本文最后由 Demo Marco 更新于 2025-02-22. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】

在本文中,我们将探讨五个生成式 AI 项目,它们将帮助您构建和加强机器学习和数据科学组合。这些项目旨在增强您对 Stable Diffusion、Segment Anything、LangChain、Alpaca-LoRA 等尖端技术的理解。
无论您是生成式人工智能的新手还是已经有一些经验,这些项目都将为您提供宝贵的技能,让您在求职和面试中脱颖而出。
您可以通过阅读文章“什么是 GPT-4 以及它为什么重要? ”来了解 GPT 系列,包括 GPT-1、GPT-2、GPT-3 和 GPT-4。您还可以在单独的文章中查看其他一些AI 项目。
1. StableSAM:使用 Segment Anything 进行稳定扩散修复
在这个项目中,您将使用 Meta 的“segment-anything”、“Hugging Face扩散器”和 Gradio 来创建一个可以更改背景、面部、衣服或您选择的任何其他内容的应用程序。它只需要图像、选定区域和提示。
用例:
StableSAM 非常适合数字营销、设计和娱乐行业的创意专业人士。它允许用户精确编辑图像的特定部分,非常适合更改背景、改变服装或修改宣传材料中的对象等任务。对于业余爱好者来说,这是一个很棒的图像定制工具,无需高级设计技能。
您将学到的技能:
- 使用稳定扩散实现图像修复管道
- 使用 Meta 的 Segment Anything 模型 (SAM) 进行图像分割
- 使用 Gradio 创建交互式 Web 应用程序
- 使用 Hugging Face 扩散器进行模型部署
创建稳定的扩散修复管道
我们将使用稳定扩散修复管道,使用稳定扩散修复管道(stableai/stable-diffusion-2-inpainting · Hugging Face上提供的扩散器和模型权重。之后,我们将把它添加到 CUDA 以实现 GPU 加速。
定义图像蒙版和修复函数
图像掩码函数是使用 SAM Predictor 创建的。它采用图像、选定的图像部分和is_backgroud布尔值来创建掩码图像和分割。
之后,修复函数使用稳定扩散修复管道来更改图像的选定部分。管道需要输入图像、蒙版图像、分割图像、提示文本和负面提示文本。
创建 Gradio UI
您将创建一行并添加三个图像块。对于最小可行产品,您必须添加另一行并添加提交按钮。之后,您必须修改输入图像对象以选择像素、生成蒙版和分割,并向提交按钮添加操作以运行修复功能。
Gradio 非常容易学习。你可以通过阅读Gradio 文档来学习所有内容。
