本文最后由 Demo Marco 更新于 2025-02-22. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】
深度学习是机器学习的一个子领域,是一组受大脑结构和功能启发的算法。
TensorFlow 是 Google 创建的第二个机器学习框架,用于设计、构建和训练深度学习模型。您可以使用 TensorFlow 库进行数值计算,这本身似乎并没有什么特别之处,但这些计算是通过数据流图完成的。在这些图中,节点表示数学运算,而边表示数据,通常是多维数据数组或张量,这些数据在这些边之间传递。
你看到了吗?“TensorFlow”这个名字源自神经网络对多维数据数组或张量执行的操作!它实际上是张量的流。目前,这就是您需要了解的有关张量的全部内容,但您将在下一节中更深入地了解它!
今天的 TensorFlow 初学者教程将以交互方式向您介绍如何执行深度学习:
- 您将首先了解有关张量的更多信息;
- 然后,本教程将简要介绍在系统上安装 TensorFlow的一些方法,以便您能够开始并在工作区中加载数据;
- 在此之后,您将了解一些TensorFlow 基础知识:您将了解如何轻松开始简单的计算。
- 在此之后,您将开始真正的工作:您将加载比利时交通标志的数据,并使用简单的统计和绘图进行探索。
- 在探索过程中,你会发现需要以某种方式处理数据,以便将其输入到模型中。这就是为什么你需要花时间重新缩放图像并将其转换为灰度。
- 接下来,你终于可以开始构建你的神经网络模型了!你将逐层构建你的模型;
- 一旦架构建立起来,您就可以使用它以交互方式训练您的模型,并最终通过向其提供一些测试数据来对其进行评估。
- 最后,您将获得一些指示,以便对刚刚构建的模型进行进一步改进,以及如何继续使用 TensorFlow 进行学习。
在此处下载本教程的笔记本。
此外,您可能对Python 深度学习课程、DataCamp 的Keras 教程或R 语言 keras 教程感兴趣。
张量简介
为了更好地理解张量,最好具备一些线性代数和向量微积分的应用知识。您已经在简介中读到,张量在 TensorFlow 中实现为多维数据数组,但可能需要更多介绍才能完全掌握张量及其在机器学习中的用途。
平面向量
在开始学习平面向量之前,最好先复习一下“向量”的概念;向量是一种特殊类型的矩阵,是数字的矩形阵列。由于向量是有序的数字集合,因此它们通常被视为列矩阵:它们只有一列和一定数量的行。换句话说,你也可以将向量视为已指定方向的标量。
请记住:标量的示例是“5 米”或“60 米/秒”,而矢量的示例是“向北 5 米”或“向东 60 米/秒”。这两者之间的区别显然在于矢量有方向。尽管如此,您到目前为止看到的这些示例可能与您在处理机器学习问题时可能遇到的矢量相去甚远。这是正常的;数学矢量的长度是一个纯数字:它是绝对的。另一方面,方向是相对的:它是相对于某个参考方向测量的,单位是弧度或度。您通常假设方向是正的,并且从参考方向逆时针旋转。
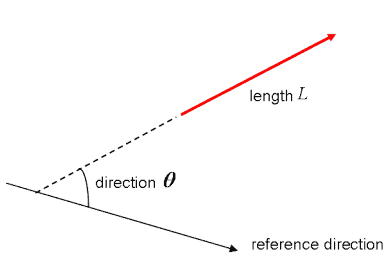
当然,从视觉上看,你可以将向量表示为箭头,如上图所示。这意味着你也可以将向量视为具有方向和长度的箭头。方向由箭头的头部表示,而长度由箭头的长度表示。
那么平面向量又如何呢?
