
本文最后由 Demo Marco 更新于 2024-07-31. 如有资源已失效,请留言反馈,将会及时处理。 【推荐:不翻墙访问被墙网站方法 | 自用高速专线机场 | 高速CN2线路 | 高质量家宽住宅IP】
Search Engines 什么是搜索引擎?
搜索引擎是一种复杂的软件系统,它可以搜索网络以查找可回答用户搜索查询的网页。搜索结果 (SERP) 按重要性和与用户所寻找内容的相关性排序显示。
现代搜索引擎的搜索结果包含不同类型的内容,包括文章、视频、图片、论坛帖子和社交媒体帖子。
最受欢迎的搜索引擎是谷歌,市场份额超过 90%,其次是 Bing、DuckDuckGo 等。
搜索引擎如何工作
搜索引擎的工作原理是使用网络爬虫程序抓取公开可用的页面。网络爬虫程序(又称蜘蛛或机器人)是一种特殊的程序,它抓取网络以查找新页面或现有页面的更新,并将此信息添加到搜索索引中。
该过程分为三个主要阶段:
- 第一阶段是发现信息的过程。
- 第二阶段是组织信息。
- 第三阶段是决定在搜索查询的结果中显示哪些页面以及以什么顺序显示。
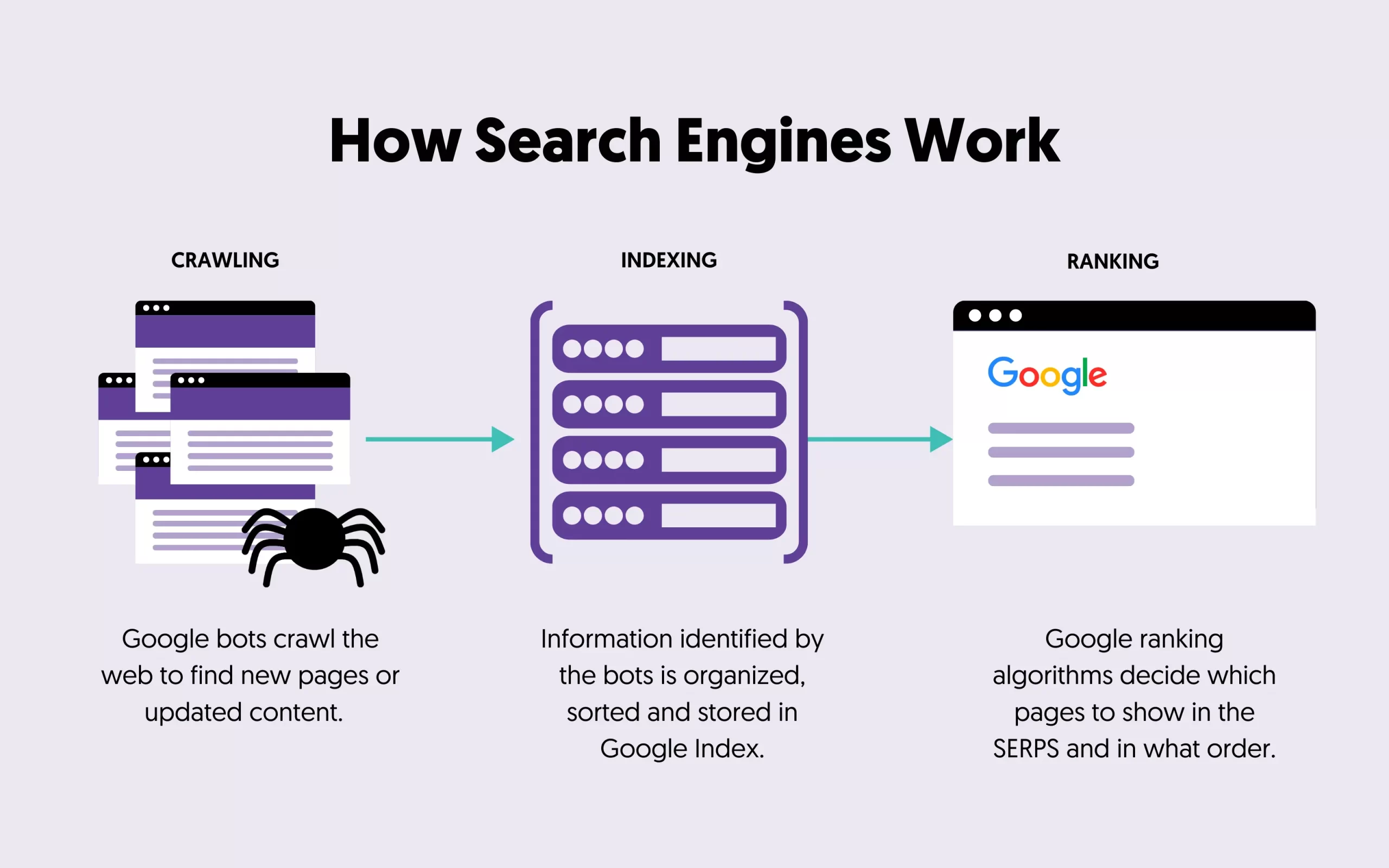
1.爬行
在抓取过程中,搜索引擎的目标是查找互联网上公开的信息。这包括新内容或对现有内容的更新。它们使用一系列称为抓取程序的软件程序来实现这些目标。
为了简化复杂的过程,您只需知道爬虫的工作是扫描互联网并找到托管网站的服务器(也称为网络服务器)。
他们创建了所有网络服务器以及每台服务器托管的网站数量的列表。
他们访问每个网站并使用不同的技术来找出有多少页面以及每页的内容类型(文本、图像、视频等)。
当访问网页时,他们还会点击任何链接(指向网站内的页面或外部网站)来发现更多页面。
