本文最后由 Demo Marco 更新于 2025-02-22. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】

Google AI 和 OpenAI 都有发布尖端 AI 技术的历史。然而,随着ChatGPT 的推出,形势发生了变化,这引发了一场新的竞赛,谷歌等大型科技公司都在拼命推出类似的 AI 模型。
在这篇文章中,我们将了解 OpenAI 和 Google AI 的最新发展以及我们对未来的期望。此外,我们还将了解人工智能的进步如何改变数据科学领域,以及我们如何利用它来提高生产力。
OpenAI
OpenAI API是一个平台,它允许我们通过 API 访问尖端的生成模型。我们可以使用 DALLE-2 生成高质量图像,使用 GPT-3 生成文本和代码,并使用嵌入执行其他与语言相关的任务。此外,它还允许您调整结果、添加速率限制以及在特定数据集上微调模型。阅读我们的GPT-3 初学者指南博客,了解 GPT-3。
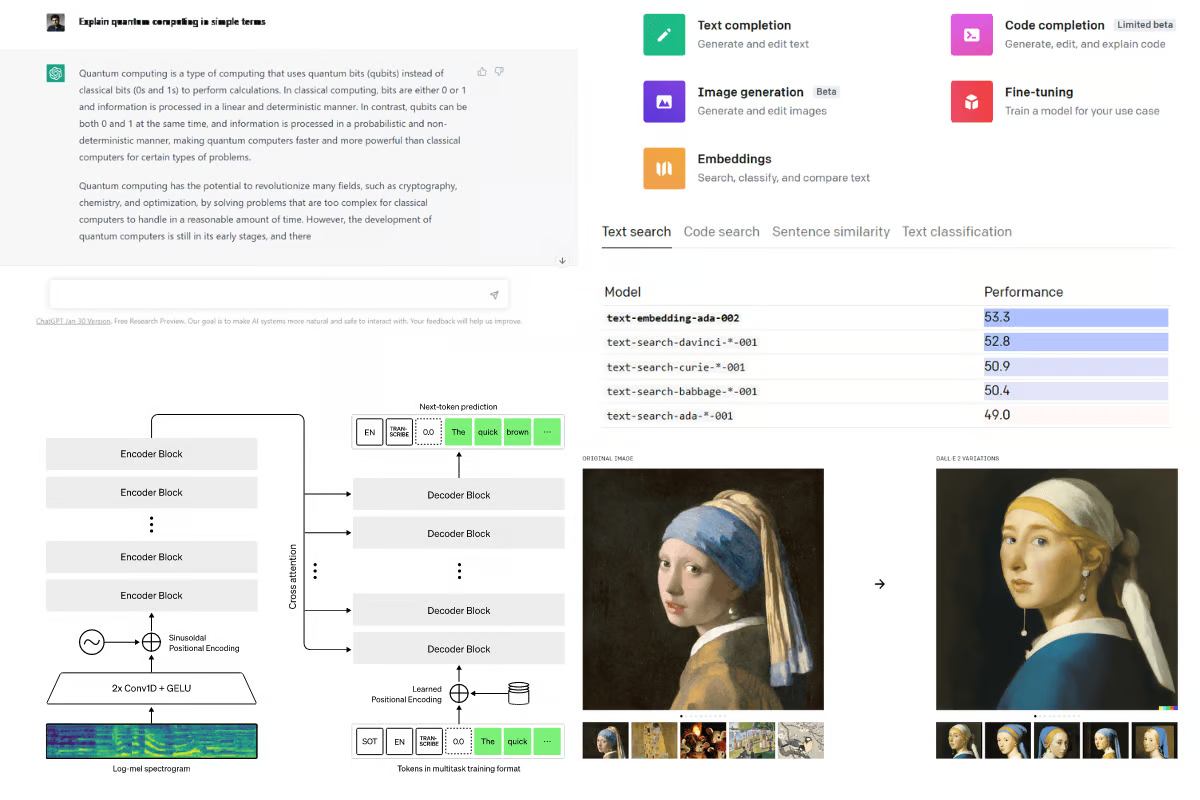
图片来源:作者 | 来源:OpenAI
这些都是商业产品,遵循现收现付模式,但 OpenAI 不时会发布开源工具和模型,例如:
- Whisper:采用大规模弱监督的语音识别模型。
- OpenAI Baselines:强化学习算法的实现。
- Gym:用于开发和评估强化学习算法的工具包。
- GPT2:论文《语言模型是无监督的多任务学习者》的代码和模型实现
- DALL-E:用于 DALL·E 的离散 VAE 的 PyTorch 包
API、工具包和大型语言模型都很棒,但它们无法接近ChatGPT的成功。
ChatGPT 模型使用人类反馈强化学习 (RLHF) 进行训练,类似于InstructGPT(GPT-3 的更好版本),但数据收集阶段略有不同。
它与前几代模型有何不同?对话 AI 能够提出后续问题、质疑错误的前提、承认错误并展示安全缓解措施。
近日,OpenAI合作伙伴微软推出了ChatGPT的改进版本,随着OpenAI的迭代部署,我们可以看到新一波能够理解我们的需求并为我们提供帮助的AI技术。
GPT-4
除了ChatGPT,我们期待GPT-4,这将是最先进的大型语言模型。在Greylock播客中,OpenAI首席执行官Sam Altman透露了一些有关GPT-4的信息。他表示,推特上关于GPT-4的传言都是假的,它不会有100万亿个参数,人们只会失望。他还透露,“当我们认为GPT-4安全且可用时,我们就会发布它”。

作者图片
您对 GPT-4 有何期待?
