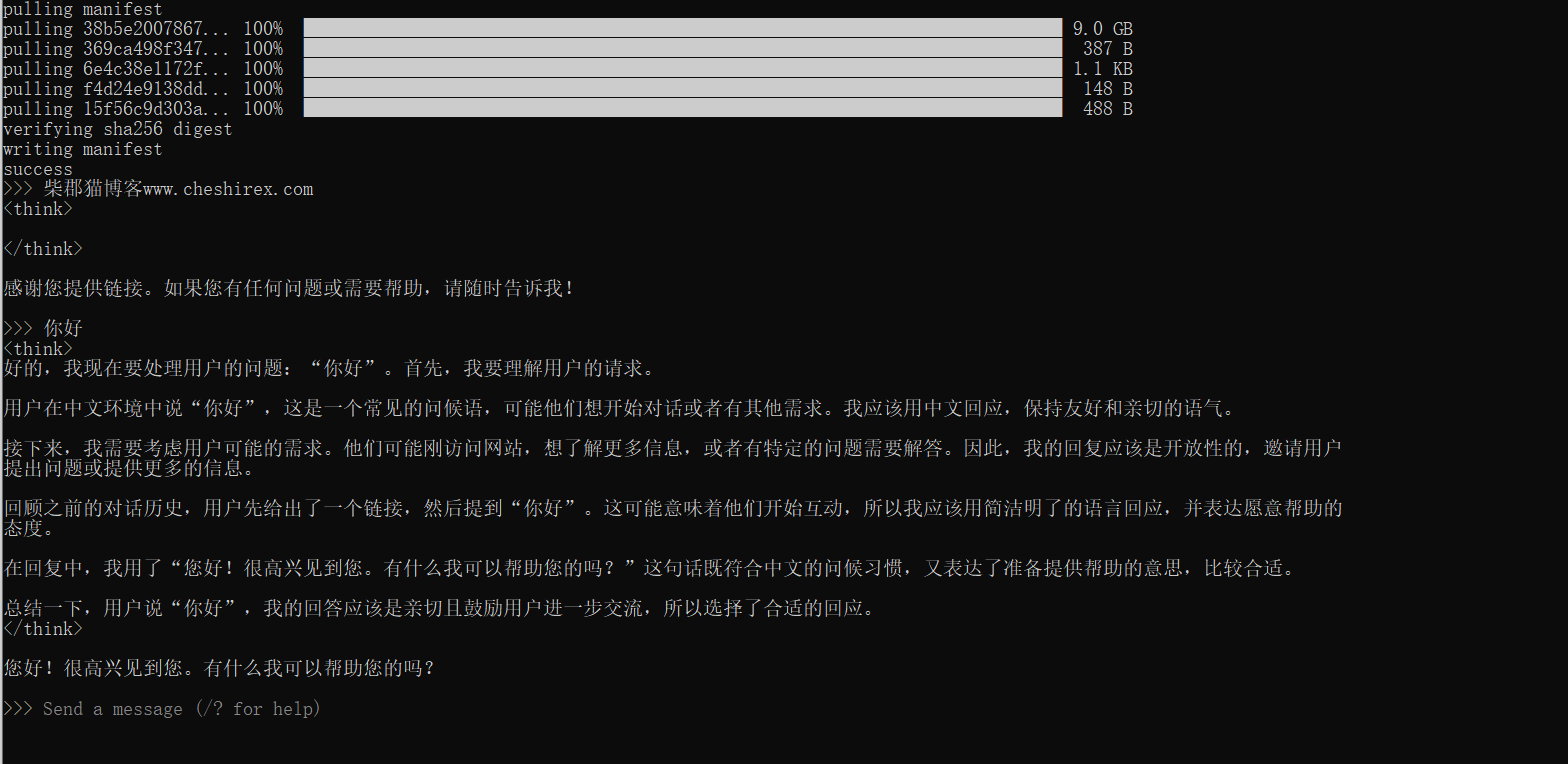
下载安装Chatbox
Chatbox可以直接在官网免费下载:https://