平面向量是张量最直接的设置。它们与上面看到的常规向量非常相似,唯一的区别是它们位于向量空间中。为了更好地理解这一点,让我们从一个例子开始:你有一个2 X 1的向量。这意味着该向量属于一次成对出现的实数集。或者换句话说,它们是二维空间的一部分。在这种情况下,你可以用箭头或射线表示坐标(x,y)平面上的向量。
从这个坐标平面的标准位置开始,向量的端点位于原点(0,0),你可以通过查看向量的第一行得出x坐标,而在第二行可以找到y坐标。当然,这个标准位置并不总是需要保持:向量可以在平面上平行移动而不会发生变化。
请注意,同样,对于大小为3 X 1的向量,您讨论的是三维空间。您可以将向量表示为三维图形,其中箭头指向向量空间中的位置:它们绘制在标准的x、y和z轴上。
拥有这些向量并将它们表示在坐标平面上固然很好,但本质上,你拥有这些向量是为了对它们执行操作,而可以帮助你做到这一点的一件事就是将你的向量表示为基或单位向量。
单位向量是量级为 1 的向量。单位向量通常用带有脱字符或“帽子”的小写字母来表示。如果你想将二维或三维向量表示为两个或三个正交分量(例如 x 轴和 y 轴或 z 轴)的总和,单位向量会很方便。
例如,当您谈论将一个向量表达为分量的和时,您会发现您正在谈论分量向量,它们是两个或多个向量,其和是给定向量。
提示:观看此视频,它借助简单的家用物品解释了什么是张量!
张量
除了平面向量之外,余向量和线性算子也是另外两种情况,这三种情况有一个共同点:它们都是张量的具体情况。您还记得上一节中如何将向量描述为具有方向的标量。那么,张量就是物理实体的数学表示,可以用量级和多个方向来描述。
并且,就像在三维空间中用单个数字表示标量、用三个数字的序列表示向量一样,张量也可以用三维空间中的 3R 个数字的数组表示。
此符号中的“R”表示张量的阶:这意味着在三维空间中,二阶张量可以用 3 的 2 次方或 9 个数字表示。在 N 维空间中,标量仍然只需要一个数字,而向量则需要 N 个数字,张量则需要 N^R 个数字。这解释了为什么您经常听到标量是阶为 0 的张量:因为它们没有方向,所以可以用一个数字表示它们。
考虑到这一点,识别标量、向量和张量并区分它们就相对容易了:标量可以用一个数字表示,向量可以用一组有序的数字表示,张量可以用一个数字数组表示。
张量的独特之处在于分量和基向量的组合:基向量在参考系之间以一种方式变换,而分量的变换方式则使分量和基向量之间的组合保持相同。
安装 TensorFlow
现在您已经对 TensorFlow 有了更多的了解,是时候开始安装该库了。在这里,很高兴知道 TensorFlow 为 Python、C++、Haskell、Java、Go、Rust 提供了 API,并且还有一个名为的 R 第三方包tensorflow。
在本教程中,您将下载一个 TensorFlow 版本,该版本将使您能够用 Python 编写深度学习项目的代码。在TensorFlow 安装网页virtualenv上,您将看到使用、、 Docker安装 TensorFlow 的一些最常用方法和最新说明pip,最后,还有一些在个人计算机上安装 TensorFlow 的其他方法。
注意:如果您使用的是 Windows,也可以使用 Conda 安装 TensorFlow。但是,由于 TensorFlow 的安装由社区支持,因此最好查看官方安装说明。
现在您已经完成了安装过程,现在是时候通过将 TensorFlow 导入到您的工作区中的别名下来仔细检查您是否已正确安装了它tf:
import tensorflow as tf请注意,您在上面的代码行中使用的别名是一种约定 – 它用于确保您与一方面在数据科学项目中使用 TensorFlow 的其他开发人员保持一致,另一方面与开源 TensorFlow 项目保持一致。
TensorFlow 入门:基础知识
您通常会编写 TensorFlow 程序,然后将其作为一个块运行;乍一看,当您使用 Python 时,这有点矛盾。但是,如果您愿意,您也可以使用 TensorFlow 的交互式会话,您可以使用它来更交互式地与库一起工作。当您习惯使用 IPython 时,这尤其方便。
在本教程中,您将重点关注第二个选项:这将帮助您在 TensorFlow 中开始深度学习。但在您进一步了解之前,让我们先尝试一些小东西,然后再开始繁重的工作。
tensorflow首先,以别名导入库tf,如上一节中所示。然后初始化两个变量(实际上是常量)。将一个包含四个数字的数组传递给函数。constant()
请注意,您也可以传入一个整数,但通常情况下,您会发现自己使用的是数组。正如您在介绍中看到的,张量都是关于数组的!因此,请确保传入一个数组 🙂 接下来,您可以使用将两个变量相乘。将结果存储在变量中。最后,借助函数打印出来。multiply()resultresultprint()
- 脚本.py
7
- IPython Shell
在[1]中:跑步
请注意,您已在上面的 DataCamp Light 代码块中定义了常量。但是,还有两种其他类型的值可能供您使用,即占位符,它们是未分配的值,将在运行会话时由会话初始化。就像已经给出的名称一样,它只是一个张量的占位符,在会话运行时将始终被输入;还有变量,它们是可以更改的值。您可能已经知道,常量是不会改变的值。
代码行的结果是计算图中的抽象张量。然而,与你可能期望的相反,result实际上并没有计算。它只是定义了模型,但没有运行任何过程来计算结果。你可以在打印输出中看到这一点:实际上没有你想要的结果(即 30)。这意味着 TensorFlow 有一个惰性求值!