StableSAM 的改进版本
Hugging Face提供 StableSAM 的改进版本,其中包括使用 ControlNet 的定制修复管道。它使用 Runway ML Stable Diffusion Inpainting 而不是 Stability AI。
如您所见,最终版本的应用程序看起来很干净,具有分割块、清洁按钮、背景选项和负面提示。
资源:
- 拥抱脸演示:StableSAM
- Youtube 教程:使用 Segment Anything 模型 (SAM) 进行稳定扩散修复
2. Alpaca-LoRA:用最少的资源构建类似 ChatGPT 的聊天机器人
Alpaca-LoRA 为您提供了所有必要的组件,让您使用单个 GPU 创建自己的类似 ChatGPT 的专用聊天机器人。在此项目中,我们将研究初始设置、训练、推理脚本和在 CPU 上运行推理的本机客户端。
用例:
对于那些有兴趣构建定制对话式 AI 系统的人来说,这个项目是极佳的选择。无论您是为小型企业创建客户服务聊天机器人还是开发个人助理,Alpaca-LoRA 都提供了一种使用有限计算资源训练专用聊天机器人的有效方法。这个项目非常适合在预算内尝试语言模型微调。
您将学到的技能:
- 在单个 GPU 上使用 LoRA 微调语言模型
- 设置和使用斯坦福羊驼数据集
- 在低资源环境(例如 Raspberry Pi)上运行推理脚本
- 部署基于 Gradio 的聊天机器人界面
- 了解如何训练和优化像 LLaMA 这样的大型语言模型
本地设置
- 克隆存储库:tloen/alpaca-lora
- 使用安装依赖项
pip install -r requirements.txt - 如果 bitsandbytes 不起作用,请从源安装它。
训练
在本部分中,我们将研究使用清理后的斯坦福羊驼模型在 LLaMA 模型上运行的微调脚本。
您可以查看存储库来调整超参数,以获得更好的性能。
python finetune.py
--base_model 'decapoda-research/llama-7b-hf'
--data_path 'yahma/alpaca-cleaned'
--output_dir './lora-alpaca'推理
推理脚本从 Hugging Face 读取基础 LLaMA 模型并加载 LoRA 权重以运行 Gradio 接口。
python generate.py
--load_8bit
--base_model 'decapoda-research/llama-7b-hf'