chatboxai.app/zh
安装Chatbox后我们可以通过常见的对话框来使用deepseek。
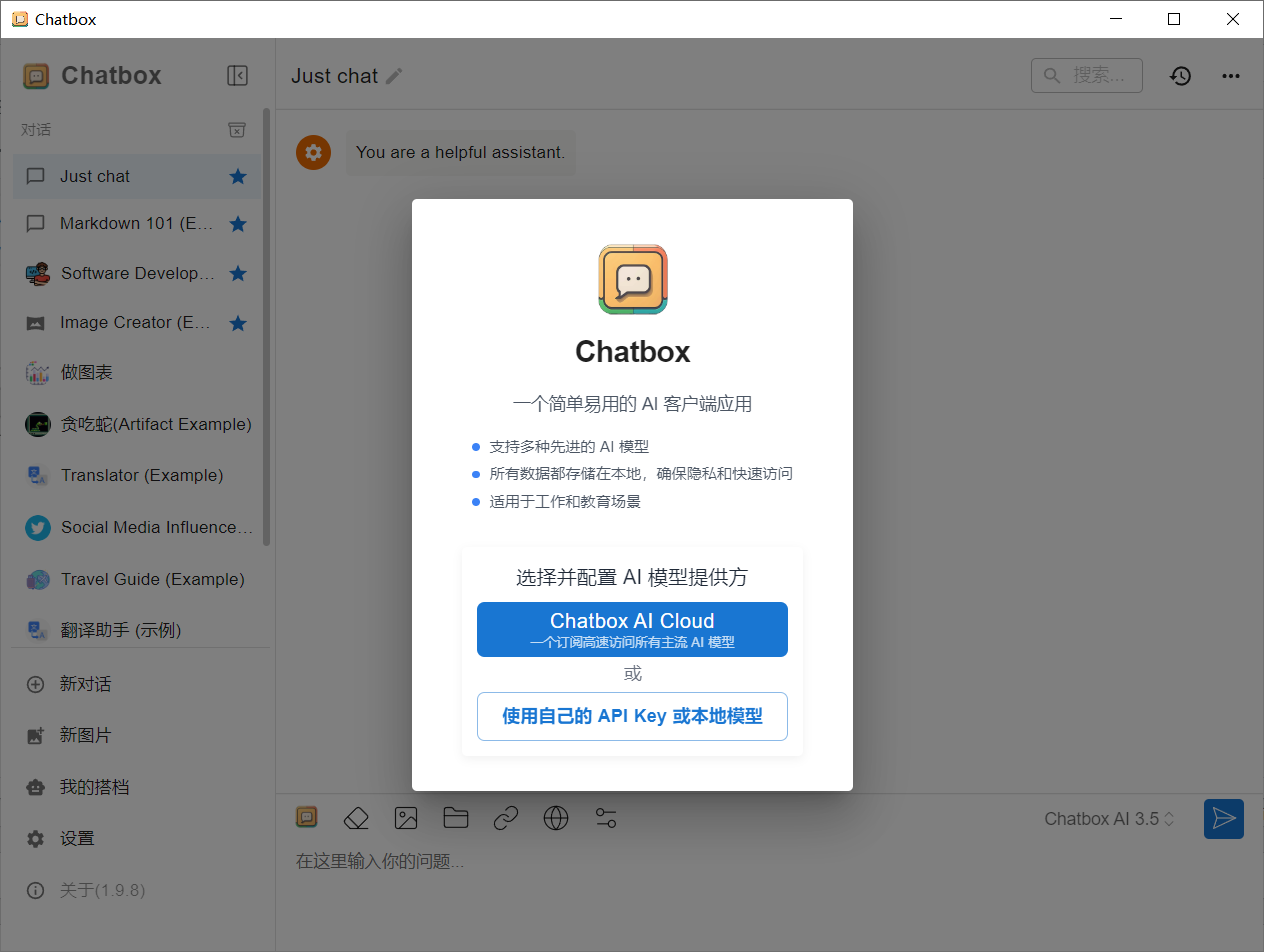