但是,如果您确实想查看结果,则必须在交互式会话中运行此代码。您可以通过几种方式执行此操作,如下面的 DataCamp Light 代码块所示:
- 脚本.py
10
- IPython Shell
在[1]中:跑步
请注意,您还可以使用以下代码行启动交互式会话,运行result并在打印后再次自动关闭会话output:
- 脚本.py
8
# 乘法
- IPython Shell
在[1]中:跑步
在上面的代码块中,您刚刚定义了一个默认会话,但您也应该知道,您也可以传入选项。例如,您可以指定参数config,然后使用ConfigProto协议缓冲区为您的会话添加配置选项。
例如,如果你添加
config=tf.ConfigProto(log_device_placement=True)在您的会话中,请确保记录分配给操作的 GPU 或 CPU 设备。然后,您将获得会话中每个操作使用的设备信息。您还可以使用以下配置会话,例如,当您对设备放置使用软约束时:
config=tf.ConfigProto(allow_soft_placement=True)现在您已经安装好了 TensorFlow 并将其导入到您的工作区,并且您已经了解了使用此软件包的基础知识,现在是时候将其放在一边,将注意力转向您的数据。与往常一样,在开始对神经网络进行建模之前,您首先需要花时间探索和更好地理解您的数据。
比利时交通标志:背景
尽管流量是大家普遍了解的一个话题,但在开始之前,简要回顾一下此数据集中包含的观察结果以查看您是否了解所有内容也无妨。本质上,在本节中,您将快速掌握继续学习本教程所需的领域知识。
当然,因为我是比利时人,所以我会确保你也会了解到一些轶事:)
- 比利时的交通标志通常使用荷兰语和法语。了解这一点很好,但对于您将要处理的数据集来说,这并不太重要!
- 比利时的交通标志分为六类:警告标志、优先标志、禁止标志、强制标志、与停车和道路静止相关的标志以及指示标志。
- 2017 年 1 月 1 日,比利时道路上拆除了 30,000 多个交通标志。这些标志全都是与超速有关的禁行标志。
- 谈到拆除,交通标志的大量存在一直是比利时(乃至整个欧盟)讨论的话题。
加载和探索数据
现在您已经收集了更多背景信息,是时候在此处下载数据集了。您应该获得“BelgiumTS for Classification(裁剪图像)”旁边列出的两个 zip 文件,分别称为“BelgiumTSC_Training”和“BelgiumTSC_Testing”。
提示:如果您已经下载了文件或将在完成本教程后下载,请查看您下载的数据的文件夹结构!您会看到测试和训练数据文件夹包含 61 个子文件夹,这些子文件夹是您将在本教程中用于分类的 62 种交通标志。此外,您会发现文件的文件扩展名为.ppmPortable Pixmap Format。您已下载交通标志的图像!