--lora_weights 'tloen/alpaca-lora-7b'您还可以使用alpaca.cpp在 CPU 或 4GB RAM Raspberry Pi 4 上运行羊驼模型。此外,您可以使用Alpaca-LoRA-Serve创建 ChatGPT 风格的界面,如下所示。
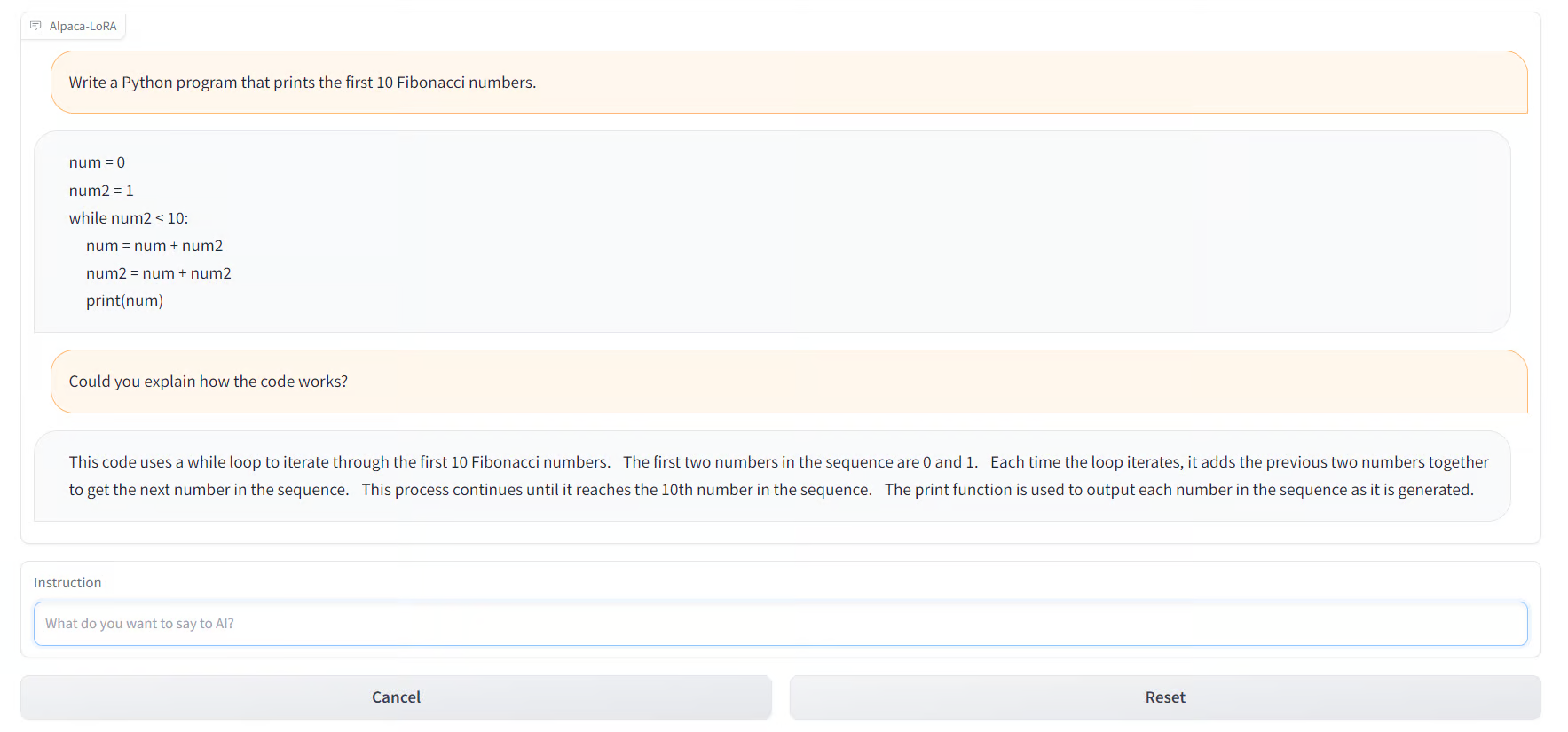
资源:
- GitHub:tloen/alpaca-lora
- 模型卡:tloen/alpaca-lora-7b
- Hugging Face 演示:Alpaca-LoRA-Serve
- ChatGPT 风格的界面:Alpaca-LoRA-Serve
- 羊驼数据集:AlpacaDataCleaned
3. 使用 LangChain 和 ChatGPT 实现 PDF 交互自动化
使用 LangChain 的 PDF 加载器、OpenAI 嵌入和 GPT-3.5创建您自己的ChatPDF克隆。您将创建一个可以与您的书籍、法律文档和其他重要 PDF 文档进行通信的聊天机器人。
用例:
该项目可用于自动化基于文档的工作流程,例如分析研究论文、法律合同或财务报告。您可以构建一个聊天机器人来回答有关 PDF 文档的特定问题,这在法律、学术或商业智能等需要处理大量文本的行业中可能是一个强大的工具。
您将学到的技能:
- 使用 LangChain 的 PyPDFLoader 加载和处理 PDF 文档
- 使用 OpenAIEmbeddings 创建嵌入并矢量化文档数据
- 使用 Chroma 构建用于文档查询的矢量数据库
- 将 ChatGPT 与矢量数据集成以进行问答
- 使用 Gradio 开发简单的 PDF 聊天机器人界面
加载文档
我们将使用 LangChain 文档加载器来加载 PDF 并读取内容。
from langchain.document_loaders import PyPDFLoader
pdf_path = "./paper.pdf"
loader = PyPDFLoader(pdf_path)
pages = loader.load_and_split()
print(pages[0].page_content)创建嵌入和矢量化
我们将使用 LangChain API 中的类创建嵌入OpenAIEmbeddings。之后,将这些嵌入传递给Chroma类以创建 PDF 文档的矢量数据库。
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
embeddings = OpenAIEmbeddings()
vectordb = Chroma.from_documents(pages, embedding=embeddings, persist_directory=".")