- 模型尺寸不会比GPT-3大太多。
- 使用新的参数化(μP)优化大型模型。
- 模型训练将使用最佳计算,通过增加训练令牌的数量来达到最小损失。
- 它将是一个纯文本模型。GPT-4 不会像 DALL-E 2 那样具有多模式性。
- 它可能利用稀疏性来降低计算成本。
- 就像 ChatGPT 一样,它将更加符合人工智能,遵循我们的意图并坚持我们的价值观。
通过阅读我们迄今为止对 GPT-4 所了解的一切文章,了解有关 GPT-1、GPT-2、GPT-3 和 GPT-4 的所有信息。
创造安全的 AGI
在接受StrictlyVC采访时,Altman 透露了我们在 AGI(通用人工智能)开发方面取得的进展的几点。
他说:“我们越接近目标,就越难回答。因为我认为,这个过渡过程会比人们想象的更加模糊,也更加渐进。”
他还驳斥了有关 AGI 的谣言。在采访中,他表示 OpenAI 没有能够像人类一样学习的 AGI。
作者图片
OpenAI 正在开发安全的 AGI,但还远远不够完美。人们谈论的 AGI 是一种可以理解语音、文本、图像和视频的多模态模型。它将是 ChatGPT、DALLE-2、Whisper、视频生成模型和其他强化学习算法的组合。
多模态模型
为了开发 AGI,OpenAI 需要研究多模态模型,不仅仅是文本转图像,还包括文本转视频、音频转视频和音频。这意味着你将能够与一个声音和外观自然的机器人交谈。一些开发人员已经实现了这一点,例如AI 生成的Twitch 主播角色。它并不完美,但它是一个开始。
在 StrictlyVC 节目期间,Sam Altman 透露他们正在开发视频模型,我们可以放心地假设它将是带有音频模型的文本到视频生成,这又增加了一层复杂性。我们已经有了一种视频生成技术,开发人员正在使用稳定扩散模型重叠生成的帧。
谷歌人工智能
Google AI是 Google 生态系统的支柱。它用于 Google 地图、照片、应用程序和 Cloud。Google 一直处于开发 AI 工具和模型的前沿。大多数产品都可以在Google Cloud上使用,从 AutoML 到最先进的大型视觉和语言模型。
它还发布了多个工具和最先进的模型,改变了自然语言处理、语音处理和计算机视觉领域。从 TensorFlow 到 BERT(来自 Transformers 的双向编码器表示),谷歌为人工智能和机器学习研发开辟了一条新道路。

来自LaMDA的 Gif
2020 年,谷歌研究部门推出了Meena,这是一种神经对话模型,可以理解上下文并学会明智地做出反应。此后,谷歌发布了与 ChatGPT 类似的LaMDA模型。这是一项突破性的对话技术,使用 transformer 构建,但经过对话训练。
每年,我们都会看到谷歌推出的新技术,未来,我们可以期待由 AI Bard、语言、视觉、生成模式和多模型驱动的先进谷歌搜索引擎,让人工智能实现多用途。
谷歌人工智能诗人
ChatGPT 推出后,人们开始散布谣言,称它是“谷歌杀手”。微软和 OpenAI之间的长期合作关系使这一说法更有可能实现。微软已准备好利用其融合 OpenAI 的 Bing 在搜索引擎业务上与谷歌展开竞争。
为了应对这种情况,谷歌推出了自己的 ChatGPT 版本,名为 Google AI Bard。