让我们开始将数据导入您的工作区。让我们从用户定义函数 (UDF) 下方的代码行开始:load_data()
- 首先,设置你的
ROOT_PATH。此路径是你用训练和测试数据创建的目录的路径。 ROOT_PATH接下来,您可以借助函数将特定路径添加到您的 中。您将这两个特定路径存储在和 中。join()train_data_directorytest_data_directory- 您会看到,之后您可以调用该函数并将其传递给它。
load_data()train_data_directory - 现在,函数本身首先收集 中存在的所有子目录;它借助列表推导式来实现这一点,这是一种非常自然的列表构建方式 – 它基本上是说,如果你在 中找到某个东西,你会仔细检查这是否是一个目录,如果是,你会将它添加到列表中。请记住,每个子目录代表一个标签。
load_data()train_data_directorytrain_data_directory - 接下来,您必须循环遍历子目录。首先初始化两个列表,
labels和images。接下来,收集子目录的路径以及存储在这些子目录中的图像的文件名。之后,您可以借助函数收集两个列表中的数据。append()
def load_data(data_directory):
directories = [d for d in os.listdir(data_directory)
if os.path.isdir(os.path.join(data_directory, d))]
labels = []
images = []
for d in directories:
label_directory = os.path.join(data_directory, d)
file_names = [os.path.join(label_directory, f)
for f in os.listdir(label_directory)
if f.endswith(".ppm")]
for f in file_names:
images.append(skimage.data.imread(f))
labels.append(int(d))
return images, labels
ROOT_PATH = "/your/root/path"
train_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Training")
test_data_directory = os.path.join(ROOT_PATH, "TrafficSigns/Testing")
images, labels = load_data(train_data_directory)请注意,在上述代码块中,训练和测试数据位于名为“Training”和“Testing”的文件夹中,这两个文件夹都是另一个目录“TrafficSigns”的子目录。在本地计算机上,这可能看起来像“/Users/Name/Downloads/TrafficSigns”,然后有两个名为“Training”和“Testing”的子文件夹。
提示:通过 DataCamp 的Python 函数教程回顾如何用 Python 编写函数。
交通标志统计
加载完数据后,就该进行一些数据检查了!您可以借助数组的ndim和size属性开始一个非常简单的分析images:
请注意,images和labels变量是列表,因此您可能需要使用将变量转换为您自己的工作区中的数组。这里已经为您完成了!np.array()
- 脚本.py
5
打印(图像.
尺寸)
- IPython Shell
在[1]中:跑步
请注意,您打印出来的实际上是一个由数组中的数组表示的图像!乍一看,这可能看起来违反直觉,但随着您在机器学习或深度学习应用程序中进一步处理图像,您就会习惯这一点。images[0]
接下来,您还可以稍微看一下labels,但此时您应该不会看到太多惊喜:
- 脚本.py
5
打印(标签.
尺寸)
- IPython Shell
在[1]中:跑步
这些数字已经让您了解导入的成功程度以及数据的确切大小。乍一看,一切都按您预期的方式执行,如果您考虑到您正在处理数组中的数组,您会发现数组的大小相当可观。
提示尝试将以下属性添加到您的数组中,以获取有关内存布局、一个数组元素的长度(以字节为单位)以及具有 、 和 属性的数组元素所消耗的总字节数的更多信息flags。itemsize您nbytes可以在上面的 DataCamp Light 块中的 IPython 控制台中对此进行测试!
接下来大家还可以看一下交通标志的分布情况:
- 脚本.py
1
plt.hist (
标签,62 )
- IPython Shell
在[1]中:跑步
太棒了!现在让我们仔细看看你制作的直方图!
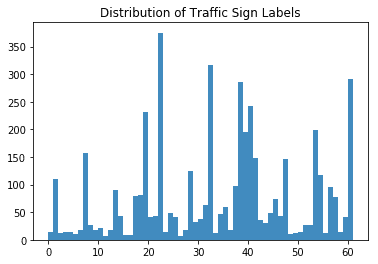
您清楚地看到,并非所有类型的交通标志都平等地出现在数据集中。这是您在开始对神经网络进行建模之前处理数据时要处理的问题。
乍一看,你会发现有些标签在数据集中出现的频率比其他标签更高:标签 22、32、38 和 61 绝对引人注目。此时,记住这一点是很好的,但你肯定会在下一节中进一步了解这一点!
可视化交通标志
之前的小分析或检查已经让您对正在处理的数据有了一些了解,但是当您的数据主要由图像组成时,您应该采取的探索数据的步骤就是对其进行可视化。
让我们看看一些随机交通标志:
- 首先,确保您导入了通用别名下的包
pyplot的模块。matplotlibplt - 然后,您将创建一个包含 4 个随机数的列表。这些将用于从您在上一节中刚刚检查过的数组中选择交通标志。
images在本例中,您将选择300、2250和。36504000 - 接下来,您将说对于该列表长度中的每个元素,即从 0 到 4,您将创建没有轴的子图(这样它们就不会占用所有注意力,而您的注意力将完全集中在图像上!)。在这些子图中,您将显示数组中
images与索引处的数字一致的特定图像i。在第一个循环中,您将传递300给,在第二轮中,您将传递给,依此类推。最后,您将调整子图,使它们之间有足够的宽度。images[]2250 - 剩下的最后一件事就是借助函数来展示你的情节!
show()
就是这样:
# Import the `pyplot` module of `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images that you want to see
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images that you defined
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()正如您根据该数据集中包含的 62 个标签所猜测的那样,这些标志彼此之间是不同的。
但你还注意到了什么?再仔细看看下面的图片:

这四张图片的尺寸不一样!