vectordb.persist()查询 PDF
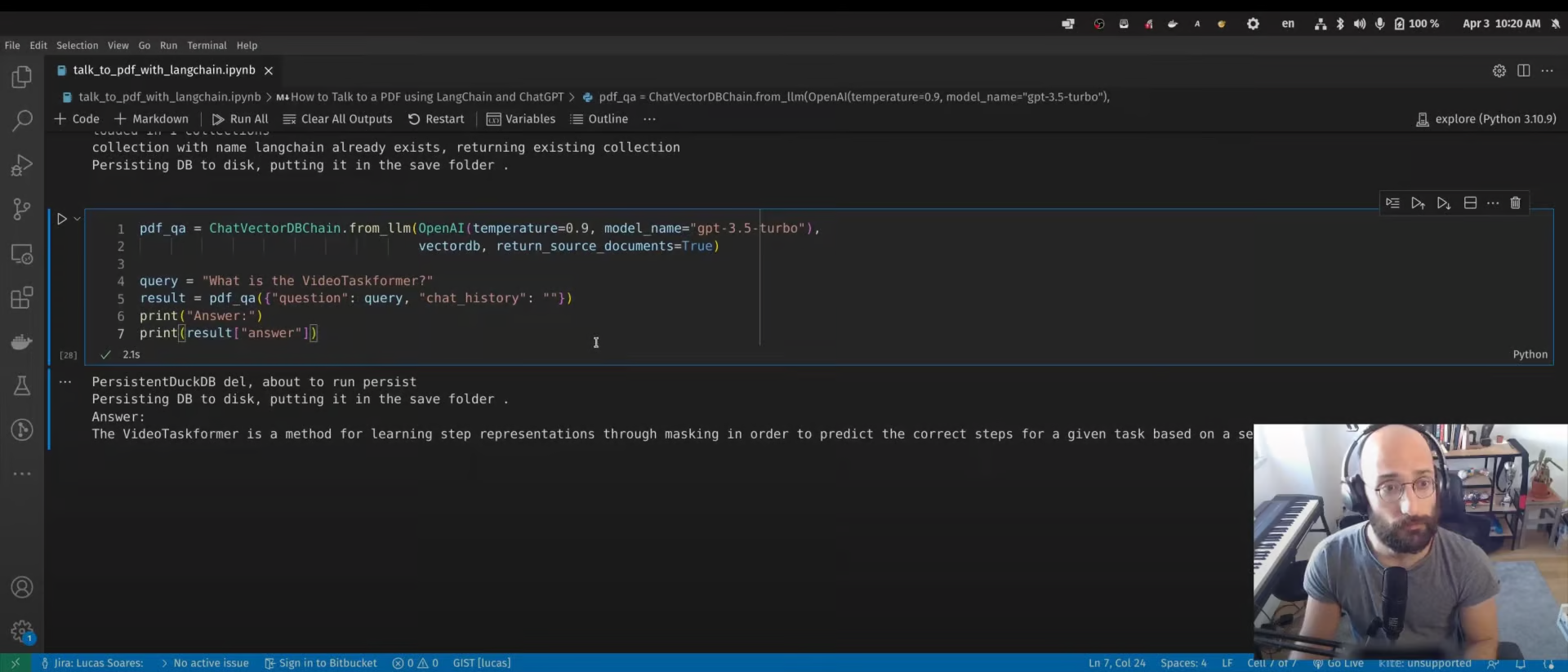
我们将使用该类ChatVectorDBChain通过生成的矢量数据库与 ChatGPT 进行交互。
from langchain.chains import ChatVectorDBChain
from langchain.llms import OpenAI
pdf_qa = ChatVectorDBChain.from_llm(
OpenAI(temperature=0.9, model_name="gpt-3.5-turbo"),
vectordb,
return_source_documents=True,
)
query = "What is the VideoTaskformer?"
result = pdf_qa({"question": query, "chat_history": ""})
print("Answer:")
print(result["answer"])视频教程中没有提到下一步。您可以使用 Gradio 框架创建一个 Web 应用程序并与同事和朋友共享。
资源:
- Youtube 教程:如何使用 LangChain 和 ChatGPT 与 PDF 对话
- 带代码来源的博客:使用 LangChain 和 ChatGPT 实现 PDF 交互自动化
- 另外,请查看:使用 LangChain 与您的 CSV 和 Excel 对话
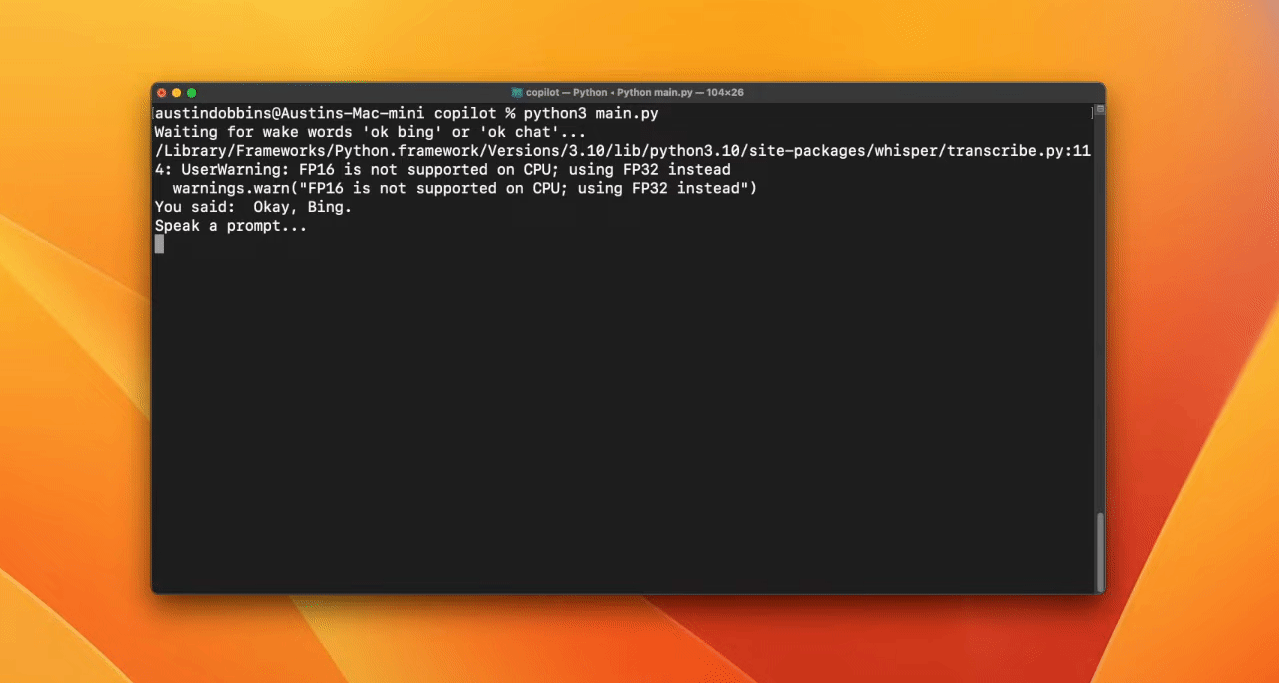
4. Bing-GPT 语音助手
构建您自己的像 JARVIS 一样的 AI 个人助理为此,您将需要 OpenAI API、文本到语音库、语音识别库和生成 AI。
用例:
Bing-GPT 语音助手非常适合构建语音控制的 AI 个人助理,可以处理设置提醒、回答问题或控制智能家居设备等任务。该项目还可以扩展以实现业务自动化、创建基于语音的客户服务解决方案或为残障人士构建可访问的 AI 工具。
您将学到的技能:
- 使用 OpenAI 的 API 生成聊天机器人响应
- 使用 Whisper 和 Polly 实现语音合成和识别
- 为基于语音的交互设置唤醒词检测
- 使用 EdgeGPT 和 ChatGPT 构建混合 AI 助手
- 在 Python 中集成文本转语音和语音识别技术
加载所需的库后,您必须提供 OpenAI API 密钥:
openai.api_key = "[paste your OpenAI API key here]"唤醒词