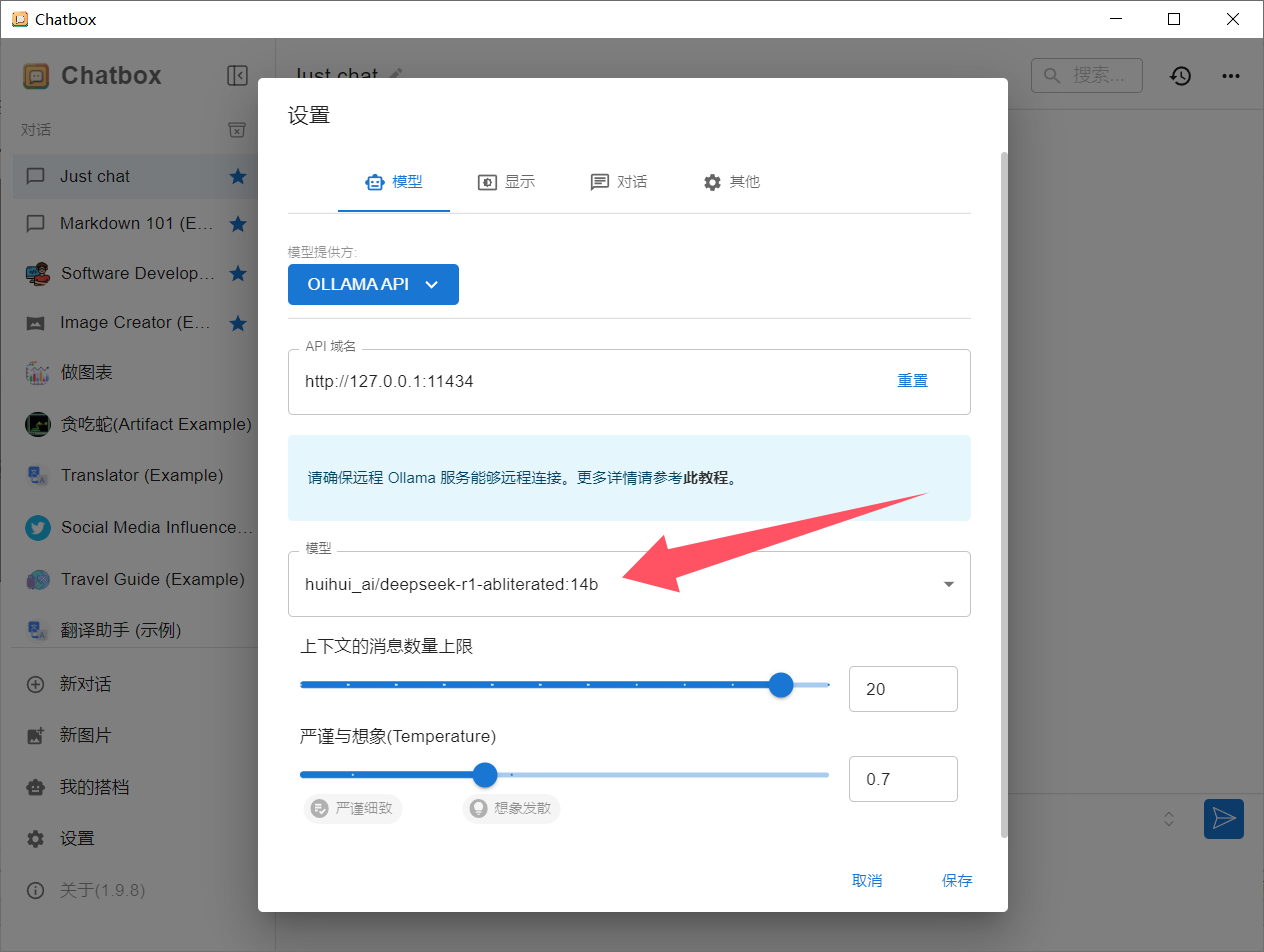
安装后运行Chatbox,我们选择是用自己的本地模型