他们不断地这样做,并跟踪网站所做的更改,以便知道何时添加或删除新页面、何时更新链接等。
如果您考虑到当今互联网上有超过 130 万亿个独立页面,您可以想象这是一项艰巨的工作。
为什么要关心爬行过程?
在为搜索引擎优化您的网站时,您首先要考虑的是确保它们能够正确访问它,否则,如果他们无法“读取”您的网站,您就不应该对高排名或搜索引擎流量抱有太大的期望。
如上所述,爬虫有很多工作要做,您应该尝试让它们的工作更轻松。
需要做很多事情来确保爬虫程序能够以最快的方式顺利发现并访问您的网站。
- 使用Robots.txt指定您不希望抓取工具访问的网站页面。例如,管理页面或后端页面以及您不希望在互联网上公开的其他页面。
- Google 和 Bing 等大型搜索引擎拥有一些工具(又称网站管理员工具),您可以使用它们向他们提供有关您的网站的更多信息(页面数量、结构等),这样他们就不必自己寻找。
- 使用XML 站点地图列出您网站的所有重要页面,以便爬虫程序知道要监视哪些页面的变化。
- 使用“noindex”标签指示搜索引擎爬虫不要索引特定页面。
欲了解更多信息,请阅读我们的技术 SEO指南,其中包括针对抓取阶段优化您的网站的示例。
2. 索引
仅靠爬取是不足以构建搜索引擎的。爬虫识别的信息需要进行组织、排序和存储,以便搜索引擎算法能够对其进行处理,然后才能提供给最终用户。
该过程称为索引。
搜索引擎不会将页面上的所有信息都存储在其索引中,但会保留页面的创建/更新时间、页面的标题和描述、内容类型、相关关键字、传入和传出链接以及其算法所需的许多其他参数。
Google 喜欢将其索引描述为书的封底(一本非常大的书)。
为什么要关心索引过程?