您显然可以摆弄traffic_signs列表中包含的数字,并更彻底地跟进这一观察结果,但无论如何,这是一个重要的观察结果,当您开始更多地致力于操纵数据以便将其提供给神经网络时,您需要考虑到这一点。
让我们通过打印包含在子图中的特定图像的形状、最小值和最大值来确认不同大小的假设。
下面的代码与您用来创建上述图表的代码非常相似,但不同之处在于,在这里,您将交替使用大小和图像,而不是仅仅绘制彼此相邻的图像:
# Import `matplotlib`
import matplotlib.pyplot as plt
# Determine the (random) indexes of the images
traffic_signs = [300, 2250, 3650, 4000]
# Fill out the subplots with the random images and add shape, min and max values
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images[traffic_signs[i]])
plt.subplots_adjust(wspace=0.5)
plt.show()
print("shape: , min: , max: ".format(images[traffic_signs[i]].shape,
images[traffic_signs[i]].min(),
images[traffic_signs[i]].max()))请注意如何在字符串上使用方法来填充您定义的参数、和。format()"shape: , min: , max: "

现在您已经看到了松散的图像,您可能还想重新查看在数据探索的第一步中打印出来的直方图;您可以通过绘制所有 62 个类的概览和属于每个类的一个图像来轻松做到这一点:
# Import the `pyplot` module as `plt`
import matplotlib.pyplot as plt
# Get the unique labels
unique_labels = set(labels)
# Initialize the figure
plt.figure(figsize=(15, 15))
# Set a counter
i = 1
# For each unique label,
for label in unique_labels:
# You pick the first image for each label
image = images[labels.index(label)]
# Define 64 subplots
plt.subplot(8, 8, i)
# Don't include axes
plt.axis('off')
# Add a title to each subplot
plt.title("Label ()".format(label, labels.count(label)))
# Add 1 to the counter
i += 1
# And you plot this first image
plt.imshow(image)
# Show the plot
plt.show()请注意,即使您定义了 64 个子图,也并非所有子图都会显示图像(因为只有 62 个标签!)。还请注意,您不会添加任何轴,以确保读者的注意力不会偏离主要主题:交通标志!

正如您在上面的直方图中基本猜到的那样,带有标签 22、32、38 和 61 的交通标志数量要多得多。这个假设现在在该图中得到了证实:您会看到带有标签 22 的实例有 375 个,带有标签 32 的实例有 316 个,带有标签 38 的实例有 285 个,最后带有标签 61 的实例有 282 个。
您现在可以问自己的一个最有趣的问题是,所有这些实例之间是否存在联系 – 也许它们都是指示符号?
让我们仔细看看:您会发现标签 22 和 32 是禁止标志,但标签 38 和 61 分别是指定标志和优先标志。这意味着这四个标志之间没有直接联系,除了数据集中存在大量标志的一半属于禁止标志这一事实。
特征提取
现在您已经彻底探索了数据,是时候开始动手了!让我们简要回顾一下您发现的内容,以确保您不会忘记操作中的任何步骤:
- 图像大小不一致;
- 有 62 个标签或目标值(因为您的标签从 0 开始到 61 结束);
- 交通标志值的分布非常不均匀;数据集中大量出现的标志之间实际上没有任何联系。
现在您已经清楚自己需要改进的地方,您可以开始处理数据,使其可以输入到神经网络或您想要输入的任何模型中。首先,让我们从提取一些特征开始 – 您将重新缩放图像,并将数组中保存的图像转换images为灰度。您之所以进行这种颜色转换,主要是因为颜色在分类问题(例如您现在尝试回答的问题)中并不那么重要。然而,对于检测来说,颜色确实起着重要作用!因此,在这些情况下,不需要进行这种转换!