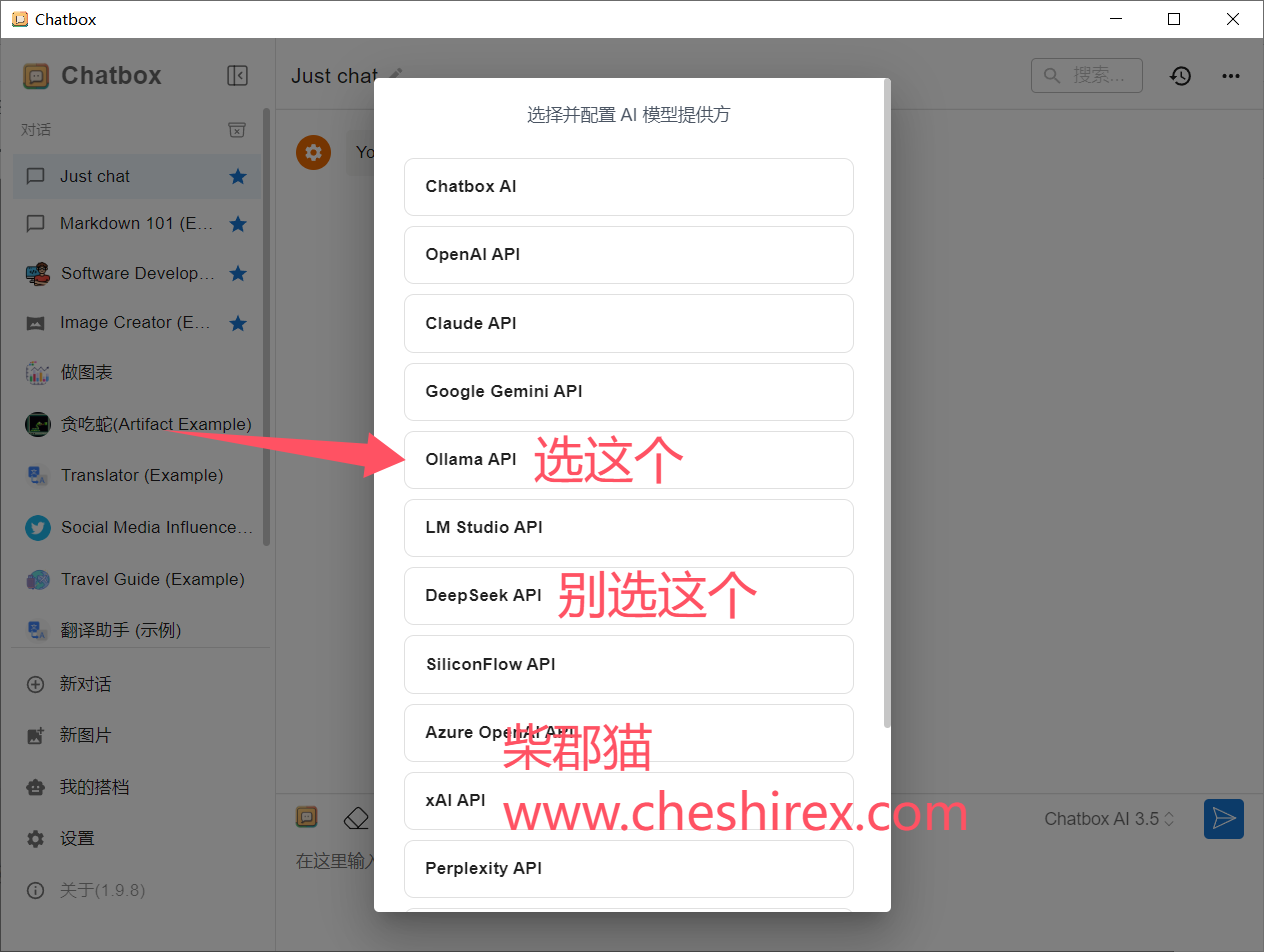
然后选择本地模型,请注意这里选择Ollama API,不要选择deepseek