这很简单,如果您的网站不在他们的索引中,它将不会出现在任何搜索中。
这也意味着搜索引擎索引的页面越多,当有人输入查询时,您出现在搜索结果中的机会就越大。
请注意,我提到了“出现在搜索结果中”这个词,这意味着在任何位置,而不一定是在顶部位置或页面上。
为了出现在 SERP(搜索引擎结果页面)的前 5 个位置,您必须使用称为搜索引擎优化(简称 SEO)的过程针对搜索引擎优化您的网站。
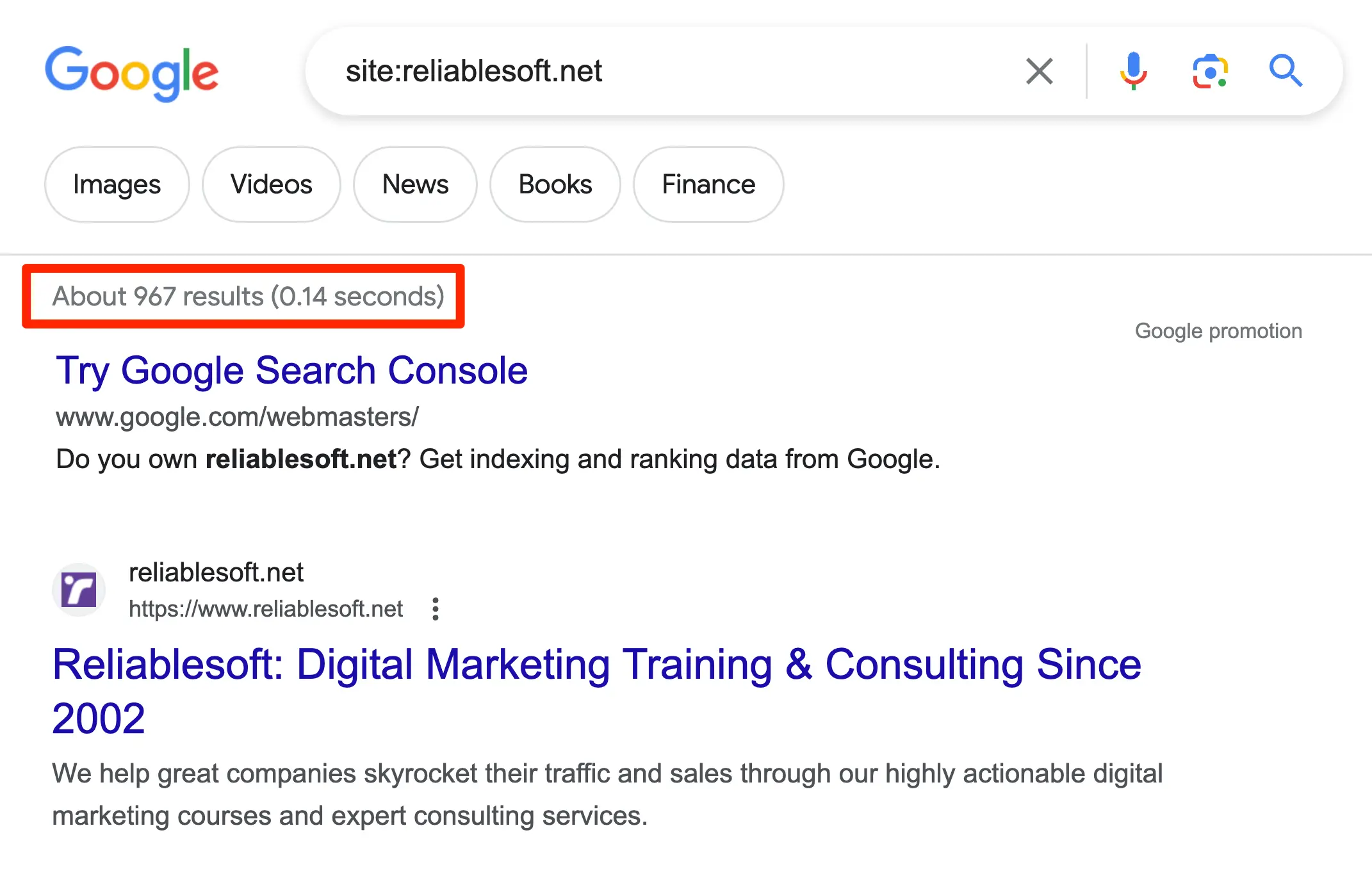
如何查找您的网站有多少页面被收录在 Google 索引中?
有两种方法可以做到这一点。
打开 Google,使用site运算符加上您的域名。例如,site:reliablesoft.net。您将发现 Google 索引中包含了多少与特定域名相关的页面。
第二种方法是创建一个免费的 Google Search Console 帐户并添加您的网站。
然后查看位于“页面” > “索引”下的“索引页面”报告。
3. 排名
该流程的第三步也是最后一步是搜索引擎决定在 SERPS 中显示哪些页面以及当有人输入查询时以什么顺序显示。这称为排名流程,通过使用搜索引擎排名算法来实现。
简单来说,这些软件使用一系列规则来决定搜索查询的最佳结果。
这些规则和决定是根据其索引中可用的信息制定的。
搜索引擎算法如何工作?