创建唤醒词功能以激活 AI。在本例中,开发人员使用“bing”或“gpt”。
语音合成
语音合成功能提供文本转语音推理。您可以从boto3访问 polly(文本转语音)并使用pydub播放音频。
使用 Whisper 进行转录
语音识别由openai/whisper完成。你只需要弄清楚 API 即可将其添加到你的应用程序中。
使用 EdgeGPT 的聊天机器人
最后,您将使用acheong08/EdgeGPT和OpenAI API创建一个聊天机器人。如果用户使用唤醒词“bing”,它将使用 EdgeGPT 模型,否则将使用 ChatGPT 模型。
如果您正在寻找更简单的语音助手实现,请查看OpenAI Whisper、ChatGPT、TTS 和 Gradio Web UI。
资源:
- Youtube 教程:7 分钟内创建 ChatGPT 和 Bing 语音助手
- GitHub:Ai-Austin/Bing-GPT-Voice-Assistant
- 替代解决方案:youtube-stuffs/voiceGPT.ipynb
5. 端到端数据科学项目
在这个项目中,我们将使用ChatGPT开发端到端贷款审批分类器应用程序。我们所需要的只是访问 ChatGPT 界面和一台个人机器来运行代码。
用例:
该项目专为有志于使用 AI 构建功能齐全的机器学习管道的数据科学家而设计。您将学习如何使用 ChatGPT 规划、执行和部署机器学习模型,使其成为任何数据科学组合的绝佳补充。使用此项目可以预测贷款批准、客户流失预测或欺诈检测。
您将学到的技能:
- 使用 ChatGPT 协助进行探索性数据分析 (EDA)
- 自动化特征工程和数据预处理任务
- 在 ChatGPT 的帮助下构建和调整机器学习模型
- 使用 Gradio 创建机器学习 Web 应用程序
项目规划
在规划阶段,我们将描述数据集以及我们想要从中得到什么。有时答案并不完美,但您可以通过提供后续提示来调整答案。
此后,我们将开始按照简要计划进行。
探索性数据分析 (EDA)
我们将要求 ChatGPT 生成 Python 代码,该代码将加载数据集并使用各种可视化技术执行探索性数据分析。您甚至可以要求它解释结果。
特征工程
我们让 ChatGPT 编写了特征工程代码,令人惊讶的是,它从现有特征中创建了两个特征。这意味着 AI 现在完全理解了数据集。
预处理和平衡数据
我们有一个不平衡的数据集,在这一部分,我们将使用 ChatGPT 生成预处理和类平衡代码。
模型选择
我们刚刚要求 ChatGPT 通过指定机器学习模型来编写模型选择代码。运行代码后,我们将选择表现最佳的模型。
超参数调整和模型评估