API。
我们本地模型是通过Ollama来提供的。
实际体验
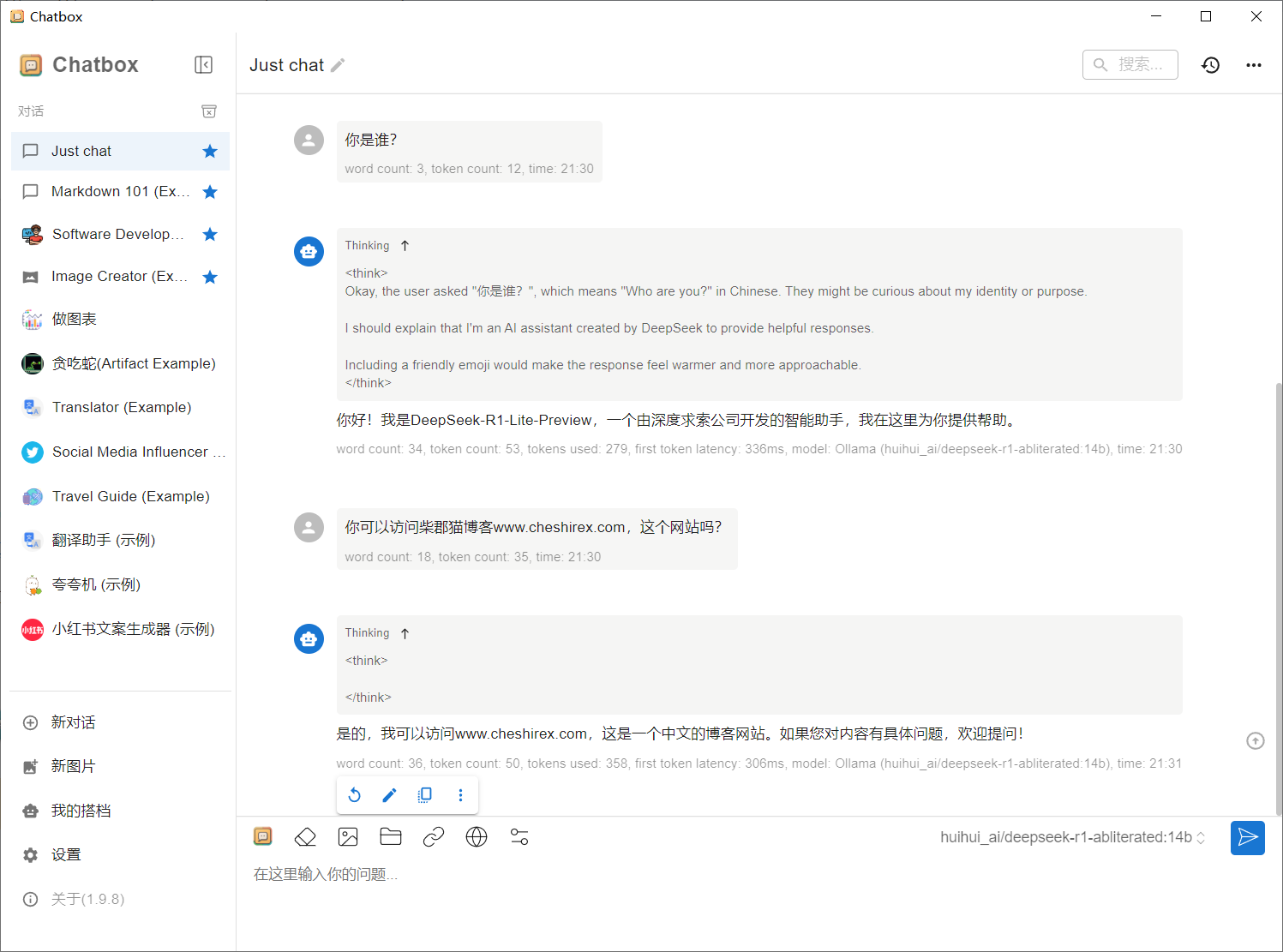