重新缩放图像
为了解决不同的图像大小,您需要重新缩放图像;您可以借助skimage或 Scikit-Image 库(它是用于图像处理的算法的集合)轻松完成此操作。
在这种情况下,transform模块会派上用场,因为它为您提供了一个功能;您将看到您再次使用列表推导式来将每幅图像的大小调整为 28 x 28 像素。再一次,您会看到您实际形成列表的方式:对于您在数组中找到的每幅图像,您将执行从库中借用的转换操作。最后,您将结果存储在变量中:resize()imagesskimageimages28
# Import the `transform` module from `skimage`
from skimage import transform
# Rescale the images in the `images` array
images28 = [transform.resize(image, (28, 28)) for image in images]这相当容易不是吗?
请注意,图像现在是四维的:如果您将其转换images28为数组并将属性连接shape到它,您将看到打印输出告诉您images28的尺寸为。图像是 784 维的(因为您的图像是 28 x 28 像素)。(4575, 28, 28, 3)
您可以通过重新使用上面使用的代码来检查重新缩放操作的结果,在变量的帮助下绘制 4 张随机图像traffic_signs。但不要忘记将所有对 的引用更改images为images28。
在这里查看结果:
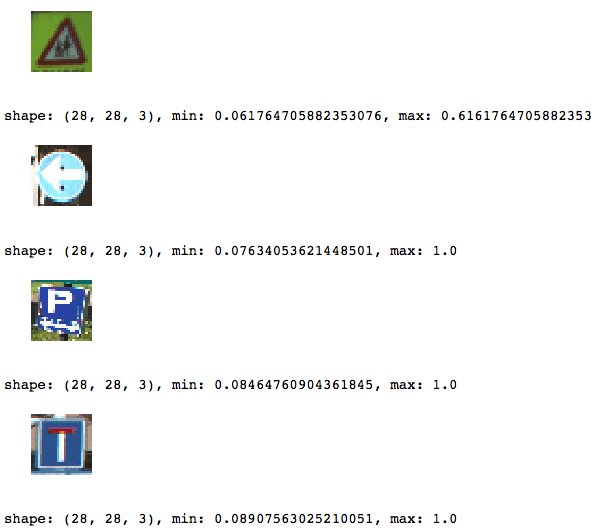
请注意,由于您重新缩放了比例,您的min和max值也发生了变化;它们现在似乎都在相同的范围内,这非常好,因为您不一定需要规范化您的数据!
图像转换为灰度
正如本教程本部分的介绍中所述,当您尝试回答分类问题时,图片中的颜色并不那么重要。这就是为什么您还要费力地将图片转换为灰度图。
但请注意,如果您不执行此特定步骤,您也可以自行测试模型的最终结果会发生什么。
就像重新缩放一样,您可以再次依靠 Scikit-Image 库来帮助您;在这种情况下,您需要使用color具有其功能的模块来到达您需要的位置。rgb2gray()
这将会非常轻松和顺利!
但是,不要忘记将images28变量转换回数组,因为该函数确实需要数组作为参数。rgb2gray()
# Import `rgb2gray` from `skimage.color`
from skimage.color import rgb2gray
# Convert `images28` to an array
images28 = np.array(images28)
# Convert `images28` to grayscale
images28 = rgb2gray(images28)通过绘制一些图像来仔细检查灰度转换的结果;在这里,您可以再次重复使用并稍微调整一些代码来显示调整后的图像:
import matplotlib.pyplot as plt
traffic_signs = [300, 2250, 3650, 4000]
for i in range(len(traffic_signs)):
plt.subplot(1, 4, i+1)
plt.axis('off')
plt.imshow(images28[traffic_signs[i]], cmap="gray")
plt.subplots_adjust(wspace=0.5)
# Show the plot
plt.show()请注意,您确实必须指定颜色图或cmap并将其设置为"gray"以灰度绘制图像。这是因为默认情况下,默认使用类似热图的颜色图。在此处阅读更多信息。imshow()

提示:由于您在本教程中多次重复使用此功能,因此您可以研究如何将其变成一个函数:)
这两个步骤非常基本;您可以尝试对数据进行的其他操作包括数据增强(旋转、模糊、移动、更改亮度等)。如果您愿意,您还可以设置一整套数据处理操作流程,通过这些流程发送图像。
使用 TensorFlow 进行深度学习
现在您已经探索和处理了数据,是时候在 TensorFlow 包的帮助下构建您的神经网络架构了!