Bard的 Gif和新的 AI 功能
在最近的Google AI 更新中,谷歌和 Alphabet 首席执行官 Sundar Pichai 介绍了一项名为 Bard 的新型实验性对话 AI 服务,该服务由LaMDA提供支持。谷歌宣布,该服务已向可信测试人员开放,并将在未来几周内向公众开放。
Bard 使用来自网络的信息来提供高质量的响应。与 ChatGPT 模型不同,Bard 是一项将世界知识与力量、智慧和创造力相结合的服务。最初,Google 会发布一个轻量级的 LaMDA 模型版本,随着时间的推移,它将推出更强大的语言模型。
语言、视觉和生成模型
根据谷歌研究的最新报告,他们在语言技术、计算机视觉和生成模型方面取得了进步。
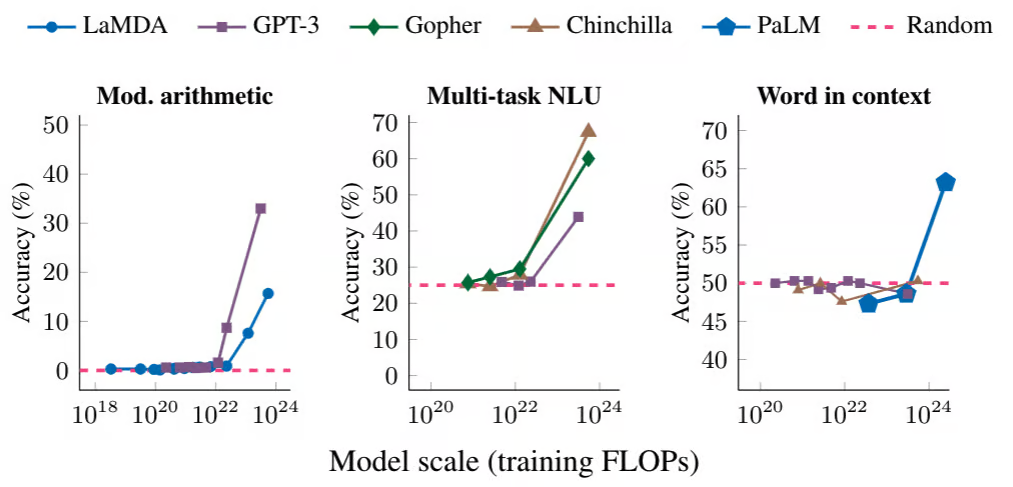
图片来自 Google AI
- 大型语言模型:Pathways 语言模型(PaLM) 和LaMDA已经显示出有希望的结果,并且在未来,您可以期待更好的语言模型,可用于对话式 AI 和其他自然语言处理任务。
- 计算机视觉:MaxViT(多轴视觉变换器)、Pix2Seq(用于对象检测的语言建模框架)以及使用大运动帧插值的 2D 到 3D 成像的发展。
- 图像生成:先进的照片级逼真图像生成模型:Imagen(扩散模型)和Parti(自回归变压器架构)。两者均使用文本输入来生成图像像素。
- 视频生成:去年,Google AI 研究了Imagen Video和Phenaki。Imagen Video 使用级联扩散模型生成高分辨率视频,而 Phenaki 使用开放域文本描述生成可变长度视频。
通过学习我们的Python 深度学习技能课程,开启您的深度学习 (AI) 职业生涯。该技能课程包含四门课程,可将您的机器学习技能提升到新的水平。
多模态模型
大多数 ML 模型专注于单一模式的数据(文本分类、图像分割或语音识别)。但由于 DALL-E 2 和 Stable Diffusion,公司现在专注于多模式模型,以实现最先进的结果。
Google AI 通过将数据传递到特定于模态的处理层并通过瓶颈层混合来自不同模态的特征,实现了多模态。组合模态也可以提高单模态任务的性能。
以下是 Google AI 在多模式模型开发方面的一些最新研究进展:
- 锁定图像调整(LiT) 为现有的预训练图像模型添加了语言理解。
- PaLI可以用 100 多种语言执行许多任务,例如视觉问答、图像字幕、对象检测并将其翻译成另一种语言、图像分类等。
- VDTTS视觉驱动的文本转语音模型,采用演员的文本和原始视频帧并生成语音输出以与原始视频相匹配,同时保持时间和情感。
- Look and Talk是一种多模式技术,它使用视频和音频作为输入,使与 Google 助理的对话更加自然。该模型会学习多种视觉和音频线索,以更准确地判断用户是否正在与 Google 助理交谈。
- 4D-Net结合了来自自动驾驶汽车的 3-D 点云数据,并将其与其他感官数据相结合,以更好地了解环境和物体,并做出更好的决策。
我们可以假设,在未来,你会看到 Google 生态系统采用这些模型来增加用户参与度并开发新产品。
人工智能与数据科学