为了提高性能,我们将要求 ChatGPT 编写 Python 代码进行超参数调整和模型评估,并保存表现最佳的模型。
使用 Gradio 创建 Web 应用程序
我们将要求 ChatGPT 使用保存的模型和预处理编写 Gradio 应用程序代码。AI 理解输入特征并输出结果。因此,我们得到了一个功能齐全的 Web 应用程序。
在 Spaces 上部署 Web 应用程序
在最后一步,我们要求 ChatGPT 在空间上部署一个 Web 应用程序。它提供了几个步骤,我们可以按照这些步骤在几分钟内完成部署。
该项目还将教授编写有效提示的技巧,这对每个领域都变得至关重要。
结论
这只是生成式 AI 模型未来的开始。开源社区正在努力开发可帮助您构建任何类型的 AI 的工具。您甚至可以使用这些工具来创建 AGI(通用人工智能);查看Auto-GPT(用于创建完全自主的 GPT-4 的实验性开源)和babyagi(AI 驱动的任务管理系统)。
在这篇文章中,我们介绍了各个层次的人都能理解且入门所需的资源较少的项目。它们都使用了任何人都可以使用的开源工具、模型、数据集和软件包。
如果您是 ChatGPT 新手,可以继续ChatGPT 简介。或者,如果您已经熟悉生成式 AI,则可以通过查看全面的ChatGPT 数据科学备忘单或查看以下资源来提高您的提示技能:
常见问题解答
如果我是机器学习和人工智能的新手,我可以完成这些生成式人工智能项目吗?
当然!虽然有些项目可能涉及高级工具和技术,但博客文章中提供的分步说明将指导您完成整个过程。您无需成为专家即可开始使用,许多工具(如 Gradio、Hugging Face 和 LangChain)的设计都适合初学者。此外,这些项目将帮助您在 AI 方面打下坚实的基础,让您将来更轻松地解决更复杂的主题。
我是否需要高端 GPU 来运行这些生成式 AI 项目?
不一定。有些项目(例如 Alpaca-LoRA)设计为在单个 GPU 甚至 CPU 上运行,这意味着您不需要高端机器即可完成它们。对于需要更多计算能力的项目,您可以使用基于云的服务,例如 Google Colab、AWS 或 Hugging Face Spaces,这些服务可以免费或以低成本提供对 GPU 的访问。
我该如何在作品集里展示这些人工智能项目,以在求职中脱颖而出?
这些项目非常适合在您的作品集中展示,因为它们突显了您使用尖端 AI 工具的能力。将它们添加到您的作品集时,请务必:
- 包括项目的详细解释,描述您解决的问题、使用的工具和最终结果。
- 分享现场演示或 GitHub 存储库的链接,以便潜在雇主可以看到您的实际工作。
- 强调您遇到的任何独特挑战以及您如何解决这些挑战,这体现了解决问题和批判性思维的能力。