神经网络建模
就像你使用 Keras 所做的那样,现在是时候逐层构建你的神经网络了。
如果您还没有这样做,请tensorflow以常规别名 导入到您的工作区tf。然后,您可以借助 初始化 Graph 。您可以使用此函数来定义计算。请注意,使用 Graph,您无需计算任何内容,因为它不包含任何值。它只是定义您稍后要运行的操作。Graph()
在这种情况下,您可以借助 来设置默认上下文,这将返回一个上下文管理器,使此特定图形成为默认图形。如果您想在同一进程中创建多个图形,可以使用此方法:使用此函数,您将拥有一个全局默认图形,如果您没有明确创建新图形,则所有操作都将添加到该图形中。as_default()
接下来,您就可以向图表添加操作了。您可能还记得,在使用 Keras 时,您需要构建模型,然后在编译模型时定义损失函数、优化器和指标。现在,当您使用 TensorFlow 时,所有这些都只需一步即可完成:
- 首先,您要为输入和标签定义占位符,因为您还不会输入“真实”数据。请记住,占位符是未分配的值,当您运行会话时,它们将由会话初始化。因此,当您最终运行会话时,这些占位符将获取您在函数中传递的数据集的值!
run() - 然后,你就可以建立网络了。首先,借助函数将输入展平,这将为你提供一个形状数组,而不是灰度图像的形状。
flatten()[None, 784][None, 28, 28] - 在将输入展平后,构建一个完全连接的层,该层生成大小为 的对数。Logits 是对前几层的未缩放输出进行操作的函数,它使用相对比例来理解单位是线性的。
[None, 62] - 构建多层感知器后,您可以定义损失函数。损失函数的选择取决于您手头的任务:在本例中,您可以使用
sparse_softmax_cross_entropy_with_logits()- 这计算了 logits 和标签之间的稀疏 softmax 交叉熵。换句话说,它测量了类别互斥的离散分类任务中的概率误差。这意味着每个条目都只属于一个类。在这里,一个交通标志只能有一个标签。请记住,虽然回归用于预测连续值,但分类用于预测离散值或数据点的类别。您可以使用 包装此函数,它计算张量各个维度元素的平均值。
reduce_mean() - 您还需要定义一个训练优化器;一些最流行的优化算法是随机梯度下降 (SGD)、ADAM 和 RMSprop。根据您选择的算法,您需要调整某些参数,例如学习率或动量。在本例中,您选择 ADAM 优化器,并将其学习率定义为
0.001。 - 最后,在进行训练之前,初始化要执行的操作。
# Import `tensorflow`
import tensorflow as tf
# Initialize placeholders
x = tf.placeholder(dtype = tf.float32, shape = [None, 28, 28])
y = tf.placeholder(dtype = tf.int32, shape = [None])
# Flatten the input data
images_flat = tf.contrib.layers.flatten(x)
# Fully connected layer
logits = tf.contrib.layers.fully_connected(images_flat, 62, tf.nn.relu)
# Define a loss function
loss = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels = y,
logits = logits))
# Define an optimizer
train_op = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
# Convert logits to label indexes
correct_pred = tf.argmax(logits, 1)
# Define an accuracy metric
accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32))您现在已经成功使用 TensorFlow 创建了您的第一个神经网络!