现代人工智能由数据科学、算法和数据工程驱动。要创造像 ChatGPT 和 LaMDA 这样的尖端技术,我们必须从基础开始,了解如何处理数据并应用各种自然语言处理和强化学习技术,学习深度学习算法和转换器以及模型优化。
通过完成Python职业轨迹中的数据科学家来开始您的数据科学职业生涯。它将教您成为专业数据科学家的基本技能。

作者图片
那么,让我们来回答这个显而易见的问题。人工智能会取代数据科学家、分析师或工程师吗?答案很简单:“不会”。也许在遥远的未来会这样,但即便如此,我们也会从事不同的工作,从事更具创造性和决策性的工作。随着人工智能的发展,我们也将成长。
GitHub Copilot、DALL-E 2、ChatGPT 和其他尖端技术将为我们提供帮助。它们将使我们更加高效。
前特斯拉和 OpenAI 人工智能总监 Andrej Karpathy 表示:
“ Copilot 极大地加快了我的编码速度,很难想象回到“手动编码”的时代。仍在学习如何使用它,但它已经编写了我约 80% 的代码,准确率约为 80%。我甚至不是真的编码,而是提示和编辑。 ” – Twitter
这表明许多懂技术的人会利用技术来提高编程、逻辑、数据分析和决策的能力。
数据科学家如何使用人工智能?
- 在保护用户隐私的同时生成真实数据。
- 编写优雅、高效的代码。
- 制作产品原型。
- 使用提示执行更好的数据分析。
- 使用自然语言生成复杂的 SQL 查询。
- 为非技术利益相关者创建更好的报告。
- 执行复杂的统计分析并给出解释。
- 学习新的编程语言、技能、框架和概念。
- 使用 AI 驱动的 AutoML 和模型优化工具来构建最先进的 ML 解决方案。
- 构建自动化脚本以节省时间并避免错误。
人工智能进步的新时代
微软与 OpenAI 合作,将 ChatGPT 集成到新的 Bing 搜索引擎中,后者被称为网络的副驾驶。随着这一声明的发布,一场争夺技术霸权的新竞赛已经开始。
微软计划将 ChatGPT 和其他 GPT 模型整合到其生态系统中。它将改变一切,因为用户甚至不必离开应用程序。他们只需与机器人聊天即可进行搜索、添加内容、编辑内容并提出想法。
在巴黎活动上,谷歌推出了自己的 ChatGPT 版本 Bard。它由轻量级LaMDA提供支持。Bard 与微软的 Web 版 Copilot 非常相似;它也集成到谷歌的搜索引擎中并提供类似的功能。
人工智能进步的弊端
- 像 GPT 这样的大型语言模型将来可用于虚假宣传活动 – openai.com。它有可能造成身体和情感伤害。
- 使用人工智能生成的内容经过 SEO 优化,更难检测。学生和专业人士使用它来创作原创作品,而无需学习或理解概念。在OpenAI API文档中了解有关教育相关风险和机遇的更多信息。
- 版权问题确实存在。这些模型是根据网上的文本进行训练的,其中一些是受保护的财产。你不能仅仅为了证明人工智能的进步而窃取他人的成果。
- 有时,人工智能会给出事实上错误的答案。如果这些模型在执法部门实施,这可能会在未来造成巨大的问题。
这些问题将得到解决,我们将看到规范人工智能使用的新立法。学校和内容巨头已经开始实施人工智能生成内容政策。
那么,我们能做些什么呢?我们可以开始了解这些新技术,并开始合乎道德地使用它们。