搜索引擎算法会检查多种因素和信号,以找到与用户查询最匹配的内容。这包括查看内容与用户输入的单词的相关性、页面的可用性、用户的位置、其他用户认为对特定查询有用的内容,以及许多其他因素。
值得一提的是,多年来搜索引擎排名算法已经变得非常复杂。一开始(比如 2001 年),它很简单,只需将用户的查询与页面标题进行匹配,但现在情况已不再如此。
Google 的排名算法在做出决定之前会考虑超过 255 条规则,但没有人确切知道这些规则是什么。
搜索引擎使用机器学习和人工智能根据网页内容边界内外的参数做出决策。
为了便于理解,以下是搜索引擎排名因素如何发挥作用的简化流程:
步骤 1:分析用户查询
搜索引擎的第一步是了解用户正在寻找什么样的信息。
为了做到这一点,他们将用户的查询(搜索词)分解为一系列有意义的关键词来分析。
关键词是具有特定含义和目的的词。
例如,当您输入“如何制作巧克力蛋糕”时,搜索引擎会根据“如何”这个词知道您正在寻找有关如何制作巧克力蛋糕的说明,因此返回的结果将包含带有食谱的烹饪网站。
如果您搜索“购买翻新……”,他们会从“购买”和“翻新”这两个词中知道您想购买某样东西,返回的结果将包括电子商务网站和在线商店。
机器学习帮助他们将相关的关键词关联在一起。例如,他们知道查询“如何更换灯泡”的含义与此“如何更换灯泡”的含义相同。

它们还足够聪明,能够解释拼写错误、理解复数,并从自然语言(语音搜索中的书面语言或口头语言)中提取查询的含义。
第 2 步:查找匹配的页面
第二步是查看他们的索引并确定哪些页面可以为给定的查询提供最佳答案。
对于搜索引擎和网站管理员来说,这是整个过程中非常重要的阶段。搜索引擎需要以最快的方式返回最佳结果,以便让用户满意。网站管理员希望他们的网站被收录,这样他们才能获得流量和访问量。
这也是良好的SEO 技术可以影响算法决策的阶段。
为了让您了解匹配的工作原理,以下是最关键的因素:
标题和内容相关性——页面的标题和内容与用户查询有多相关?
内容类型——如果用户要求图像,返回的结果将包含图像,而不是文本。
内容质量——内容需要全面、实用、信息丰富、公正,并涵盖故事的两个方面。
网站质量– 网站的整体质量至关重要。Google 不会显示不符合其质量标准的网站的网页。
发布日期——对于与新闻相关的查询,Google 希望显示最新的结果,因此也会考虑发布日期。
页面的受欢迎程度——这与网站流量多少无关,而是与其他网站如何看待特定页面有关。如果一个页面有大量来自其他网站的引用(反向链接),则被认为比没有链接的其他页面更受欢迎。
页面语言——页面以用户自己的语言显示,但并不总是英语。
网页速度——与加载速度慢的网站相比,加载速度快的网站(大约 2-3 秒)具有一点优势。
设备类型——使用移动设备搜索的用户将获得适合移动设备的页面。
位置– 用户在其所在地区搜索结果,例如“俄亥俄州的意大利餐厅”,将显示与其位置相关的结果。
这只是冰山一角。如前所述,Google 在其算法中使用了超过 255 个因素来确保其用户对获得的结果感到满意。
步骤 3:向用户展示结果
搜索结果通常称为搜索引擎结果页面 (SERP),以有序列表的形式呈现。SERP 的布局通常包含各种元素,例如自然列表、付费广告、精选摘要、知识图谱、丰富摘要等,具体取决于查询的性质。
例如,搜索特定新闻可能会显示最近的新闻文章,而搜索当地餐馆可能会显示附近地点的地图。
为什么要关心搜索引擎排名算法如何运作?