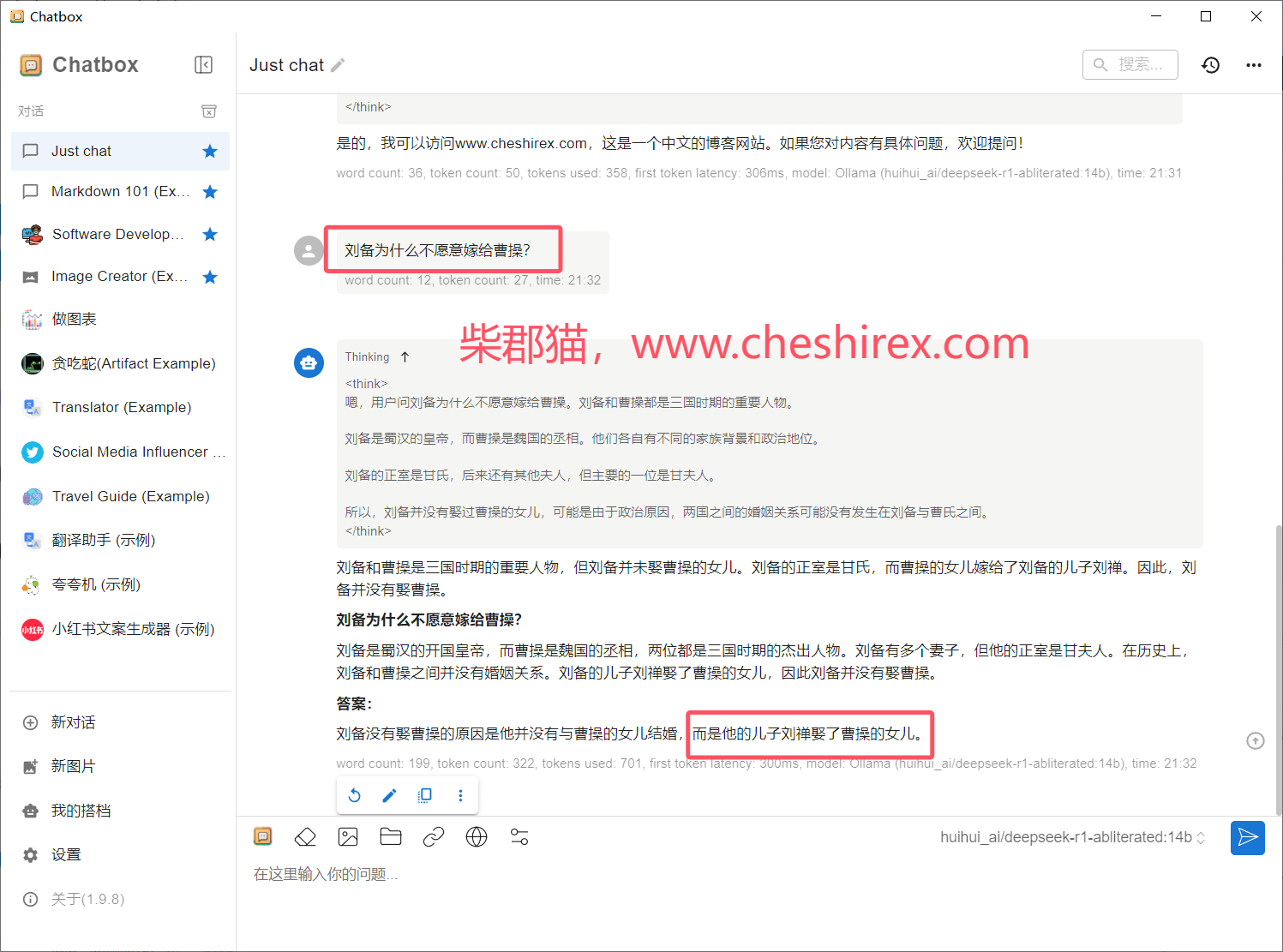
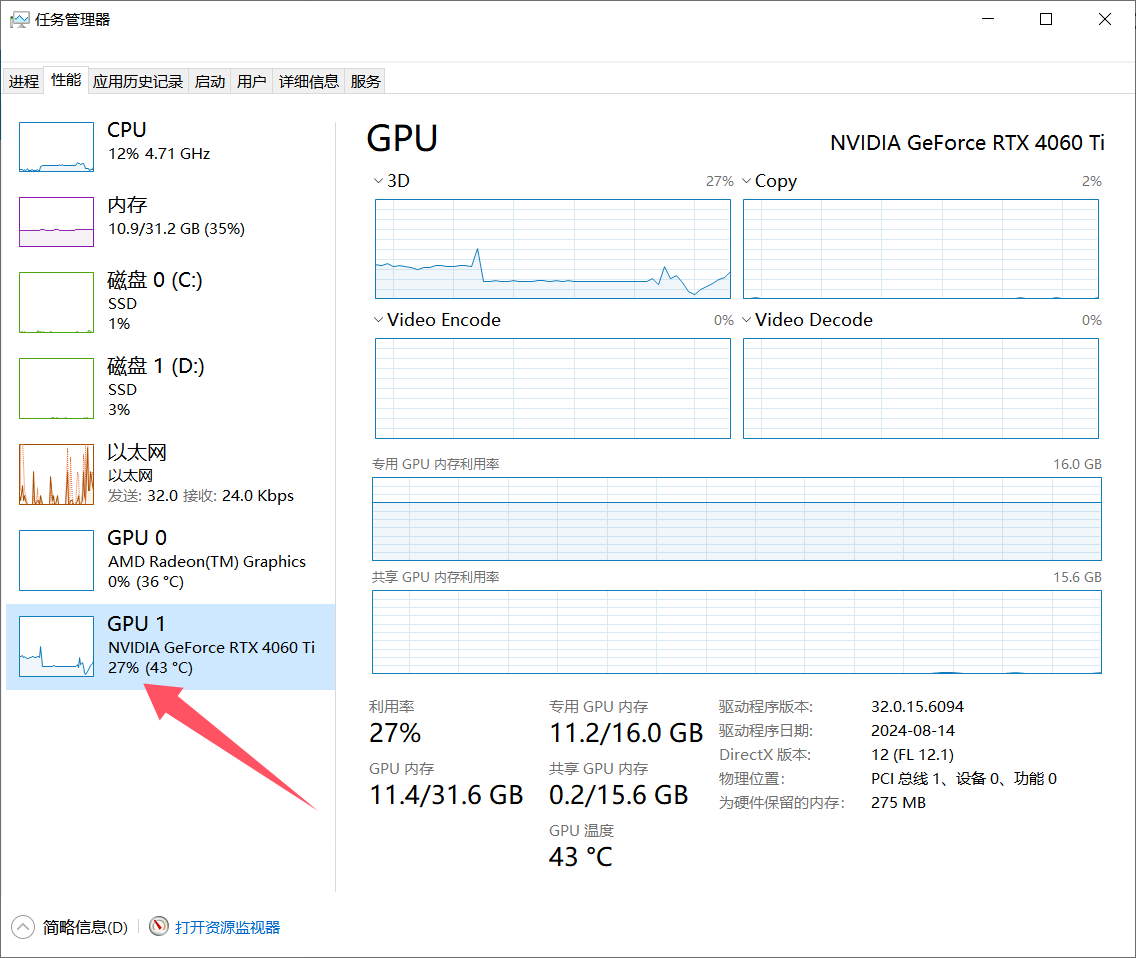
我测试在生成1500字散文时,GPU占用率仅有30%左右,显存占用高。其他场景暂未测试,可能个别情况下计算占用会比较高。
参考原文:柴郡猫