如果需要,您还可以打印出(大多数)变量的值,以快速回顾或检查刚刚编写的内容:
print("images_flat: ", images_flat)
print("logits: ", logits)
print("loss: ", loss)
print("predicted_labels: ", correct_pred)提示:如果您看到类似“ ”的错误,请考虑通过在命令行中运行来升级软件包。有关更多信息,请参阅此 StackOverflow 帖子。module 'pandas' has no attribute 'computation'daskpip install --upgrade dask
运行神经网络
现在您已经逐层构建了模型,是时候实际运行它了!为此,您首先需要借助 初始化一个会话,您可以将上一节中定义的传递给该会话。接下来,您可以使用 运行会话,将初始化的操作以变量的形式传递给该会话,变量也是您在上一节中定义的。Session()graphrun()init
接下来,您可以使用这个初始化的会话来启动 epoch 或训练循环。在这种情况下,您选择 是201因为您希望能够注册最后一个loss_value;在循环中,您使用训练优化器和您在上一节中定义的损失(或准确度)指标运行会话。您还可以传递一个feed_dict参数,使用该参数将数据提供给模型。每 10 个 epoch 之后,您将获得一个日志,该日志可让您更深入地了解模型的损失或成本。
正如您在 TensorFlow 基础知识部分中看到的,无需手动关闭会话;这是为您完成的。但是,如果您想尝试不同的设置,您可能需要这样做,如果您已将会话定义为,如下面的代码块所示:sess.close()sess
tf.set_random_seed(1234)
sess = tf.Session()
sess.run(tf.global_variables_initializer())
for i in range(201):
print('EPOCH', i)
_, accuracy_val = sess.run([train_op, accuracy], feed_dict={x: images28, y: labels})
if i % 10 == 0:
print("Loss: ", loss)
print('DONE WITH EPOCH')请记住,您也可以运行以下一段代码,但该代码随后会立即关闭会话,就像您在本教程的介绍中看到的那样:
tf.set_random_seed(1234)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(201):
_, loss_value = sess.run([train_op, loss], feed_dict={x: images28, y: labels})
if i % 10 == 0:
print("Loss: ", loss)请注意,您之所以使用是因为该功能已被弃用。global_variables_initializer()initialize_all_variables()
现在您已成功训练了模型!这不太难,不是吗?
评估你的神经网络
您还没有完全达到目标;您仍然需要评估您的神经网络。在这种情况下,您可以通过挑选 10 张随机图像并将预测标签与真实标签进行比较来尝试了解您的模型表现如何。
您可以先将它们打印出来,但为什么不用matplotlib来绘制交通标志本身并进行视觉比较呢?
# Import `matplotlib`
import matplotlib.pyplot as plt
import random
# Pick 10 random images
sample_indexes = random.sample(range(len(images28)), 10)
sample_images = [images28[i] for i in sample_indexes]
sample_labels = [labels[i] for i in sample_indexes]
# Run the "correct_pred" operation
predicted = sess.run([correct_pred], feed_dict={x: sample_images})[0]
# Print the real and predicted labels
print(sample_labels)
print(predicted)
# Display the predictions and the ground truth visually.
fig = plt.figure(figsize=(10, 10))
for i in range(len(sample_images)):
truth = sample_labels[i]
prediction = predicted[i]
plt.subplot(5, 2,1+i)
plt.axis('off')
color='green' if truth == prediction else 'red'
plt.text(40, 10, "Truth: nPrediction: ".format(truth, prediction),
fontsize=12, color=color)
plt.imshow(sample_images[i], cmap="gray")
plt.show()
但是,仅查看随机图像并不能让您深入了解模型的实际性能。这就是您需要加载测试数据的原因。
请注意,您使用了在本教程开始时定义的函数。load_data()
# Import `skimage`
from skimage import transform
# Load the test data
test_images, test_labels = load_data(test_data_directory)
# Transform the images to 28 by 28 pixels
test_images28 = [transform.resize(image, (28, 28)) for image in test_images]
# Convert to grayscale
from skimage.color import rgb2gray
test_images28 = rgb2gray(np.array(test_images28))
# Run predictions against the full test set.
predicted = sess.run([correct_pred], feed_dict={x: test_images28})[0]
# Calculate correct matches
match_count = sum([int(y == y_) for y, y_ in zip(test_labels, predicted)])
# Calculate the accuracy
accuracy = match_count / len(test_labels)
# Print the accuracy
print("Accuracy: {:.3f}".format(accuracy))如果您没有使用来启动 TensorFlow 会话,请记得关闭会话。sess.close()with tf.Session() as sess:
下一步去哪儿?
如果您想继续使用该数据集和本教程中整理的模型,请尝试以下操作:
- 在将数据输入模型之前,先对数据应用正则化 LDA。这是来自原始论文之一的建议,该论文由收集和分析此数据集的研究人员撰写。
- 正如教程本身所述,您还可以查看可以在交通标志图像上执行的一些其他数据增强操作。此外,您还可以尝试进一步调整此网络;您现在创建的网络相当简单。
- 提前停止:在训练神经网络时跟踪训练和测试误差。当两个误差都下降然后突然回升时停止训练 – 这表明神经网络已开始过度拟合训练数据。
- 尝试使用优化器。
请务必查看Nishant Shukla 撰写的《使用 TensorFlow 进行机器学习》一书。
提示:还可以查看TensorFlow Playground和TensorBoard。