为了从搜索引擎获得流量,您的网站需要出现在结果第一页的顶部位置。
统计数据证明,大多数用户都会点击前 5 个结果之一(包括桌面端和移动端)。
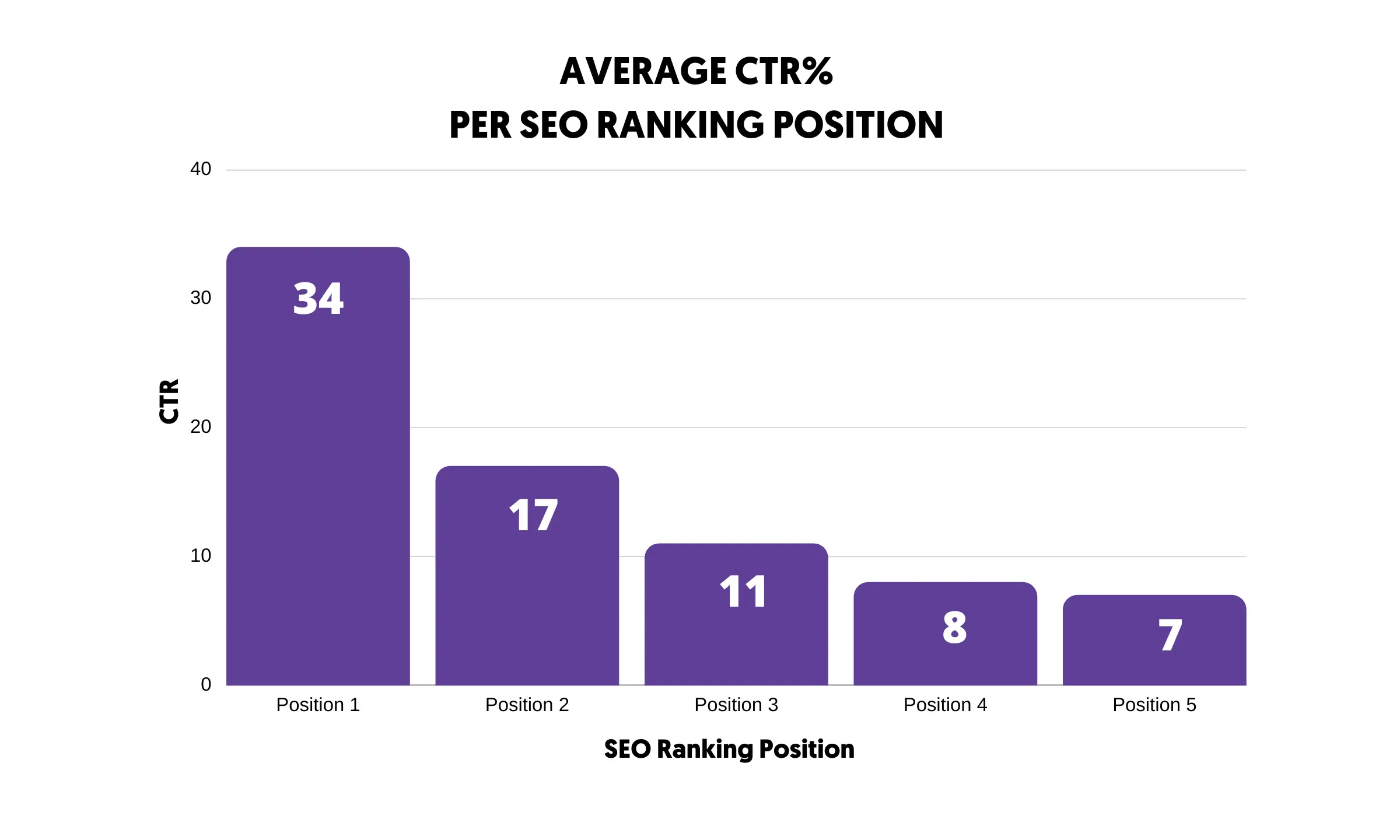
出现在结果的第二页或第三页不会给您带来任何流量。
流量只是SEO 的好处之一,一旦您的关键词排名对您业务有意义的话,附加的好处就更多了。
了解搜索引擎的工作原理可以帮助您调整您的网站并提高您的排名和流量。
结论
搜索引擎已经成为非常复杂的计算机程序。它们的界面可能很简单,但它们的工作方式和决策方式却远非简单。
该过程从抓取和索引开始。在此阶段,搜索引擎抓取工具会收集互联网上所有公开网站尽可能多的信息。
他们以搜索引擎算法可以用来做出决策并向用户返回最佳结果的格式发现、处理、分类和存储这些信息。
它们需要消化的数据量非常庞大,而且这个过程是完全自动化的。人类的干预只在设计各种算法所使用的规则的过程中进行,但即使是这一步,也正在通过人工智能的帮助逐渐被计算机取代。
作为网站管理员,您的工作是通过创建结构简单直接的网站来使他们的抓取和索引工作更容易。
一旦他们可以毫无问题地“阅读”您的网站,您就需要确保向他们提供正确的信号,以帮助他们的搜索排名算法,并在用户输入相关查询时选择您的网站(即 SEO)。
获取整体搜索引擎流量的一小部分就足以建立成功的在线业务。
参考资料01: https://www.reliablesoft.net/how-search-engines-work/






